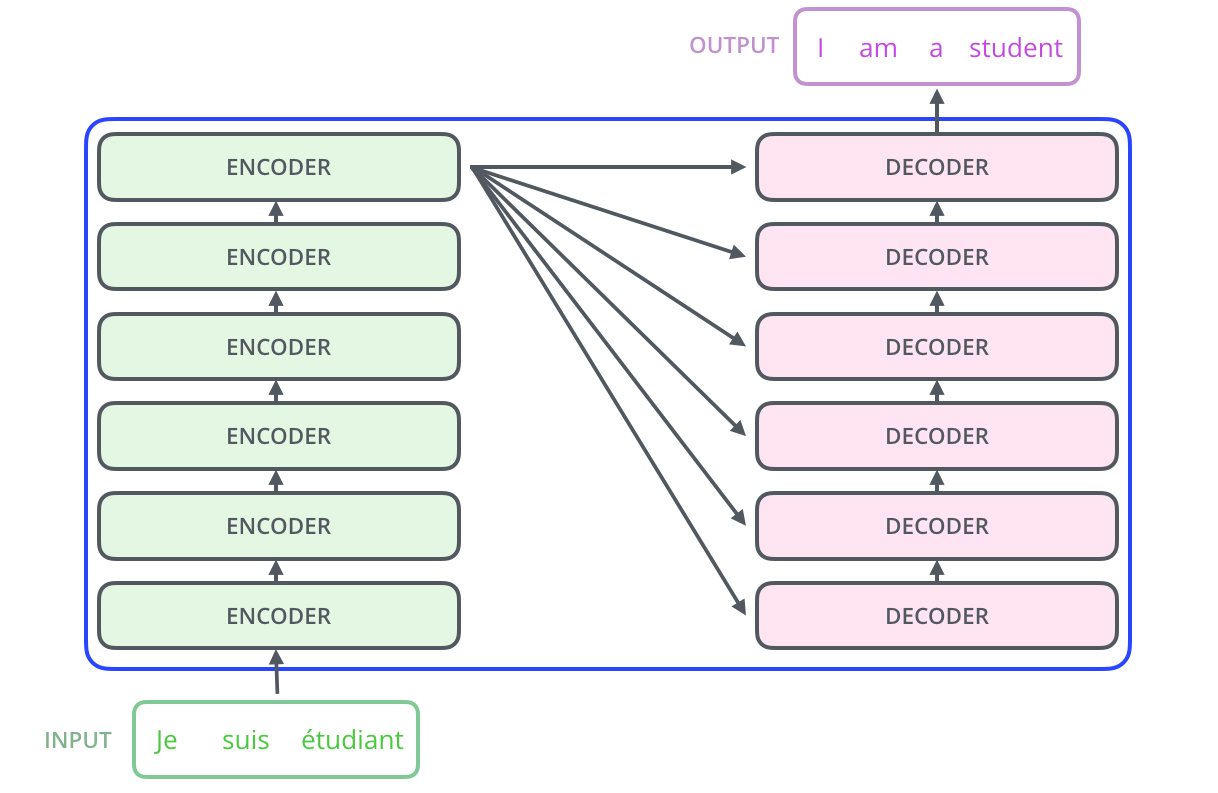
Transformer
Contents
为什么我还是无法理解transformer The Annotated Transformer
Transformer 架构定义了“信息的流动方式”:无论是训练还是推理,信息都必须经过多头注意力(MHA)和前馈网络(FFN)。
| 维度 | 训练过程 (Training) | 推理过程 (Inference) |
|---|---|---|
| 输入处理 | 全量输入(Input + Target) | 增量输入(先输入 Prompt,再逐个生成) |
| 核心阶段 | 只有 Forward(前向) 和 Backward(反向) | Prefilling (处理 Prompt) + Decoding (生成) |
| 计算模式 | 高度并行(利用矩阵乘法一次算完整个序列) | Prefilling 是并行的,Decoding 是串行的 |
| 反量化发生点 | 如果是量化训练,发生在算子计算时 | 发生在 Prefilling 和 Decoding 的每一层计算中 |
训练 = 对整个序列进行一次大规模的 Prefilling(forward 的计算方式应该和 forward 是一致的) + 反向传播(计算梯度并更新权重)。
推理 = 对输入进行一次 Prefilling(产生 KV Cache) + 循环进行多次 Decoding(消耗 KV Cache 并产生新词)。
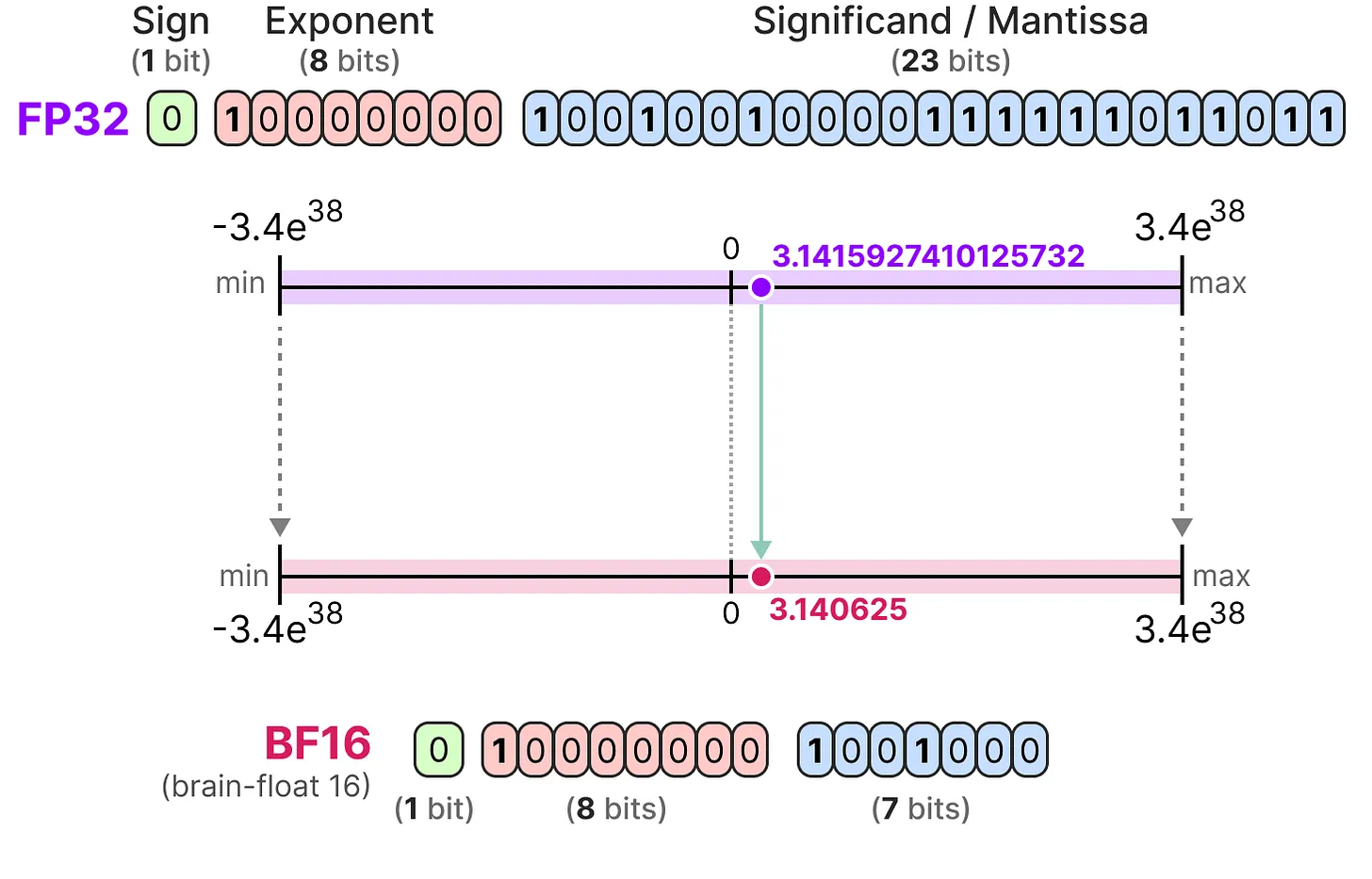
量化过程数据变化示例:
架构
An overview of some of the most popular large language transformers organized by architecture type and developers.2
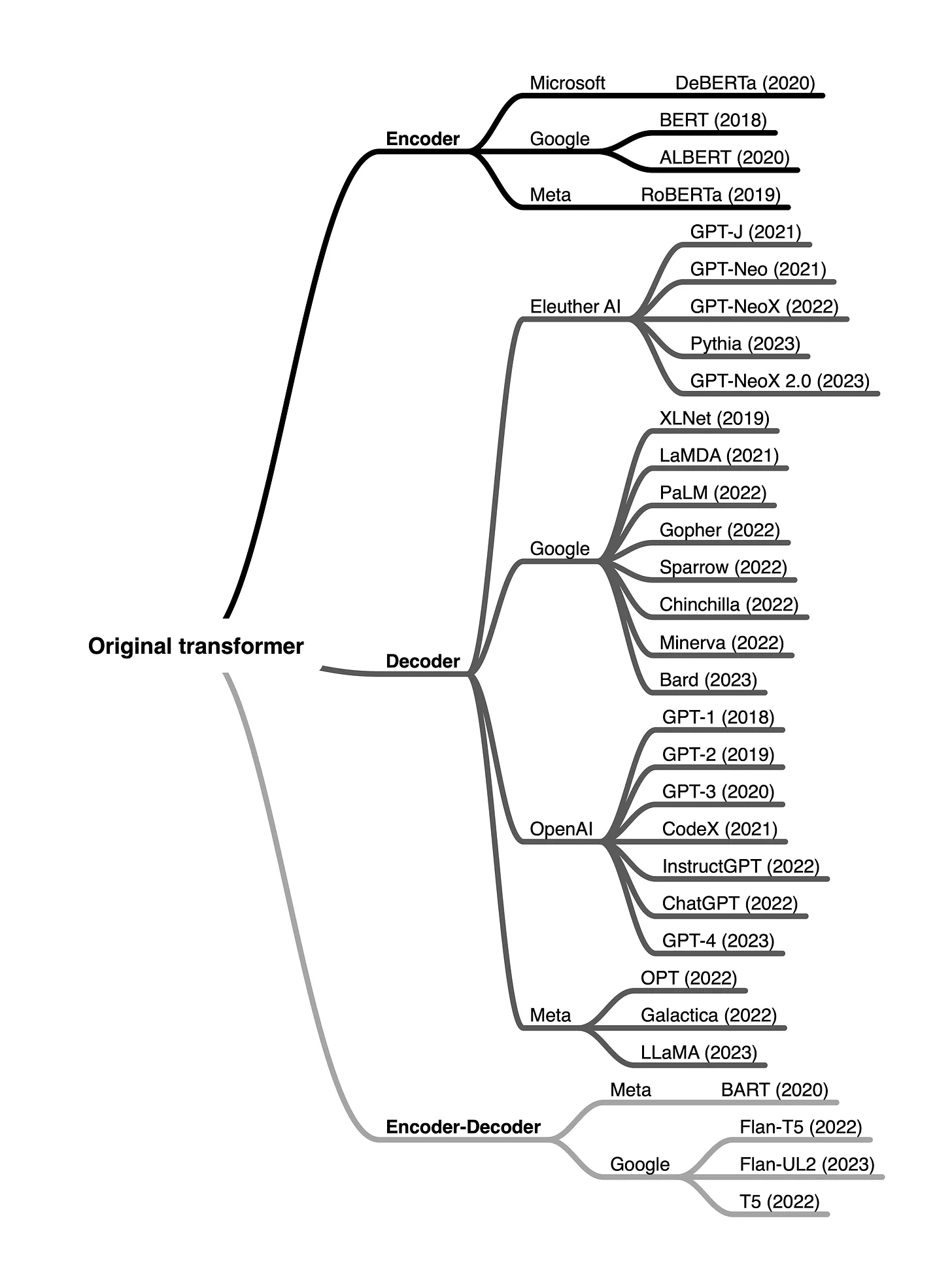
Encoder-only models
Good for tasks that require understanding of the input, such as sentence classification and named entity recognition. 3
Decoder-only models
Good for generative tasks such as text generation. 3
Encoder-Decoder models(sequence-to-sequence models)
Good for generative tasks that require an input, such as translation or summarization. 3
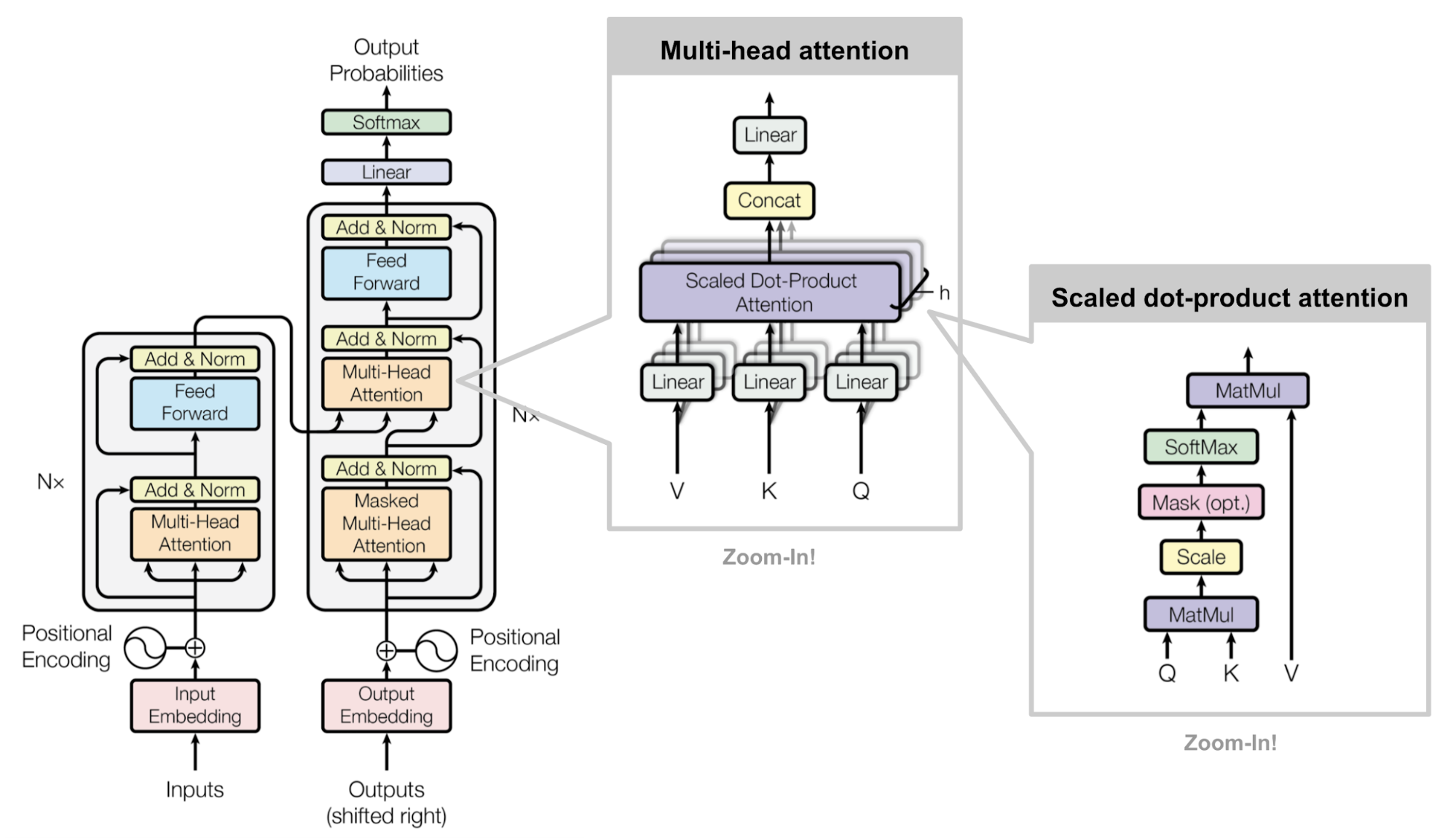
不过上图展示的 encoder 和 decoder 之间的关联展示的是逻辑上这两个组件间的数据流向,而实际应用上连接方式如下图所示