C C++ Compile
名词辨析
GNU
- GNU’s Not Unix!的递归缩写
- 一个自由的操作系统,起源于GNU计划,希望发展出一套完整的开放源代码操作系统来取代 Unix
- 基本组成包括:
- GNU编译器套装(GCC)
- GNU的C库(glibc)
- GNU核心工具组(coreutils)
GCC
- GNU Compiler Collection, GNU编译器套装,最初是为了GNU操作系统而编写的编译器。
- 有多种语言前端,可用于解析不同的编程语言、操作系统、计算机系统结构,是GNU计划的关键部分,也是GNU工具链的主要组成部分之一
- 可以编译C、C++、JAV、Fortran、Pascal、Object-C、Ada,Go等语言
gcc/g++/MinGW
- gcc: GCC中的GUN C Compiler(C 编译器)
- g++: GUN C++ Compiler(C++编译器)
- MinGW: Minimalist GNU for Windows,是将GCC编译器和GNU Binutils移植到Win32平台下的产物
但根据GCC的gcc和g++区别的说法,gcc和g++并不是编译器,它们只是一种驱动器1,它们会根据参数中要编译的文件的类型,调用对应的GUN编译器。以编译C语言为例,包含以下过程。
Step1:Call a preprocessor, like cpp.
Step2:Call an actual compiler, like cc or cc1.
Step3:Call an assembler, like as.
Step4:Call a linker, like ld
因此gcc命令只是上述后台程序的包装,根据不同的参数调用不同的程序,例如预编译程序、编译器、汇编器和链接器
gcc 与 g++ 的联系和区别
- 对于 *.c 文件,gcc 当做 c 文件看待,g++ 当做 cpp 文件看待2
虽然 gcc 和 g++ 都可以编译 *.c 文件,但是二者会以不同的语言来对待 c 文件,而 C++ 标准和 C 语言标准的语法要求是有区别的。
| |
以上代码使用 gcc 进行编译,其会看为 c 语言,编译结果为

以上代码使用 g++ 进行编译,其会看为 c++,编译结果为

由此可见,c++ 的语言要求会更高一些
- 对于 *.cpp 文件,gcc 当做cpp 文件看待,g++ 当做 cpp 文件看待
虽然二者都会以 cpp 文件来对待,但是对于调用某些标准库中现有的函数或者类对象的 c++ 程序,而单纯的 gcc 命令无法自动链接这些标准库文件,无法完成编译,需要手动链接 C++ 标准库,例如 gcc -lstdc++
C++标准与编译器,标准库的版本问题
When we search the grammar of C/C++ in cppreference, we often see prompts like “(since C++11)", “(since C++20)”.
In face, C++ 标准的完整支持需要 编译器前端 + 标准库后端 同时实现。关于这一点,我们可以从编译器工作流程来粗浅理解。
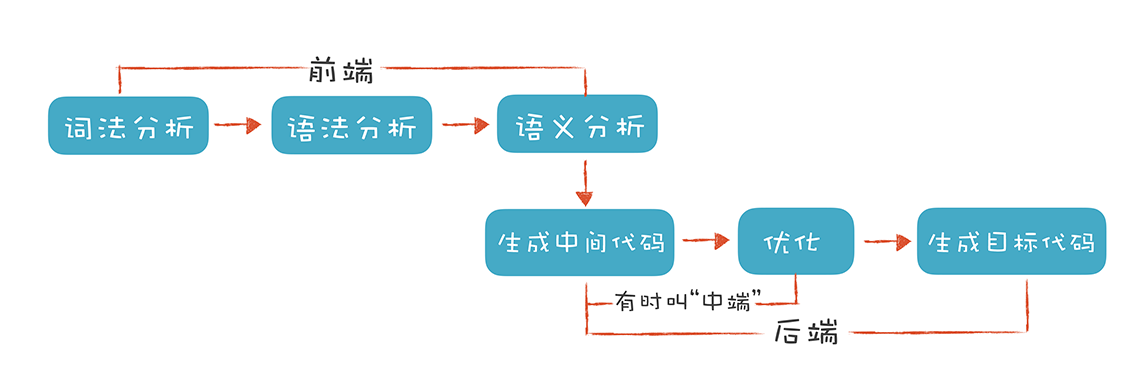
新的 C++ 标准往往会新增一些关键词,这就要求编译器需要能够识别出这是一个标准下的关键词,不过这还不足以生成最终的可执行程序,因为到目前为止也就只是能够认识出这是个关键词了,还缺乏对应的执行逻辑, 所以还需要它的实现代码,这部分就是标准库所提供的内容。
| 组件 | 职责 | 版本示例 |
|---|---|---|
| 编译器 | 负责解析语法(如 if constexpr、结构化绑定)和生成代码 | GCC 11、GCC 12 |
| 标准库 | 实现标准头文件中的功能(如 | libstdc++ 11 |
简单来说,标准库相较于编译器对于 C++ 标准的支持是要滞后一些的。举个简单的例子,C++20 features are available since GCC 8 3,但是 gcc-12 还存在 improved experimental C++20 support 4。
So there is a question that how can we determine if the current environment supports these features.
- 判断编译器是否支持该语法
C++ Standards Support in GCC 给定了不同标准的不同特性在不同版本 gcc 下的可用性,同时我们可以在 “https://gcc.gnu.org/gcc-
即我们先确定需要使用的特性在当前 gcc 下是否支持,如果支持,在编译时通过 -std=c++<edition> 来指定使用这一标准,从而完成语法层面的支持(此选项不一定需要必须添加,因为不同版本的 gcc 都会有默认指定的标准,例如 “C++17 mode is the default since GCC 11” 5)。
- 判断标准库是否实现该功能
C++ Standards Support in libstdc++ 给定了不同标准的不同特性在不同版本 libstdc++ 下的可用性。
最后我们以 std::make_shared<int32_t[]>(10) 这个需要对 array 使用 make_shared 的需求进行编译器和标准库的版本需求分析。
首先,我们可以在 cppreference | std::make_shared, std::make_shared_for_overwrite 查询到这一 API 是 C++20 开始支持的。目前的 gcc 版本是 11.4.0,需要判断当前是否支持此功能。
从 C++20 Support in GCC 查看 C++20 对于 gcc 的要求,发现 “C++20 features are available since GCC 8“,所以当前的 gcc-11 显然是没有问题的。
然后查询 C++20 Support in libstdc++,发现实现 “Extending make_shared to Support Arrays” 这个 feature 的最低版本库编号是 12.1,而目前是 11(libstdc++ 的版本与 GCC 主版本号一致),所以当前编译环境无法支持此功能。
同时补充一点,我们可以在两个文档中看到很多宏,用于标识编译器目前支持的一些功能信息,我们可以通过 g++ -dM -E -x c++ /dev/null(-dM: 预处理结束后输出所有已定义的宏,-d 表示调试选项,M 表示输出宏) 获取到完整的宏列表。
GCC 头文件和标准库分布解析
初看 /usr 下的文件分布,会感觉一头雾水,分布的比较混乱,并且还存在各种软连接。实际上,这种复杂的目录设计是为了应对多版本共存,多架构支持和灵活切换这三大核心需求(灵活切换的需求是通过软链接满足的,目录设计上并没有体现)。
- 库文件分布:
| 需求 | 目录设计示例 | 实现方式 |
|---|---|---|
| 多版本共存 | /usr/lib/gcc/x86_64-linux-gnu/{9,11,12}/ | 版本号嵌入路径,update-alternatives 管理默认版本(软链接) |
| 多架构支持 | /usr/lib/{x86_64,aarch64}-linux-gnu/ | 架构名嵌入路径,动态加载器(ld.so)自动匹配(原始文件) |
- 头文件分布:
| 需求 | 目录设计示例 | 内容性质 |
|---|---|---|
| 多版本共存 | /usr/include/c++/{9,11,12}/ | 架构无关的通用 C++ 标准库头文件 |
| 多架构支持 | /usr/include/{x86_64,aarch64}-linux-gnu/ | 架构特定的底层实现和定义 |
需要注意的是,标准库和头文件面对多版本共存这一需求时的目录设计是不同的,标准库的目录在包含版本号的同时也包含了架构信息,头文件将架构无关和相关的文件进行了分离,因此目录只包含了版本号。
与 C++ 不同,C 语言标准库在头文件和库的分布上通常不显式设计版本隔离。对于头文件,架构无关的采用 /usr/include,架构相关的采用 /usr/include/x86_64-linux-gnu;对于库文件,采用 /lib/x86_64-linux-gnu/libc.so.6(不同机器版本号可能不同)。
MSVC
- Microsoft Visual C++,is a compiler for the C, C++ and C++/CX programming languages by Microsoft
LLVM
LLVM最初是指Low Level Virtual Machine,是类似但不同于jvm的一种虚拟机,现在来说,有很多理解方式,可以说LLVM是编译器的工具链的集合,Clang是使用LLVM的编译器;又或者说LLVM是一个优秀的编译器框架,它也采用经典的三段式设计。
根据编译原理可以了解到,在GCC中前端和后端的分界并非明显,这就导致出现下面的情况,一种语言的前端对对应多个后端

而LLVM架构通过引入LLVM IR(Intermediate Representation)解决了这一问题,形成的LLVM架构如下图所示,在这种结构下,新的编程语言开发只需要设计一个新的前端,新型芯片的开发只需要设计一个新的后端。
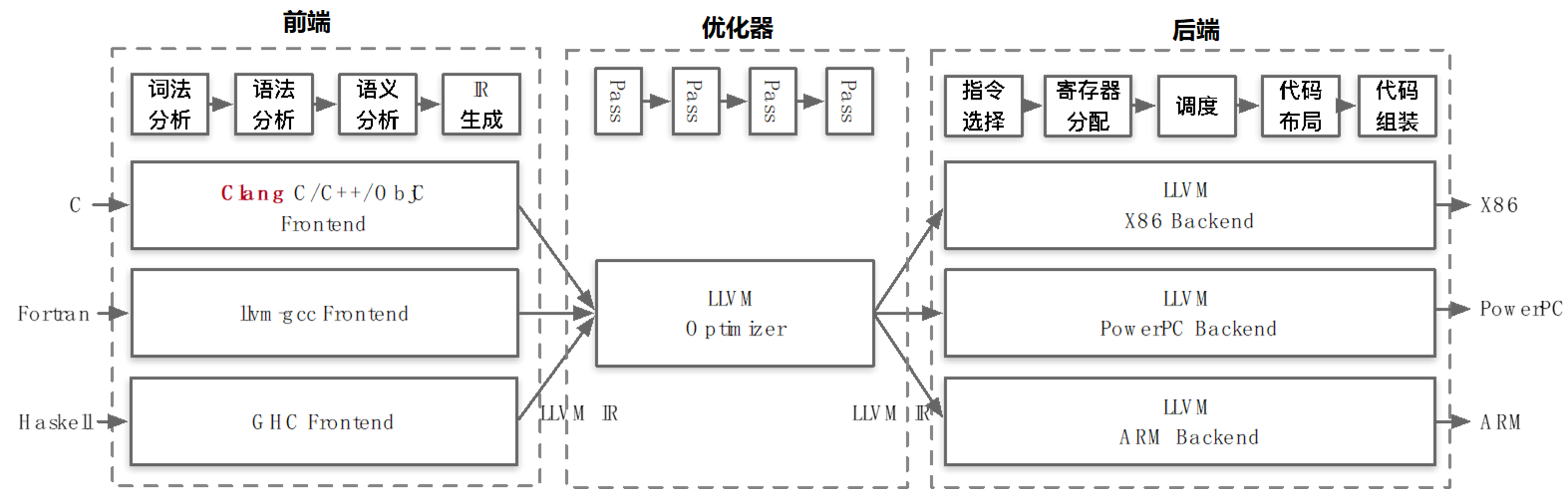
要注意区分“编译,汇编,链接”和“前端,中端,后端”之间的区别和联系,前者描述的是编译的不同阶段,后者描述的是编译器架构的分层结构,当然这并不是说它们之间并没有联系,前端,中端和后端会分别完成编译,汇编和链接中的部分工作,最终形成可执行文件。
clang/clang++
是LLVM项目中的一个子项目,是基于LLVM架构的轻量级编译器,创造目的是为了替代GCC,提供更快的编译速度。
似乎与 gcc/g++ 类似,也属于一种驱动器(Driver)。(此说法来自 ChatGPT,因此还有待查证,在实际测试中 clang 只会利用到 clang -cc1 进行处理,还没有看到其调用其他程序)
Make
make工具可以看成是一个智能的批处理工具,它本身并没有编译和链接的功能,而是用类似于批处理的方式—通过调用makefile文件中用户指定的命令利用gcc(或g++)来进行编译和链接。当程序只有一个源文件时,可以直接使用用gcc(或g++)命令进行编译。但当程序包含多个源文件时,逐文件去编译,编译顺序可能出现混乱同时工作量较大
CMake
makefile在一些简单的工程中可以人工书写,但当工程较大时,手写makefile较为麻烦,同时更换平台需要修改makefile,cmake工具可以根据CMakeLists.txt文件去生成makefile,过程如下图所示
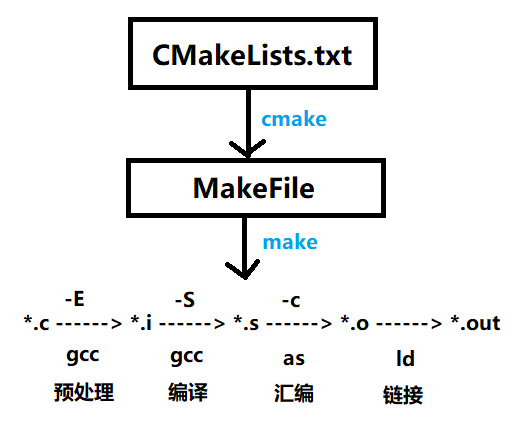
More details can be found in CMake Knowledges Summary
参考
Ninja
Ninja 同 Make 一样都属于构建系统,最大的特点是构建速度快。同时其也可与CMake结合使用,使用流程如下图所示:

编译方式
- AOT(Ahead of time):提前编译,代码程序在执行前全部被翻译为机器码
- JIT(Just in time):即时编译,代码程序边翻译边运行
虽然说是编译方式,实质上指的还是程序的两种运行方式,即静态编译和动态解释。前者的典型代表是 C/C++ 程序,后者代表是 JavaScript、Python 等动态解释的程序。
不过需要注意的是,程序运行方式和编程语言本身并没有强关联,例如 Java 和 Python 也可以编译为中间字节码,之后就可以直接执行字节码,这也就属于 AOT 的方式了(当然,如果严格从定义上来说,中间字节码并不等同于机器码,不过通常区分是否为 AOT 的标准就是看代码在执行之前是否需要编译)。
编译流程
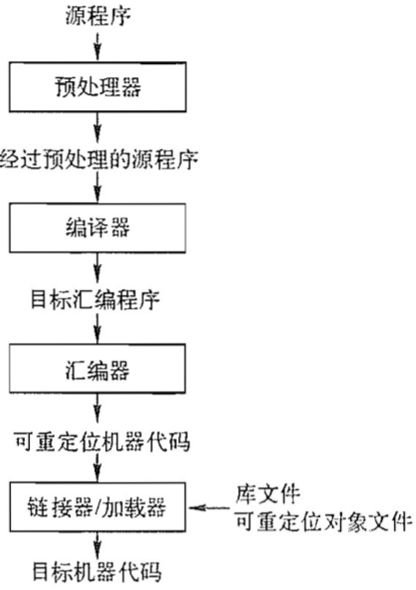
以gcc为例 集成开发环境一键式完成的过程,将编译和链接进行合并,此过程称为构建(Build)
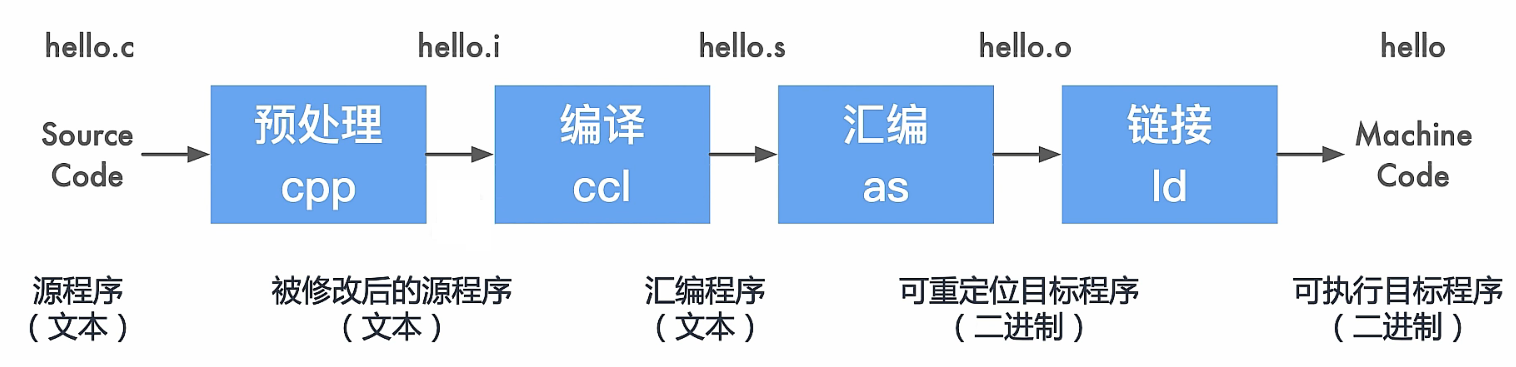
关于编译选项的详细解释见 GCC online documentation -> GCC Manual -> GCC Command Options
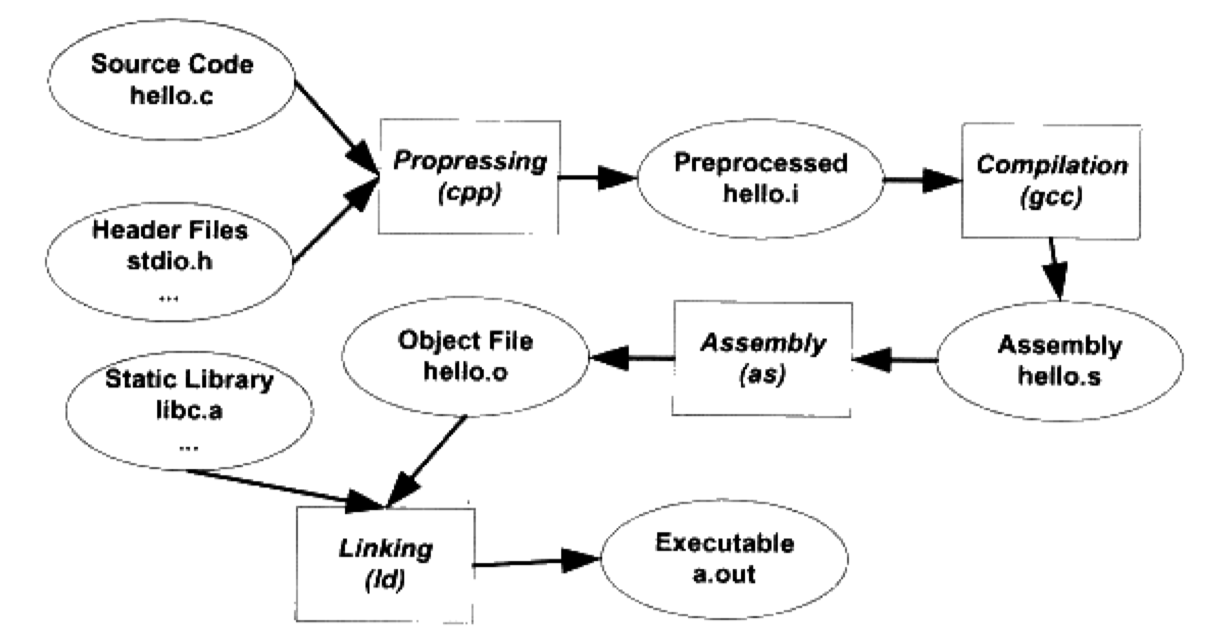
实际上,对于实际流程而言,在链接之后还需要进行加载,将可执行文件放置到内存以执行,完整流程如下图所示
预处理(预编译)
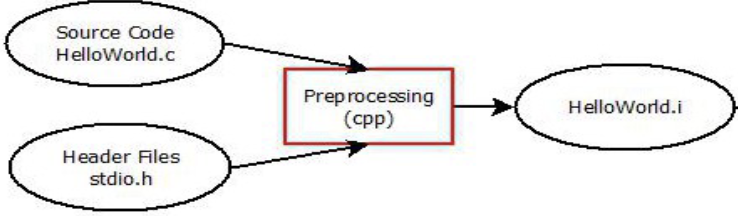
- 头文件包含: 处理
#include- 条件编译: 处理
#if,#else,#endif等等条件编译指令- 宏替换: 处理#define, 将宏展开
- 删除注释
| |
若要检查宏定义或头文件包含是否正确时,可查看预编译后的文件
使用file命令可以查看预处理后文件类型如下:
main.i: C source, ASCII text
编译

词法,语法,语义分析,生成汇编代码
| |
使用file命令可以查看编译后文件类型如下:
main.s: assembler source, ASCII text
汇编

将汇编语言转化为相应的机器语言(二进制目标文件)
| |
使用file命令可以查看汇编后文件类型如下:
main.o: ELF 64-bit LSB relocatable, x86-64, version 1 (SYSV), not stripped
注:关于"not stripped",和strip命令有关,表示没有Removes symbols and sections of files.
链接
Due to the complexity of the process of program linking, we will introduct it in a separate article.
加载
加载器(loader)把所有的可执行文件放到内存中执行
对于静态链接生成的可执行文件,shell 首先会通过 execve 启动程序,然后由操作系统内核将执行所需的数据加载到内存中。
对于动态链接生成可执行文件,似乎链接和加载是分界并非很明确的两个环节,从 man ld-linux 的结果来看:
ld.so, ld-linux.so - dynamic linker/loader
编译类型
- Ahead-of-time (AOT) compilation
graph LR
A(C Source Code) -- compiler --> B(machine code)graph LR
A(C Source Code) -- compiler --> B(machine code)- Just-in-time (JIT) compilation
graph LR
A(Java Source Code) -- javac compiler --> B(bytecode)
B -- JVM interpreter --> D(machine code)
B -- JIT compiler --> D(machine code)graph LR
A(Java Source Code) -- javac compiler --> B(bytecode)
B -- JVM interpreter --> D(machine code)
B -- JIT compiler --> D(machine code)即时编译综合运用了编译和解释,首先使用 javac 编译器生成中间形式字节码,然后使用解释器逐条翻译字节码为机器码执行。即时编译器有选择性地将字节码编译为机器码,相较于纯编译能够减少编译时间,相较于纯解释能够提升执行速度。
采用 JIT 编译的 Java 语言的详细编译流程如下图 6 所示
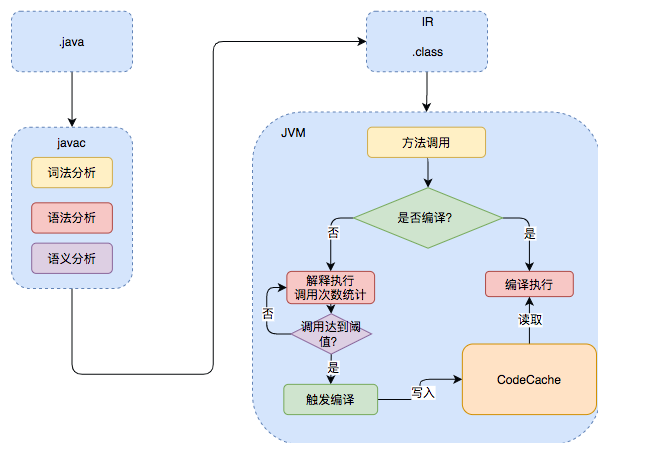
- 除此之外,还有纯解释型的执行方式
graph LR
A(Python Source Code) -- Interpreter --> B(machine code)graph LR
A(Python Source Code) -- Interpreter --> B(machine code)