GPU Structure and Programing
Todo
- L2 cache gpgpu-sim 源码分析
- Bank conflict 的题目分析
- warp occupancy 概念和计算
- 由broadcast式访问global memory引申的对于constant memory的理解和使用
- 并行化+访存优化,并行化中有一个branch divergence的问题
- 查找 DRAM burst突发传送官方文档说明
- 发现矩阵乘法是一个结合各种并行算法以及CUDA硬件架构知识的好的入手点,create一门课程 “从矩阵乘法入门并行计算-CUDA版”
- 需要验证如果shared memory中的元素大小和bank大小不一致时,访问其中更小的数据是否会造成bank conflict。需要借助nvprof,但是nvprof在选择检测bank事件时无法正常工作
- CUDA C只是对标准C进行了语言级的扩展,通过增加一些修饰符使编译器可以确定哪些代码在主机上运行,哪些代码在设备上运行
- GPU计算的应用前景很大程度上取决于能否从问题中发掘出大规模并行性
宏观视角
高性能计算的第一性原理:访存优化。所有的努力(优化硬件设计,优化算法)都是在试图解决内存墙。
访存优化3大关键:
- 一是减少数据搬运
- 二是减少数据访存延时
- 三是保证负载均衡
GPU中的并行算法设计:设计block和thread的workload,搞清楚一个block负责哪部分的计算,一个thread要负责哪部分的计算。而设计的原则就是尽可能地减少访存,提高数据的复用概率,然后让所有的处理器都满负荷地进行工作,不能浪费。
SIMD & SIMT
涉及到AVX指令,正在尝试 说明两种方式的区别
The two most important things about SIMD and SIMT are:
- How is the SIMT to implement ?
- How is the SIMD to calculate ?
GPU从整体上来说是SIMT,但是到Warp层次后实际就是SIMD了
Kernel hardware mapping
kernel function -> GPU block -> SM(one block can only be executed by one SM, but one SM can execute multiple blocks)
这里有一个疑问,一个SM可以执行多个block,多个block的执行是并发的还是可以并行的,换个角度来说就是正在执行的warp是同属于一个block的,还是可以隶属于多个block
关于此问题,还尚未找到官方资料中给出的证据,暂且认为SM上执行的warp可能属于不同block,也就是可以理解为开始执行kernel函数后,grid中的多个block被分配到某一个SM上,然后在SM的视角下就不再有block的概念,它所能看到的就是一些warp,通过warp scheduler来对warp进行调度,并且认为block一开始被分配到某个SM后不会在执行过程中去更换SM,直到执行完毕。
这种理解方式有一定的合理性,原因在于grid,block,warp本身就是为programmer所提供的逻辑概念,对于硬件来说,它能看到的不过是一些thread,它调度的也是thread。但是对于人来说,thread这一调度单位太细,很难实现对具体问题的抽象,所以才提供了更高一级的概念,即grid,block和warp。从这一角度来看,一个SM在同一时间能调度多个block就是合理的。
thread -> SP
main time consuming:
- kernel function startup
- thread block switch
About the mapping relationship between block and SM is that one block must map to one SM,but multiple blocks maybe map to the same SM. Their relationship is shown as the following figure
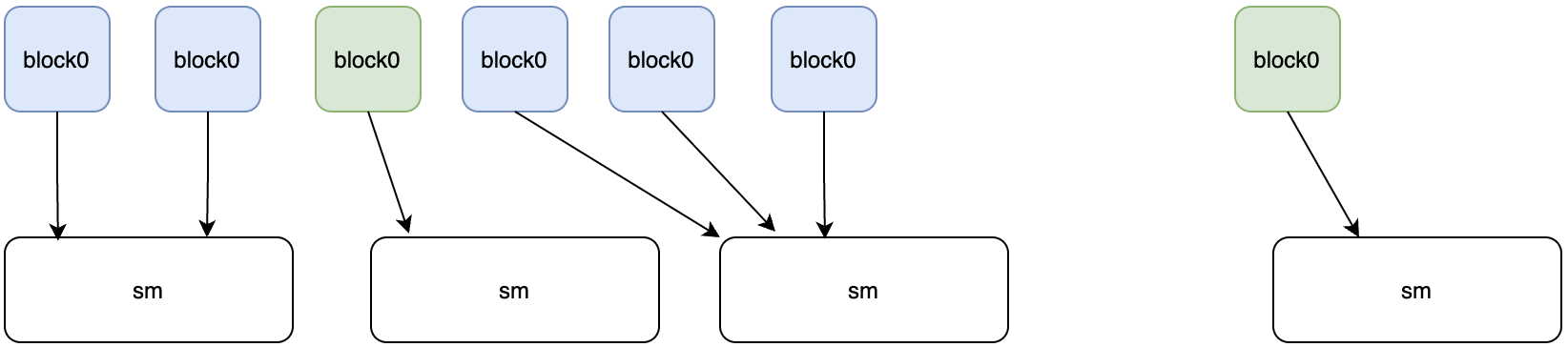
Now, we can put out perspective within am SM and assume that multiple blocks were mapped to this SM which is means that the warps which are running on this SM maybe belong to differenct blocks. According to the following picture, we can learn about that there is a shared memory in every SM, so if it means that different blocks can access the same shared memory?
But we also know the shared memory is the private resource for one block, why there is a conflict?
Actually, 当一个SM上运行多个block时,SM中的共享内存会被划分并分配给不同的block。每个block只能访问它自己被分配的那部分共享内存,它无法访问其他block的共享内存。
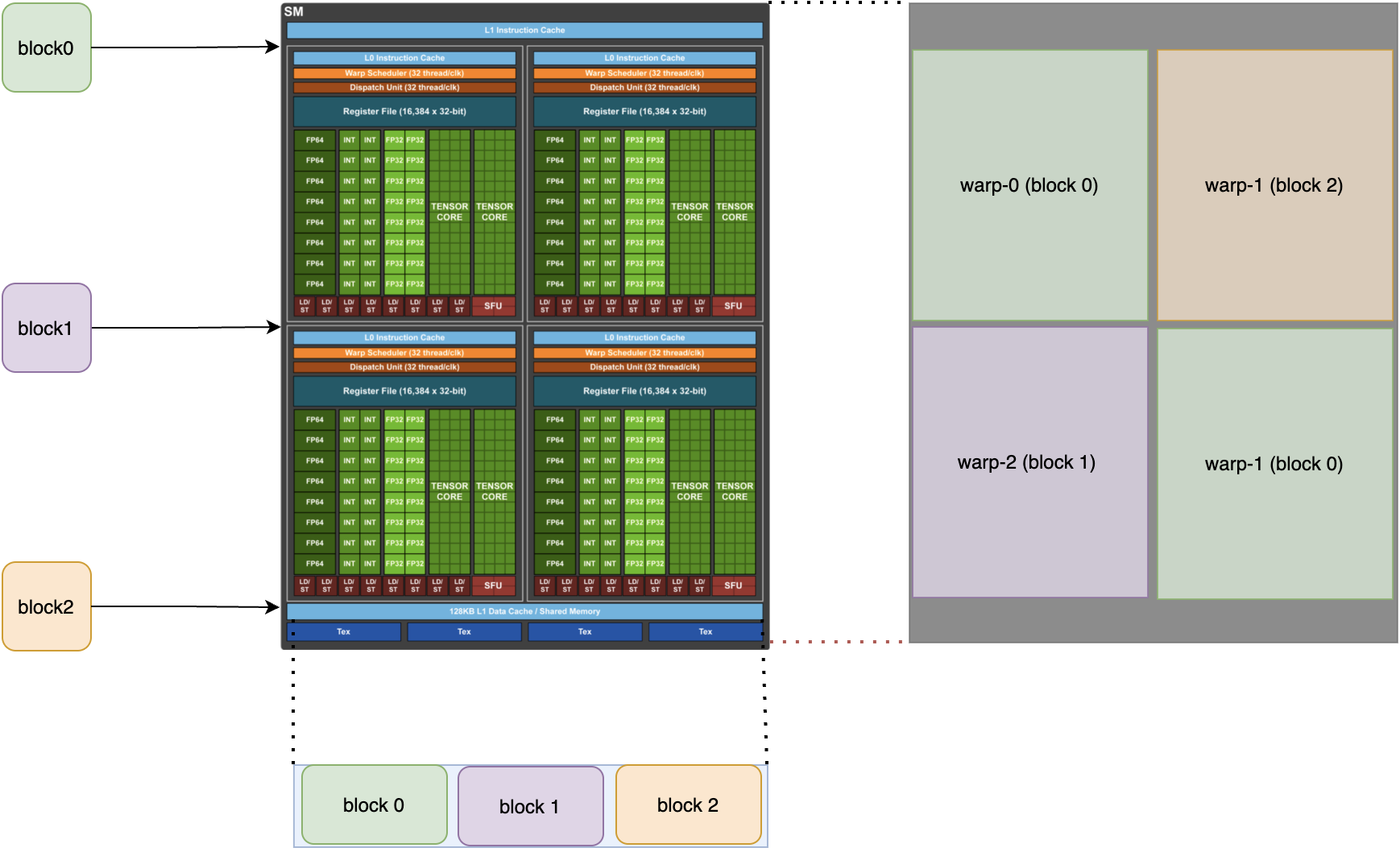
Hardware structure
Grid、Block are login concepts, they are created by CUDA for programmers. According to the real physical level, every SM in GPU will excute multiple blocks, and it will divides block into multiple warps. The basic execution unit of SM is warp.
In fact, the amazing computing capility of GPU comes from multiple thread. But we couldn’t just use thread this only one concept to program since that it is difficult to describe the job or we can say organize them.
So, CUDA introduce the concept of Grid and Block which are logic concepts, they are created by CUDA for programmers. In fact, we we can see them as a organization structure.
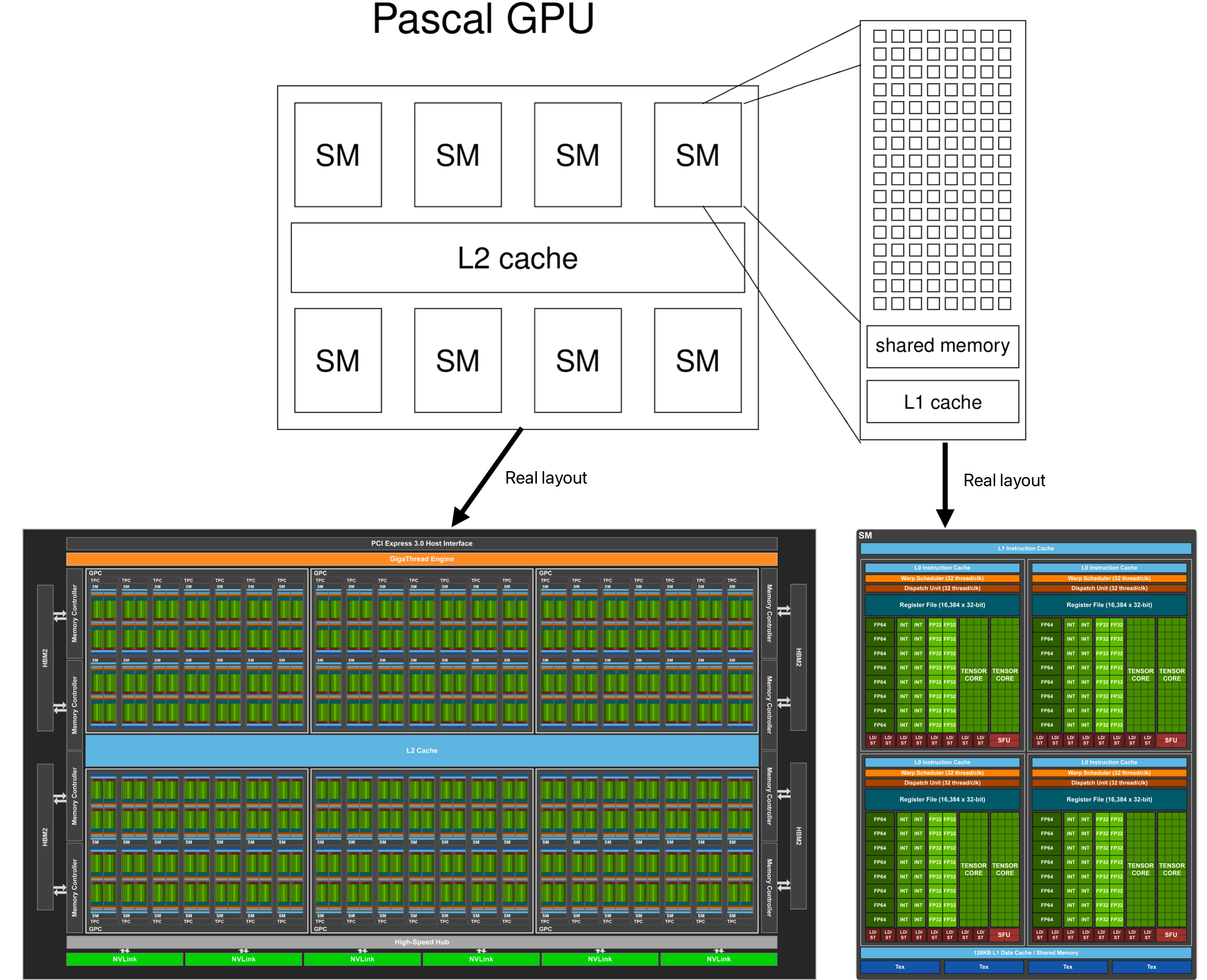
首先给出一个gpu的简易逻辑图,理解gpu,sm,sp,warp scheduler的关系
一个kernel 函数是一个grid,对应整个gpu 然后grid中包含很多block,这个和gpu中的sm对应 block包含很多thread,这个和sm中的sp对应
sm的组成:
- register
- shared memory
- the cache of constant memory
- the cache of texture and surface memory
- L1 cache
- warp scheduler
- SP(截止到2023/12/09,对sp的理解是它只是一个泛称,不是特指某种具体的运算单元,SP可能对应于不同的硬件组件,包括浮点运算单元(FP)、整数运算单元(INT)、特殊功能单元(SFU))
所以调度问题分为两个层面:
- 对于block的调度: block 不能拆分,只能整个放到 sm 上,并且 GPU 采用的是“一次分配,直到执行完成”的调度策略,当一个block被分配到SM后,它会独占一定的资源直到执行结束,并不会在执行过程中动态重新分配block到不同的SM(带来巨大的上下文切换开销,破坏SM中已有的资源分配)。
- 对于thread的调度: 把一个block放到一个sm上,这时候我们的视角就要缩小到这个sm中了,这时候我们不需要考虑block层面了,只是要考虑block中这一大堆thread如何调度。这时候warp的概念就出现了,把一大堆thread范围为一些warp。然后由warp scheduler调度这一个warp,更准确的说法是由warp scheduler调度warp中的thread,所以warp只是一个中间概念,最终调度的仍然是thread(明确这一点对于理解后文的bank conflict至关重要)
According to the real physical level, a SM(Streaming Multiprocessor) has many SP(Streaming Processor). Considure how can a every SM in GPU will excute multiple blocks, and it will divides block into multiple warps. The basic execution unit of SM is warp.
Some official concepts about warp:
- A block assigned to an SM is further divided into 32 thread units called warps.
- The warp is the unit of thread scheduling in SMs.
- Each warp consists of 32 threads of consecutive threadIdx values: thread 0 through 31 form the first warp, 32 through 63 the second warp, and so on.
- An SM is designed to execute all threads in a warp following the Single Instruction, Multiple Data (SIMD) model
软硬件版本辨析
从底层到上层,我们需要区分的几个概念是:
- GPU Edition (GPU Architecture, Compute capability)
- GPU Driver
- CUDA Toolkit
Compute capability
GPU Edition 指的是产品型号,例如 NVIDIA H100,GeForce RTX 5090。
GPU Architecture: 其中 H100 采用的是 Hopper Architecture,5090 采用的 Blackwell Architecture。
Compute capability: H100 的计算能力为 9.0,5090 的计算能力为 12.0。
GPU Edition 和 GPU Architecture 说白了都是产品层面的概念,对于开发者而言最为重要的是计算能力这一 metric,
Compute capability (CC) defines the hardware features and supported instructions for each NVIDIA GPU architecture. 1
这里遵循工具链部署时的顺序,优先在之后的两节讲述 Driver 和 Toolkit 的版本选择依据,关于计算能力的更详细介绍将放在最后一节。
Driver 版本要求
Driver 的挑选限制是比较低的,因为它提供了向下兼容性,所以在一定范围内我们可以无脑选择较新的版本,具体而言
This is a standard compatibility path in CUDA: newer drivers support older CUDA toolkit versions. 2
And when it comes to a software stack “needing CUDA 11.8”, that is primarily a statement about the necessary CUDA toolkit version (i.e. the runtime API version), not a required driver version. The driver simply needs to be new enough to support the specified CUDA version for the particular software stack. A newer driver will not preclude operation.
Toolkit 版本要求
虽然实际上 toolkit 与 Compute capability 之间是存在一定的匹配关系的,但是官方并没有提供类似于下表这样的信息(Wikipedia | GPUs supported 也提供了类似的表格)
| CUDA Version | Min CC | Deprecated CC | Default CC | Max CC |
|---|---|---|---|---|
| 5.5 (and prior) | 1.0 | N/A | 1.0 | ? |
| 6.0 | 1.0 | 1.0 | 1.0 | ? |
| 6.5 | 1.1 | 1.x | 2.0 | ? |
| 7.x | 2.0 | N/A | 2.0 | ? |
| 8.0 | 2.0 | 2.x | 2.0 | 6.2 |
| 9.x | 3.0 | N/A | 3.0 | 7.0 |
| 10.x | 3.0 | N/A * | 3.0 | 7.5 |
| 11.x | 3.5 † | 3.x | 5.2 | 11.0:8.0, 11.1:8.6, 11.8:9.0 |
| 12.x | 5.0 | 12.0-6 NA, 12.8: CC < 7.5 | 5.2 | 12.0-6:9.0, 12.8: 12.0 |
| 13.0 | 7.5 | N/A | 7.5 | 13.0:12.0 |
- Compute Capability 3.0 was deprecated in 10.2.
† CUDA 11.5 still “supports” cc3.5 devices; the R495 driver in CUDA 11.5 installer does not.
Toolkit 作为三层结构的最上层,除了考虑与 Compute capability 的对应关系,还需要考虑 driver 的要求。因为 Driver 存在一个对于 Toolkit 支持能力的上限,所以 Toolkit 在选取时是需要考虑 Driver 的版本的,对于 Toolkit 的限制可以通过 nvidia-smi 查询到。
Toolkit 的版本限制更多来源于开发过程中依赖的第三方库所使用的 CUDA Toolkit 版本,就像 Pytorch 在安装时是要区分 CUDA Toolkit 的版本的。
计算能力对实际运行的影响
在 异构编译实例 - CUDA Compilation 一文中我们就提到过这一内容,不过当时更多是从“CUDA 对于兼容性和执行性能的综合考量的设计原则“的角度进行的分析,并没有着重强调计算能力为程序执行所带来的影响。这里重新阐述一次,因此在内容上存在交叉。
在开发过程中,我们接触到计算能力是通过 -gencode arch=compute_xx,code=sm_xx 这一编译选项,其中 arch 指定 Virtual Architecture,即生成的 PTX 代码所遵循的计算能力;code 指定 Physical Architecture,即生成的 SASS 所遵循的计算能力(这里为了便于理解,认为 code 对应的是 SASS,官方文档给出的表述则是 “compute_XX refers to a PTX version and sm_XX refers to a cubin version”)。
我们先不考虑 PTX 对更广泛兼容性的支持,还是看限制条件更为严格的 cubib 受计算能力的影响。
A cubin generated for a certain compute capability is supported to run on any GPU with the same major revision and same or higher minor revision of compute capability. For example, a cubin generated for compute capability 8.0 is supported to run on a GPU with compute capability 8.6, however a cubin generated for compute capability 8.6 is not supported to run on a GPU with compute capability 8.0, and a cubin generated with compute capability 8.x is not supported to run on a GPU with compute capability 9.0. 3
SIMT Architecture
There is a question involved here that branch divergence between difference threads in the same warp.(Branch divergence occurs only within a warp, different warps execute independently regardless of whether they are executing common or disjoint code paths.4)
It is worth noting that not all branch divergence elimination will generate performance benefits. Because if there is only a single if sentence such as the following code
| |
Although maybe there are some threads which satisfies the condition, they will enter to the if sturct and execute the code block A and other threads will not. 但这些不进入的线程只需等待进入 code block A 的线程执行完即可。
If we have an integral if-else sturct such as the following code
| |
在这种情况下,Warp中的线程会分别执行 code block A 和 code block B。如果条件不同,线程会分别进入 code block A 或 code block B,这就意味着Warp中的一部分线程需要先执行一个分支,然后再执行另一个分支。这样每个分支都要被串行执行一次,导致性能降低,因为每个分支的执行时间都被加起来了。
So, it does not mean that performance will decrease if branch divergence arises.
Tensor Core
Warp-level matrix multiply and accumulate (WMMA) API was introduced at CUDA 9.0 which can be used to manipulate tensor cores.
Why the tensor core is called warp-level?
According to the hardware structure of gpu, we can find that tensor cores are located in warp shedulers.
A $16 \times 16$ fragment will be divided into 4 $8 \times 8$ portions. One portion is handled by a warp.
Because a portion has 64 elements and a warp has 32 threads, every thread will control two elements, it looks like the following figure.

如何理解上图 ?
fragment 是 warp-level 的,如果我们给一个 warp 分配一个 $16 \times 16$ 的 fragment,一个 warp 中的 32 个线程该如何分配这个 fragment? 难道说每一个线程都能访问到整个 fragment 吗?
上图展示的即为一个 warp 的 32 个 thread 在面对一个 $16 \times 16$ 的 fragment 时的数据映射情况,fragment 被分为 4 个 $8 \times 8$ 的子块,每一个子块都将对应到整个 warp,64 个数据分配给 32 个线程,每个线程对应 2 个数据
通过代码验证上述结论:
| |
我们将得到以下结果:

由此可见线程的分布情况,同时需要说明的是每个线程在 fragment 中访问的数据个数是由 num_elements 来标识的。
Tensor core 的 4 种调用方法:
- WMMA (Warp-level Matrix Multiply Accumulate) C++ API
| |
- WMMA PTX (Parallel Thread Execution)
| |
- MMA (Matrix Multiply Accumulate) PTX
| |
- SASS
If we want to use the PTX in CUDA C++, we can reference to this document.
PTX
The format of ptx instruction: opcode [.qualifiers] [.modifiers] operands;
opcode: 操作码,表示具体的操作指令,例如 add, mul, ld, st, mov, 等。.qualifiers: 限定符,修饰操作符的属性- 存储空间限定符 (针对内存指令,如 ld 或 st): global, shared, local
- 数据类型限定符: 描述数据类型,如 u32, f32, s16
.modifiers: 修饰符, 用于调整操作的行为,修饰符的顺序通常根据功能固定。例如: - 舍入模式(rn, rz, rm, rp):用于浮点计算。 - 饱和修饰符(sat):用于确保结果在范围内。operands: 操作数, 指令作用的具体对象,可以是寄存器、常量或内存地址。
数据类型限定符 6:
| Basic Type | Fundamental Type Specifiers |
|---|---|
| Signed integer | .s8, .s16, .s32, .s64 |
| Unsigned integer | .u8, .u16, .u32, .u64 |
| Floating-point | .f16, .f16x2, .f32, .f64 |
| Bits (untyped) | .b8, .b16, .b32, .b64, .b128 |
| Predicate | .pred |
The basic inline ptx syntax is as follows:
| |
关于内联汇编的关键字 asm 和 __asm__,前者是标准的 C/C++ 关键字,因此具备跨平台能力;后者是 GNU 编译器的扩展关键字,依托于 GNU 编译器,跨平台能力一般。即一个是语言层面的,一个是编译器层面的。
- The
ptx_instructioncan contain multiple instructions, we need to use the\n\tto devide every instruction. For example
| |
- The constraints has some types combination:
read-write permission:
- data type: 8
| |
So, we can combine the premission and data type and get the following constraints example:
randmare used for input=r(which means output to the register) and=m(which means output to the memory) are used for output,+rto specify the register is both read and written
| 约束符 | 寄存器类型 | 读写属性 | 等效 C 语义 | 适用场景 |
|---|---|---|---|---|
| r | 通用 | 只读输入 | const int | 整数运算、位操作 |
| f | 浮点 | 只读输入 | const float | 浮点运算 |
| =r | 通用 | 只写输出 | int output | 结果写入整型变量 |
| =f | 浮点 | 只写输出 | float output | 结果写入浮点变量 |
| +r | 通用 | 读写 | int &inout | 整型累加、位修改 |
| +f | 浮点 | 读写 | float &inout | 浮点累加、中间结果复用 |
| 舍入模式 | 数学行为 | 误差特性 | 适用场景 | 适用场景 |
|---|---|---|---|---|
| .rn | 向最近的偶数舍入 | 平均误差最小,无系统性偏差 | 通用计算(推荐默认选择) | 整数运算、位操作 |
| .rna | 向最近的数舍入,平局时远离零 | 减少极端偏差,精度更稳定 | 科学计算、累积误差敏感场景 | 浮点运算 |
| .rz | 向零截断(直接丢弃低位) | 系统性负偏差 | 图像处理、确定向下取整 | 结果写入整型变量 |
| .rm | 向负无穷方向舍入 | 系统性负偏差 | 区间计算(确保不超界) | 结果写入浮点变量 |
| .rp | 向正无穷方向舍入 | 系统性正偏差 | 安全关键计算(确保不低估) | 整型累加、位修改 |
| .rs | 基于随机位的概率性舍入 | 无系统性偏差,误差呈均匀分布 | 蒙特卡洛模拟、对抗过拟合 | 浮点累加、中间结果复用 |
wgmma

A is stored in row-major order, while B is stored in column-major order.
Memory Structure
The “fragment” is a warp-level concept, there are some warp scheduler units in a SM, every warp will be scheduled in a sub-partition of SM, the fragment data is in the register file.
So, the fragment is warp private data, every thread in the same warp has the entire data of this fragment.
Memory structure
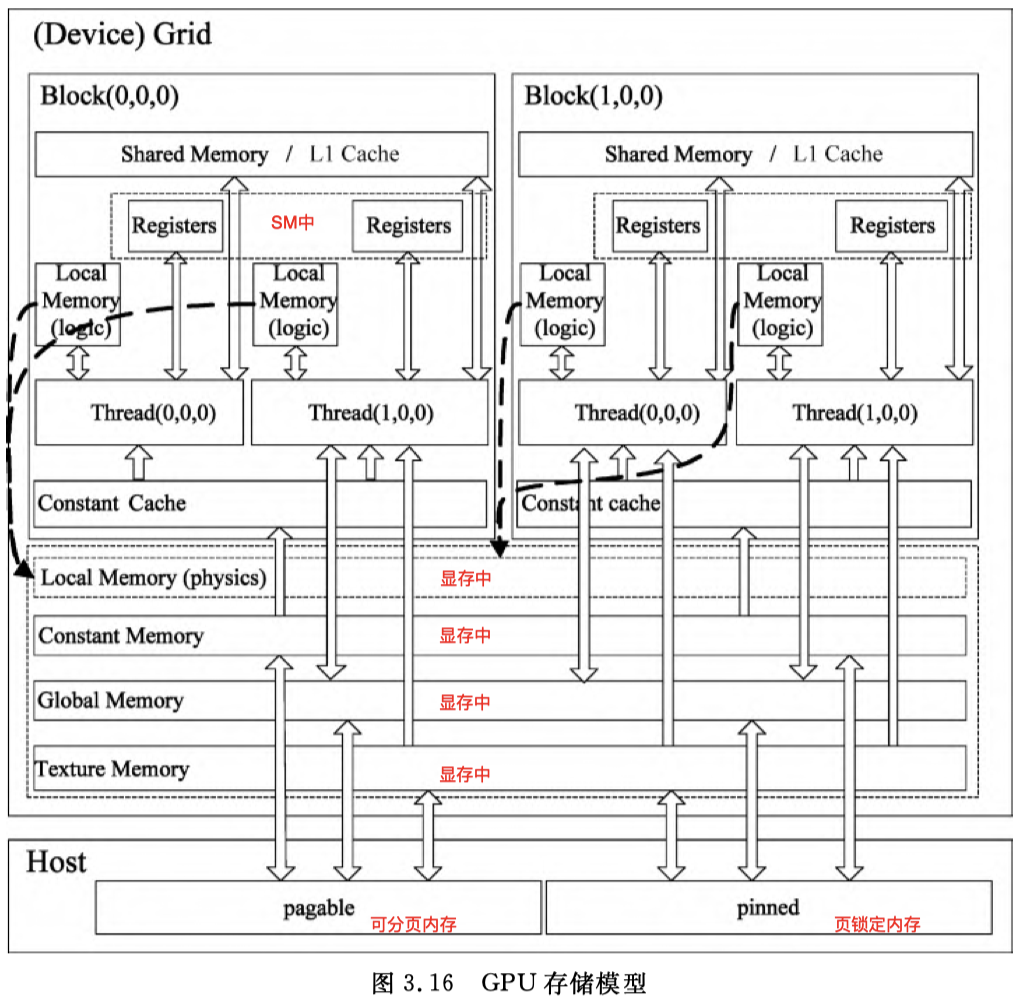
How to detect the using situation of the different types of memory?
- Use nvcc compilation option
--ptxas-option=-v--ptxas-optionis used to specify options directly to ptxas(the PTX optimizing assembler, its location in the whole compilation process can be seen at CUDA Compilation) - Use nvcc compilation option
-keep - Use
nvprofcommandnvprof --print-gpu-trace <program path>
Cache
There are 5 types of cache in cuda:
- shared memory(equivalent to a user-managed chache)
- L1 cache
- L2 cache
- constant cache
- texture cache
L1 cache and L2 cache 隐式管理
shared memory and global memory 显式管理
We will talk more details about shared memory later, so we only focus on the remaining four types of real cache.
L2 cache
Just like L1 cache and shared memory, the L2 cache and global memory is related.
L2 cache is used to provide higher bandwidth and lower latency accesses to global memory.
We can refer to Query L2 cache Properties to get the properties of L2 cache.
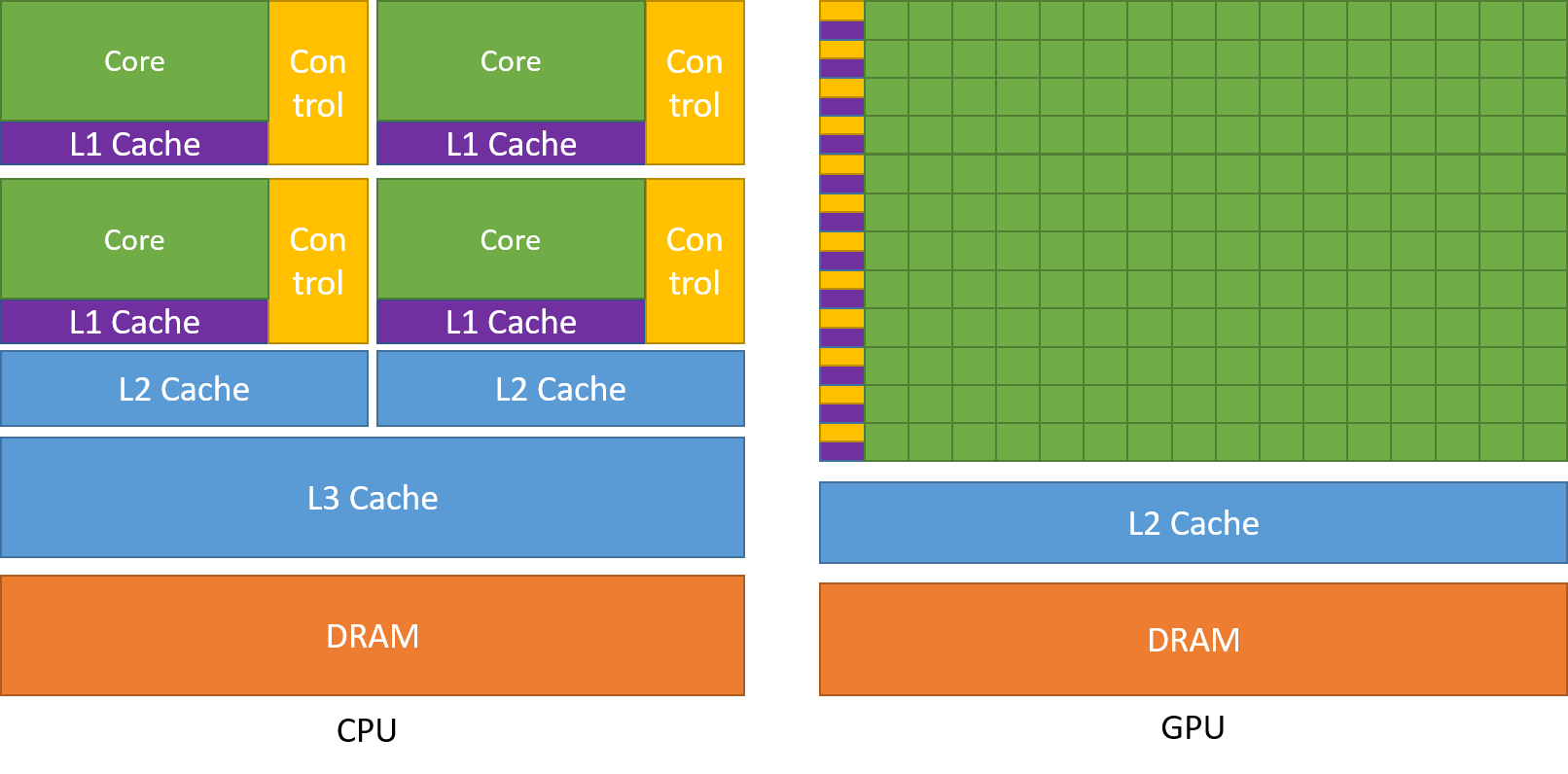
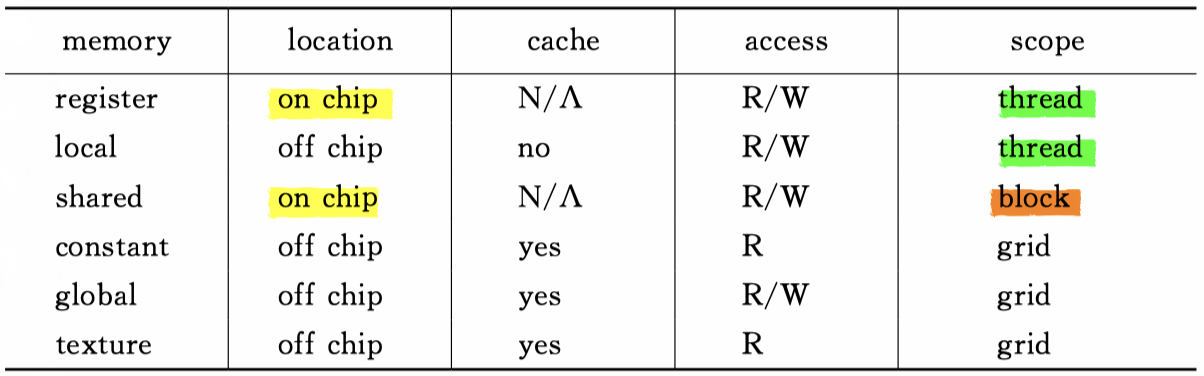
Register & Local Memory
Global Memory
The path of accessing global memory: L1 cache -> L2 cache -> global memory
coalesced & uncoalesced
coalesced memory access <=> a global memory access request from a warp will cause to 100% degree of coalescing.
The above conclusion has two important things we need to pay attention to:
- The object we talk about is a warp
- The definition of degree of coalescing is described as the following formula
$Degree \ of \ coalescing \ (合并度) = \frac{ request \ bytes \ number \ (warp实际请求数据量) }{ bytes \ number \ that \ participate \ in \ the \ data \ transforming \ (实际输出的数据量)}$
看到一句话,提到了DRAM burst,暂时还没有找到官方的解释
CUDA Coalesced access uses the DRAM’s burst mode
因为coalesced access是基于DRAM的burst mode来实现的,所以本质上会涉及到DRAM burst发生的性质和要求:
- 对齐
- 访存大小
疑惑点其实是在于发生coalesced是否和warp相关,是不是必须是同一个warp内的线程的访问才肯跟造成coalesced access,还是说同一个block不同warp,还是说不同block都可以?如果仅从DRAM burst发生的角度考虑,burst发生的条件应该是和CUDA的一些概念无关的,所以视角似乎可以直接放到不同线程上,并不需要考虑是否是同一warp或者是否是同一block
想要理解memory coalesced和uncoalesced,思维必须从串行思维转换到并行思维,
Coalesce happens amongst threads, not amongst different iterations of the loop within each thread’s execution.
关注的重点不应放在一个单独的thread上,我觉得一个比较合适的视角是放在一个warp上(关于这一点,有一个很明显的错误示范,就是矩阵乘法P=MxN,如果从单一thread的角度来看,对M的访问应当是满足coalesced地,但是如果考虑属于一个warp的不同thread,就会发现实际上对N的访问才是coalesced。考虑某一时刻属于同一个warp的thread的访存方式。关于这一示例的详细分析,可见The CUDA Parallel Programming Model - 5. Memory Coalescing
Common memory access types
Please note that the third and the last code can’t get the right answer. The following code is just to used to describe types of memory access type.
- Sequential coalesced access(顺序的合并访问)
| |
- Out-of-order coalesced access(乱序的合并访问)
| |
- Misaligned uncoalesced access(不对齐的非合并访问)
| |
- Strided uncoalesced access(跨越式的非合并访问)
| |
Please Note that this is different from grid stride loop, which emphasizes that how to solve the big problem which the scale is bigger than the amount of threads. But there we want to emphasize a type of memory access.
- Broadcast uncoalesced access(广播式的非合并访问)
| |
broatcast这种方式还涉及到constant memory的使用
其实global memory就类似dram,l2 cache也就是个cache,所以thread访问global memory的过程和体系结构里面对于cache的分析过程是完全一样的,thread请求一个字节的数据,发现cache中不存在,即发生cache miss,然后就去访存,并且把数据缓存到cache line中,访问同一cache line对应数据的thread的再访存就是cache hit了,所说的这个合并访问似乎不过是访问这个cache line的过程,只要是一次访存对应几次都是cache hit就算是合并访存了,似乎完全可以这样理解. 其实这块判断是否会发生合并的一个前提就是确定从global memory一次到底取多少数据,现有认知是按照字节编制,但是按照字进行读取,但是书上却说一次读取32Bytes,一个字总不能有32Bytes吧。
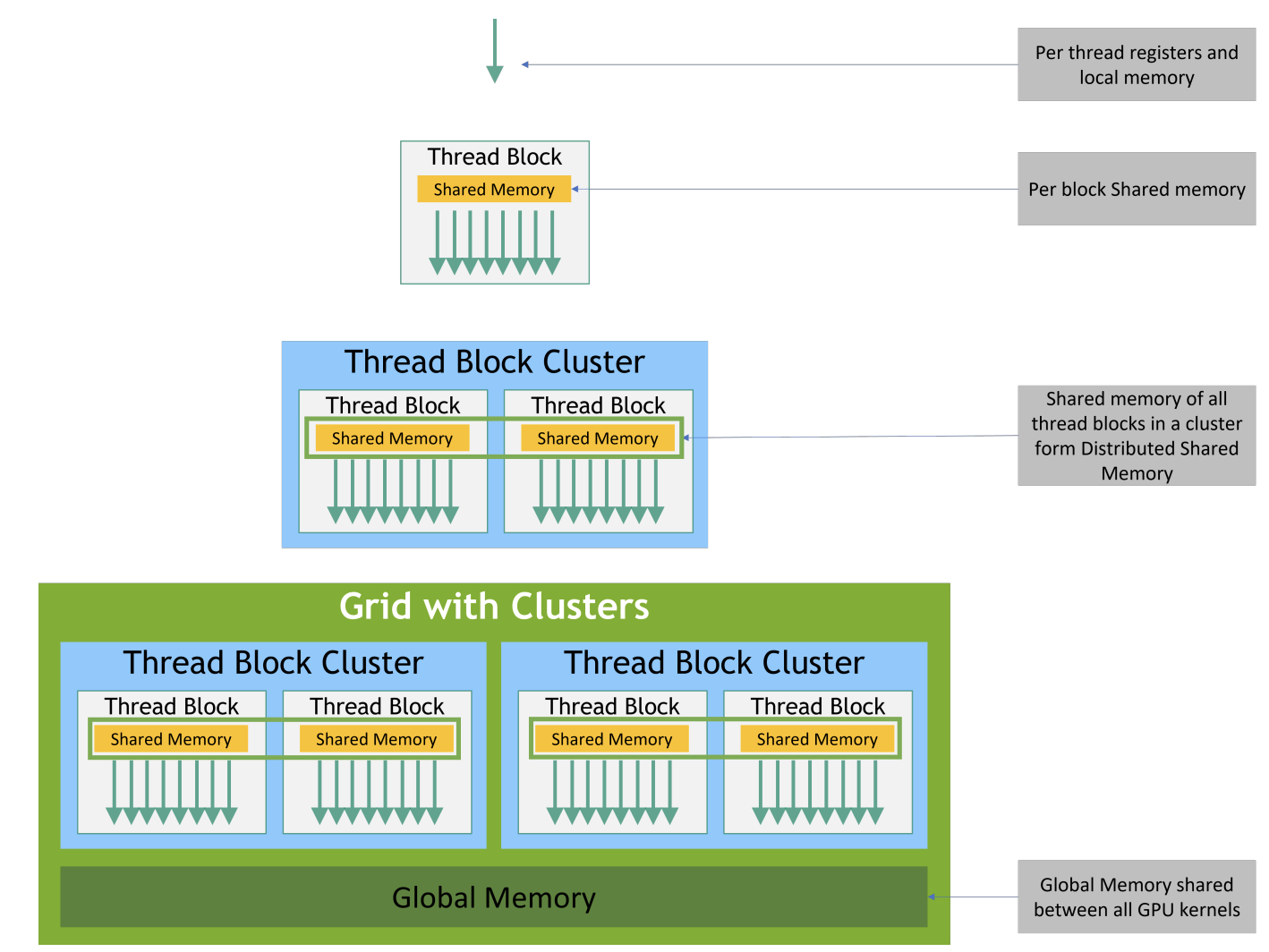
Shared Memory
共享内存中的内存块通常被直接称为 memory tile 或简称为 tile。(可能这就是Tiled Matrix Multiplication的由来)
Create Shared Memory
- 静态shared memory,使用
__shared__限定符创建时就指定存储空间的大小
| |
- 动态shared memory,不确定空间大小,需要动态申请时
| |
需要在kernel函数调用时,指定申请的shared memory的大小
| |
在C/C++中,存在一个变长数组(Variable Length Arrays,VLA)的概念,允许使用变量来指定数组的大小。 但是实际测试,变量指定数组大小应用于kernel函数时,会报错"error: expression must have a constant value"
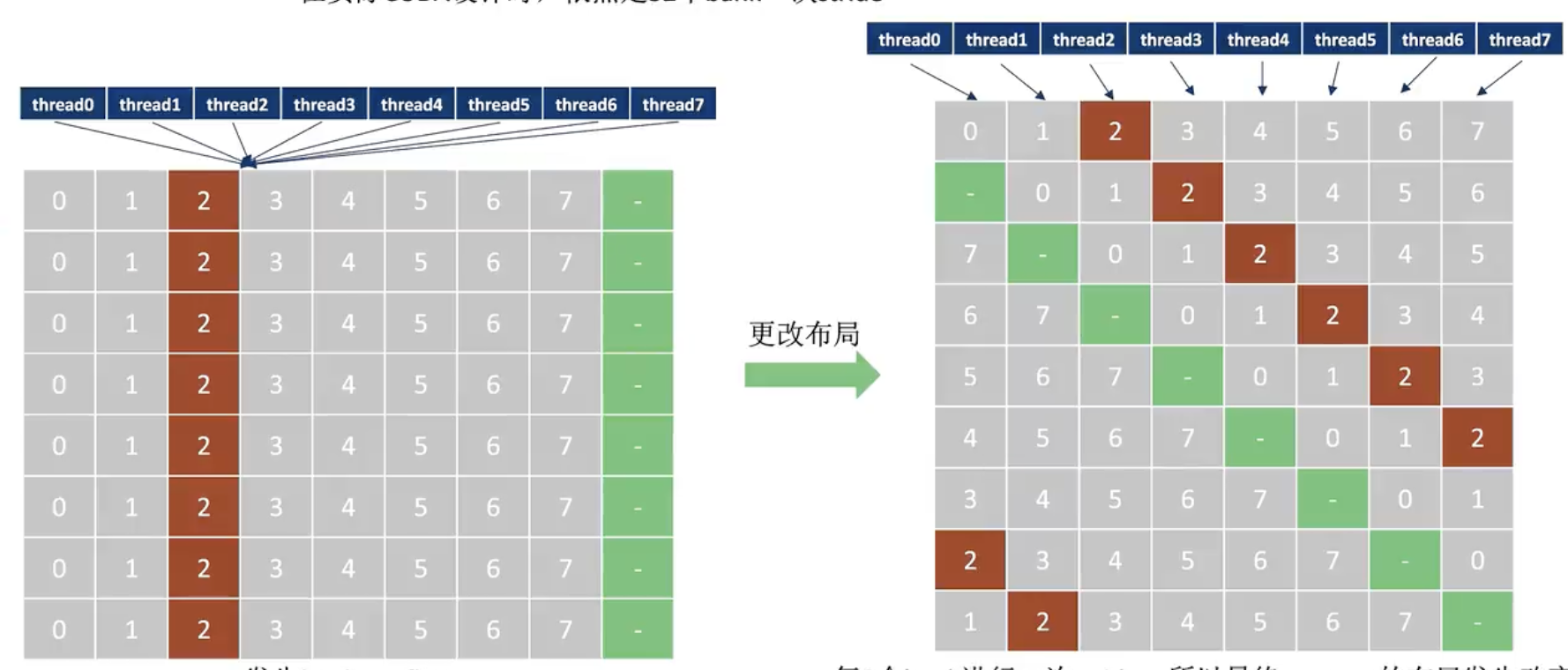
Bank Conflict
To understand this problem well, we should revisiv the hardware structure of gpu.
在此基础上,我们将gpu的建议结构图进行扩充,装入shared memory和bank的结构 还需要一张shared memory中是如何划分的bank
bank的划分单位和最大bandwith都是32bits=4bytes=1word 但是寻址单位还是1byte
哪些情况下会产生bank conflict, 首先看一下都有哪些可能的bank访问情况
同一warp:
1.1 两个thread访问同一个bank中相同的字中的地址 (broadcast, conflict-free)
1.2 两个thread访问同一个bank中不同的字中的地址 (conflict)
1.3 两个thread访问不同bank (conflict-free)
不同warp:
2.1 两个thread访问同一个bank相同的字中的地址 (conflict)
2.2 两个thread访问同一个bank不同的字中的地址 (conflict)
2.3 两个thread访问不同bank (conflict-free)
要理解bank conflict,需要首先了解bank是怎么回事,
To achieve high bandwidth, shared memory is divided into equally-sized memory modules, called banks, which can be accessed simultaneously.
尤其是后面这句话比较重要,不同bank可以同时响应数据请求(实现这一点应该是需要硬件支持的,每一个bank是一个独立的存储单元)
所以就可以理解为什么不同thread访问同一个bank的时会降低效率,因为本来可以同时读,现在只能串行读(关于这一点还有以下疑点:bank coflict 只发生在不同warp中的thread在访问同一个bank的不同byte时,同一个warp内的thread无论如何访问都不会产生bank conflict)
这样来看,bank本身和ram的性质类似,但是整个shared_memory可以看为是多个ram拼接而成
According to the real hardware architecture of SM, SM has multiple warp schedulers.
A block will be distributed to a SM, but the unit of execution of SM is warp which has 32 threads.
It is easy to understand the principle of this setting, as we all know a block has many threads, if SM dispatch all of them at the same time, it will casuce difficulties. So the designer divide the block into warp.
All warps in the same block will share the same shared memory. Shared memory is also divided into many subdivisions. The number of subdivisions equals to the number of warp.
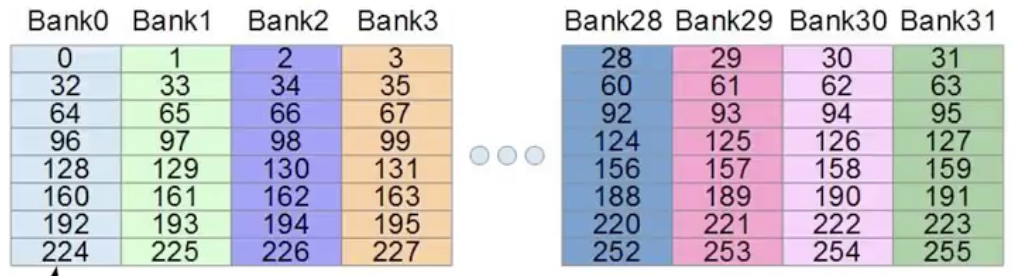
Warp access shared memory use the bank as the unit.
The most optimal situation is every warp correspondens to a bank. At this situation, the time of accessing whole 32 banks is just 1 memory cycle.

To be precise, it should contains 32 threads and banks in figure. It is just a schematic drawing.
But if many bank access the same bank, it will cause the following situation. At this situation, the time of accessing whole 32 banks is 32 memory cycles.
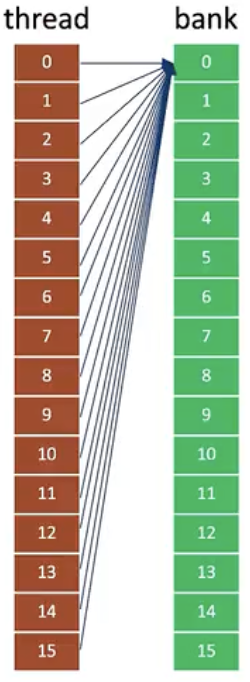
To be precise, it should contains 32 threads and banks in figure. It is just a schematic drawing.
An correlative calculation of this problem The hardware splits a memory request with bank conflicts into as many separate conflict-free requests as necessary, decreasing throughput by a factor equal to the number of separate memory requests.
If the number of separate memory requests is n, the initial memory request is said to cause n-way bank conflicts.
To get maximum performance, it is therefore important to understand how memory addresses map to memory banks in order to schedule the memory requests so as to minimize bank conflicts.
How can we solve this problem ?
We can pad and adjust the memory structure as the following picture shows.
Reference
使用量与计算性能之间的关系
这里想要回答一个问题:一个 CTA 占用多大 Shared Memory 时程序性能才能达到最优?
在分析具体内容之前,我们需要先了解一下为什么 Shared Memory 的使用量会影响到程序的性能。一个 SM 中总的 Shared Memory 量是固定的,这个 SM 会负责 >=1 个 CTA 的执行,具体能承载的 CTA 的数量就取决于这个 SM 的 Shared Memory 总量能够供给几个 CTA 的使用,下一步需要分情况讨论:
Block 数量没占满 SM,此时每个 CTA 的 Shared Memory 占用量基本不影响执行时间。例如只有 10 个 Block,而 GPU 有 80 个 SM。每个 Block 独占一个 SM 绰绰有余,此时 Block 之间不存在对 SM 槽位的竞争。即使把每个 Block 的 Shared Memory 调大(只要没超过 SM 的物理上限),它也不会挤掉别的 Block
Block 数量刚好填满或略超 SM,此时的最优解是刚好让所有 Block 同时都能分配到 SM。例如有 160 个 Block,GPU 有 80 个 SM,如果每个 Block 申请了 SM 总量 60% 的 Shared Memory,那么一个 SM 只能跑 1 个 Block,这意味着剩下的 80 个 Block 必须等第一批跑完才能上场,总时间翻倍,因此理想情况是每个 SM 负责 2 个 Block。
以上是从相对宏观的 CTA 在 SM 上的情况来看待这个问题,现在的情况是每个 CTA 都已经分配到某一个 SM 上了,下面我们不妨进一步下探分析还有什么因素可能会影响到计算时间。
能够下探的依据在于一个 SM 内部能并行的最小单位不是 Block,而是 Warp。SM 在调度 Warp 时有一个方式,当某个 Warp 进入长时间的访存状态时,它就会调度另一个 Warp 来执行,那如果 Block 内 Warp 数量设置的较少,没有足够多的 Warp 可以完成这种重叠,那 SM 大部分时间也会因为等待内存读取而空转。因此在前面提到的尽量让所有 Block 都能分配到 SM 这个最优解之外,也应该尽量维持足够的 Active Warps 数量来掩盖指令延迟。实际上这一性质所对应的指标就是 Occupancy。
Constant Memory
A simple use of constant memory comes from convolution.
In convolution, because there are four aspects which leads to that we can use constant memory.
- The ratio of floating-point arithmetic calculation to global memory accesses is so low.(计算访存比较低,简单理解就是读了很多数据但是计算的比较少,事倍功半)
- The size of mask is small. (The constant memory size is small)
- The constants of mask are not changed throughout the execution of the kernel. (The constant memory is prohibited modification)
- All threads need to access the mask elements. (store memory into cache is effective)
According to the picture at the beginning of the Memory structure. We can learn about the constant memory is in DRAM.
But because the variable or space in constant is prohibited modification, so cuda runtime can put its content to cache trustfully, at the same time, no modification means that there is no cache coherence issue.
There are three important aspects of using constant memory:
__constant__ float M[];, use the__constant__specifier and M should be a global variablecudaMemcpyToSymbol(M, M_h, Mask_Width*sizeof(float));
Host Side Memory
pageable memory
可分页内存
- 使用
malloc()/new()和free()/delete()函数分配和释放 - 此类型内存是可以从内存被换出到磁盘的
pinned memory
pinned memory, aka non-pageable memory(不可分页内存) / page-locked(页锁定内存)
- 使用
cudaHostAlloc()/cudaMallocHost()和cudaFreeHost()函数分配和释放
cudaHostAlloc()和cudaMallocHost()的关系是cudaHostAlloc(xxx, yyy, cudaHostAllocDefault)等价于cudaMallocHost(xxx, yyy)
- 此类型内存一直停留在内存,不会被换出到磁盘
- 此类型内存支持DMA访问,支持与GPU之间进行异步通信(asynchronous data transfer)
Some background on the memory management in operating systems
cudaMemcpy()uses the hardware direct memoryory access (DMA) device.- The operating system give a translated physical address to DMA, i.e. the DMA hardware operates on physical addresses.
- Uses the DMA to implement the
cudaMemcpy()faces a chance that the data in the pageable memroy can be overwritten by the paging activity before the DMA transmission.
The solution is to perform the copy operation in two steps:
- For a host-to-device copy, the CUDA runtime first copies the source host memory data into a pinned memory buffer, sometimes also referred to as page locked memory buffer.
- It then uses the DMA device to copy the data from the pinned memory buffer to the device memory.
The problems of this solution:
- Extra copy adds delay to the cudaMemcpy() operation.
- Extra complexity involved leads to a synchronous implementation of the cudaMemcpy() function.
About the synchronous and asynchronous, please see the API synchronization behavior
To solve this problem, we can use the cudaHostAlloc() to open up pinned memory buffer, and use the cudaMemcpyAsync() to copy a data asynchronously.
New Memory Access Technology
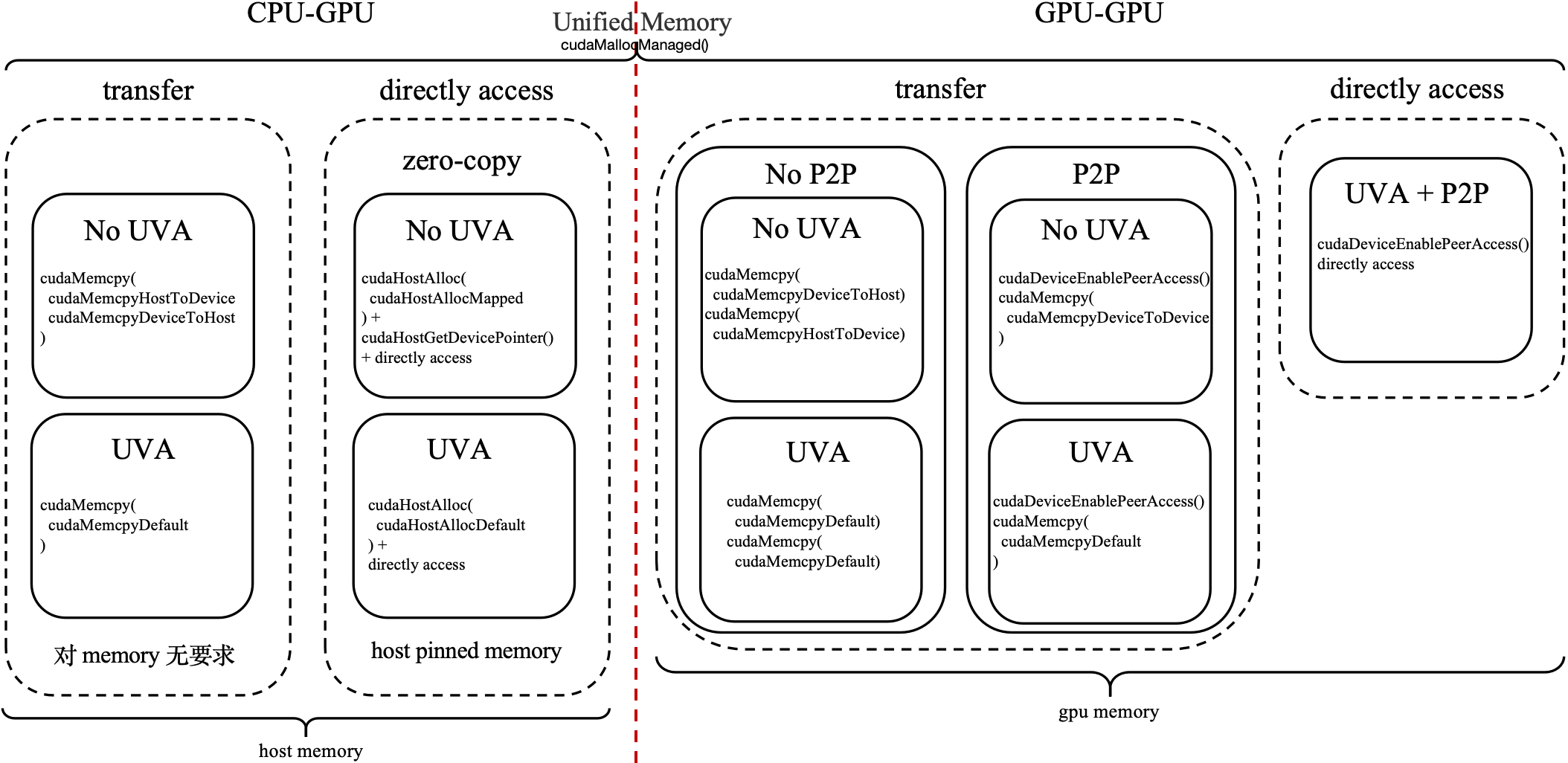
简单来说:
- 有了 UVA 就不用管这个指针到底指向的是 CPU 还是 GPU 了
- 有了 zero-copy / Unified Memory 就可以不需要手动管理 CPU 和 GPU 之间的数据拷贝了
- 有了P2P,GPU间的数据传输就不需要经过 CPU 了
UVA
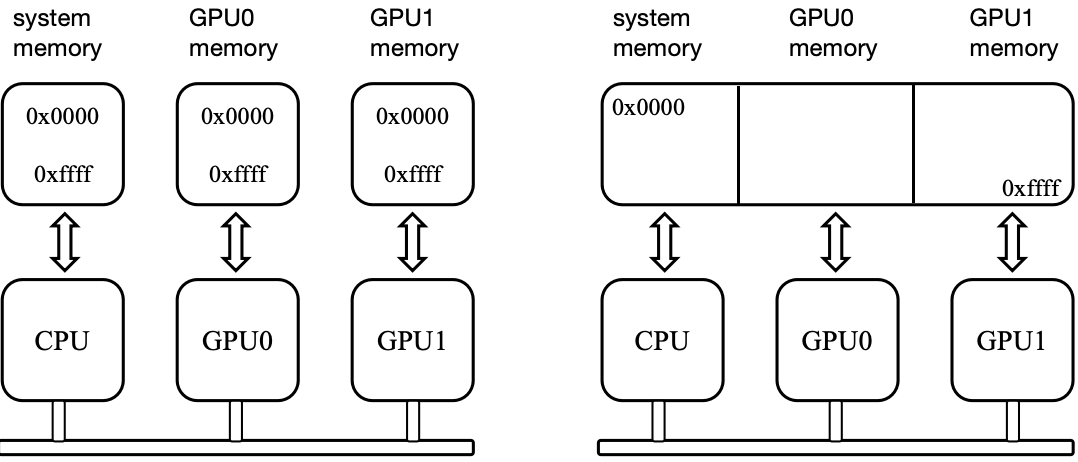
Unified Virtual Addressing, a memory management model where copy without specifying in which memory(CPU and GPU share the same virtual address space).
The effect of UVA is that we don’t need to distinguish whether pointers come from the CPU or GPU.
So, when we use cudaMemcpy() to transfer data, we can use cudaMemcpyDefault directly instead of indicating the transmission direction, such as cudaMemcpyHostToDevice and cudaMemcpyDeviceToHost.
在直接访问的场景下,情况有点不同。我们很容易认为,只要有了 UVA 的支持,那么 CPU 和 GPU 之间的存储空间就可以任意访问的。但是统一地址空间 $\ne$ 可以直接访问,简单理解,UVA 只是拓宽了查看存储空间的视角,CPU 和 GPU 间,GPU 和 GPU 间能够看到各自的存储空间,但是这并不代表就可以随意访问了。因为访问的实际行为依赖于硬件支持。
对于 CPU 和 GPU 间的直接数据访问需要 zero-copy 的支持,特殊之处在于这种机制的开启本质上并不是通过某个 API 来实现,而是当分配的 host memory 是 pinned memory 时,自然地就支持这种机制。对于 GPU 和 GPU 间的直接数据访问则需要 P2P (Peer-to-Peer)的支持。
Zero-Copy Memory
首先,零拷贝内存并不是像unified memory这样的逻辑存在,其是一种物理存在。其特别之处在于实际的物理存储空间实际是 Host Memory,但是 device 却可以通过某种方式直接访问,无需人工进行拷贝操作。
The way of opening up zero-copy memory
The zero-copy memory is a special host memory, it is a pinned memory.
- When we use
cudaHostAlloc()to open up a pinned memory, we need to transmit the third parameterflag. We need to transmitcudaHostAllocMappedas a flag to cudaHostAlloc(). - Host code use
cudaHostGetDevicePointer()to get a pointer which points to the pinned memroy.
Please note that we should get the zero-copy memory pointer in host code rather than device cost, although it is more reasonable to get this pointer in device code.
- At this time, the pinned memory is called zero-copy memory.
| |
Please notice that although we don’t have the support of UVA, we can also use zero-copy thchnology. The difference between no UVA support and UVA support is that if we have UVA support, we can use host pointer in kernel, so we don’t need to use cudaHostGetDevicePointer().
Unified Memory
Unified Memory 是一种逻辑上的存在,它提供了一种抽象层,让程序员可以将主机(CPU)和设备(GPU)上的内存视为一个统一的内存空间。
使用Unified Memory的情况下,程序员无需显式地管理数据的迁移,系统会根据需要自动处理。
Unified Memory通过使用页表和硬件支持,实现了逻辑上的一致性。
Unified Memory并不是物理上的一块内存,而是一个逻辑概念,通过系统的管理和硬件支持,实现了对主机和设备上内存的透明管理。这有助于简化GPU编程中的内存管理任务。
Unified memory 和 zero-copy 很相似,二者的效果都是不需要手动管理 CPU 和 GPU 间的数据拷贝,但是二者都能访问到相同的数据。实际区别在于 unified memory 在底层实现了数据拷贝,保证 cpu code 访问的始终是 host memory,device code 访问的始终是 gpu memory;10 但是 zero-copy 就是分配在 host memory 的空间,并不会发生数据拷贝。
P2P
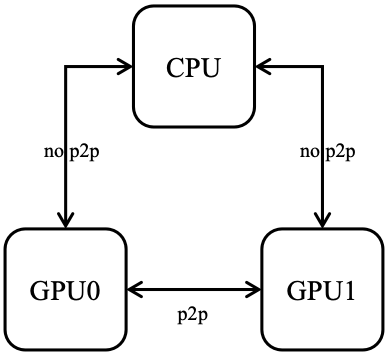
在 UVA 一节提到过,zero-copy 和 P2P 本质上都是在 UVA 拓宽存储空间视角后提供实际访问能力的机制。 不过需要注意,这并不代表着必须有 UVA 的支持时,zero-copy 和 P2P 才有意义,最本章节最开始的图可以看出,即使没有 UVA 的支持,zero-copy 和 P2P 一样是可以使用的,所以关于 zero-copy、P2P 和 UVA 之间的关系,更准确的说法应当是,zero-copy 和 P2P 提供了直接数据访问的能力,UVA 在此基础上拓宽了存储空间的视角,使得不用严格区分到底是 host 指针还是 device 指针。
Memory API
CUDA C提供了与C语言在语言级别上的集成,主机代码和设备代码由不同的编译器负责编译,设备函数调用样式上接近主机函数调用
cudaMemcpy() will synchronize automatically, so if the last line code is cudaMemcpy(), we needn’t to use the cudaDeviceSynchronize()
Different devices corresponding to different memory functions
| Location | memory allocate | memory release |
|---|---|---|
| Host | malloc/new | free/delete |
| Device | cudaMalloc | cudaFree |
| Unified Memory | cudaMallocManaged | cudaFree |
Which memory types do we have ? Host and device has different authorities to use the memory. The following table describes their authorities.
| Memory type | Host | Device |
|---|---|---|
| Global memory | W/R | W/R |
| Constant memory | W/R | R |
Why we need unified memory ?
- Additional transfers between host and device memory increase the latency and reduce the throughput.
- Device memory is small compared with the host memory. Allocating the large data from host memory to device memory is difficult.
Annotate: W means Write and R means Read
2D Array
Refering to the methos of opening up a 2D space in host code which see the first dimension of array is some pointers and the second dimension of array is a 1D array. When we want to allocate a 2D array in device memory, the above method is difficult, because we need to access a space of device memory in host code.
So, CUDA provide pitched memory to implement it. We can use cudaMallocPitch() to create a 2D space in device memory, cudaMemset2D() to copy data between host and device and cudaFree() to release space.
Asynchronous copy
Copy operation completion mechanisms supported in PTX 有两种,可以简单理解为异步操作实际使用时的模式
- Async-group mechanism
- Initiate the asynchronous operations
- Group the asynchronous operations into an async-group using a commit operation
- Wait for the completion of the async-group using the wait operation
- Once the async-group completes, access the results of all asynchronous operations in that async-group
- mbarrier-based mechanism
- Initiate the asynchronous operations
- Set up an mbarrier object to track the asynchronous operations in its current phase, either as part of the asynchronous operation or as a separate operation
- Wait for the mbarrier object to complete its current phase using mbarrier.test_wait or mbarrier.try_wait
- Once the mbarrier.test_wait or mbarrier.try_wait operation returns True, access the results of the asynchronous operations tracked by the mbarrier object
以上是对于同步机制的阐述,适用于所有异步操作后的同步过程。
从宏观目标来看,它们都是为了实现“同步”,只是作用点不同。
Fence 解决“空间/可见性”上的同步,Wait 解决“时间/时序”上的同步
| 特性 | Fence (如 fence_view_async) | Wait/Sync (如 arrive_and_wait) |
|---|---|---|
| 对程序流的影响 | 不停止,指令发完立刻执行下一条。 | 停止,程序卡在这一行直到条件满足。 |
| 解决的问题 | 数据可见性(Data Visibility)。 | 执行顺序(Execution Order)。 |
| 硬件成本 | 较轻量,主要是缓存一致性协议的开销。 | 较重量,会造成硬件流水线空转。 |
这里还需要理解 Generic Proxy(通用代理) 和 Async Proxy(异步代理)
Software structure
All CUDA threads in a grid execute the same kernel function;
It is easy to explain it. When we want to call a kernel function, we will specify the grid and block structure using the dim3 data type. It means that we want to use all these threads where locate in the grid to execute this kernel function.
In general, a grid is a three-dimensional array of blocks1, and each block is a three dimensional array of threads.
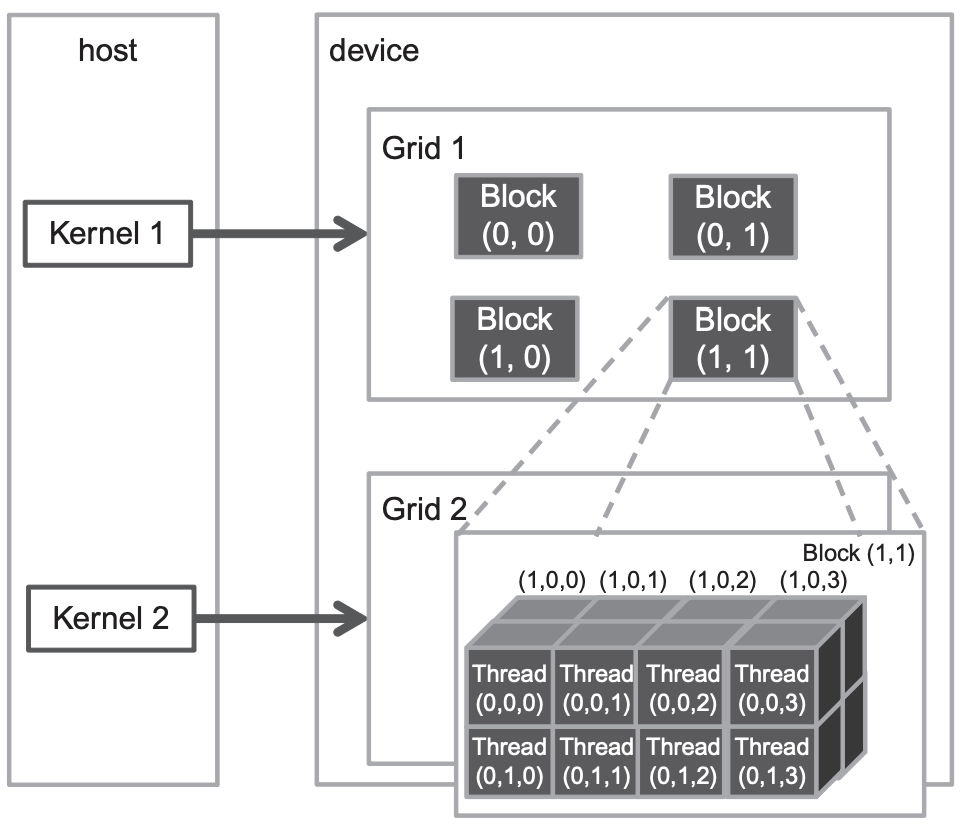
From a code implementation perspective, these two three-dimensional arrays are both a dim3 type parameter, which is a C struct with three unsigned integer fields: x, y, and z.
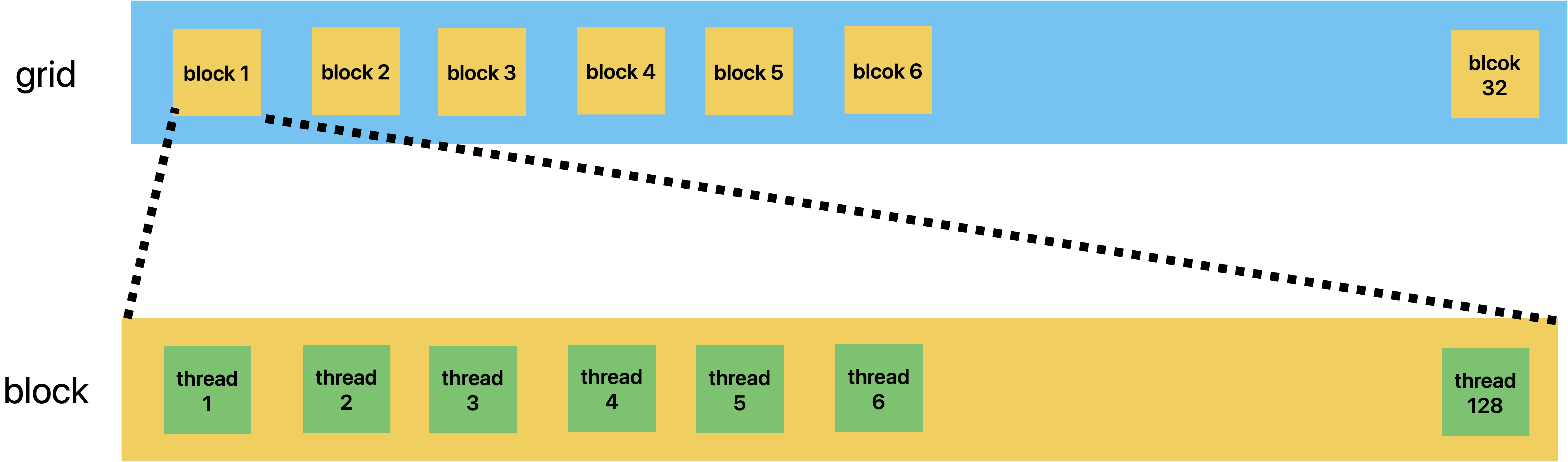
The first execution configuration parameter specifies the dimensions of the grid in the number of blocks. And the second specifies the dimensions of each block in the number of threads.
For example, as the following code shows, there is a grid and a block. The grid consists of 32 blocks, and it is a linear structure. The block consists of 128 threads, and it is also a linear structure.
| |
About the more detail specifications please see official technical specifications
Software stack

Kernel Function
Because the execution of the kernel function is asynchronous, that means the subsequent codes don’t know when the result will be returned by kernel funcion, so the type of returen value of kernel funciont must be void.
- CPU以及系统内存成为主机,GPU及其内存成为设备
- GPU设备上执行的函数称为核函数(Kernel)
- 核函数调用时«<para1,para2»>中的para1表示设备在执行核函数时使用的并行线程块的数量,通俗来说总共将创建para1个核函数来运行代码,共para1个并行执行环境,para1个线程块。这para1个线程块称为一个线程格(Grid)
- 核函数中存在一个CUDA运行时已经预先定义的内置变量blockIdx,表示当前执行设备代码的线程块索引
The difficulty of writing parallel programs comes from arranging the structure of grid、block and thread so that they can adapt the programs. What we ought to know is that the kernel funtion is just like a big loop in logic, it will enumerate the whole grid in threads.
Note: This perspective is just from code, it is not the true execution logic.
指针
主机指针只能访问主机代码中的内存,设备指针只能访问设备代码中的内存
设备指针
虽然cudaMalloc()同malloc(),cudaFree()同free()非常相似,但是设备指针同主机指针之间并不完全相同,设备指针的使用规则如下
cudaMalloc()分配的指针可以传递给设备函数,设备代码可以使用该指针进行内存读/写操作(解引用)cudaMalloc()分配的指针可以传递给主机函数,主机代码不可以使用该指针进行内存读/写操作(解引用)
主机指针与设备指针数据拷贝
- 主机->主机:
memcpy() - 主机->设备:
cudaMemcpy()指定参数cudaMemcpyHostToDevice - 设备->主机:
cudaMemcpy()指定参数cudaMemcpyDeviceToHost - 设备->设备:
cudaMemcpy()指定参数cudaMemcpyDeviceToDevice
The communication between CPU and GPU is asynchronous for high performance. So need to use the synchronous mechnisms for them.
Function type
__host____global____device__
| function type \ action | Callable from | Executed on |
|---|---|---|
__global__ | host / divice(compute capability 5.0 or higher) | device |
__device__ | device | device |
__host__ | host | host |
Without any of the __host__, __device__, or __global__ specifier is equivalent only the __host__ specifier.
Some special usage:
The
__global__and__device__execution space specifiers cannot be used together.The
__global__and__host__execution space specifiers cannot be used together.The
__device__and__host__execution space specifiers can be used together.(This usage is used to decrease the verbose codes, the compiler will compile the function for host and device seperately)
More informations please see the official station.
Common Parallelization methods
Grid-stride loop
This method is used to solve the problem, the parallelism(并行度) is more than the quantity of threads.
In some situations, we can create many threads so that satisfied the parallelism, that we can allocate a separate thread for every threads.
But if the parallelism is more than the quantity of threads and we still use the above strategy, we will get the following result.
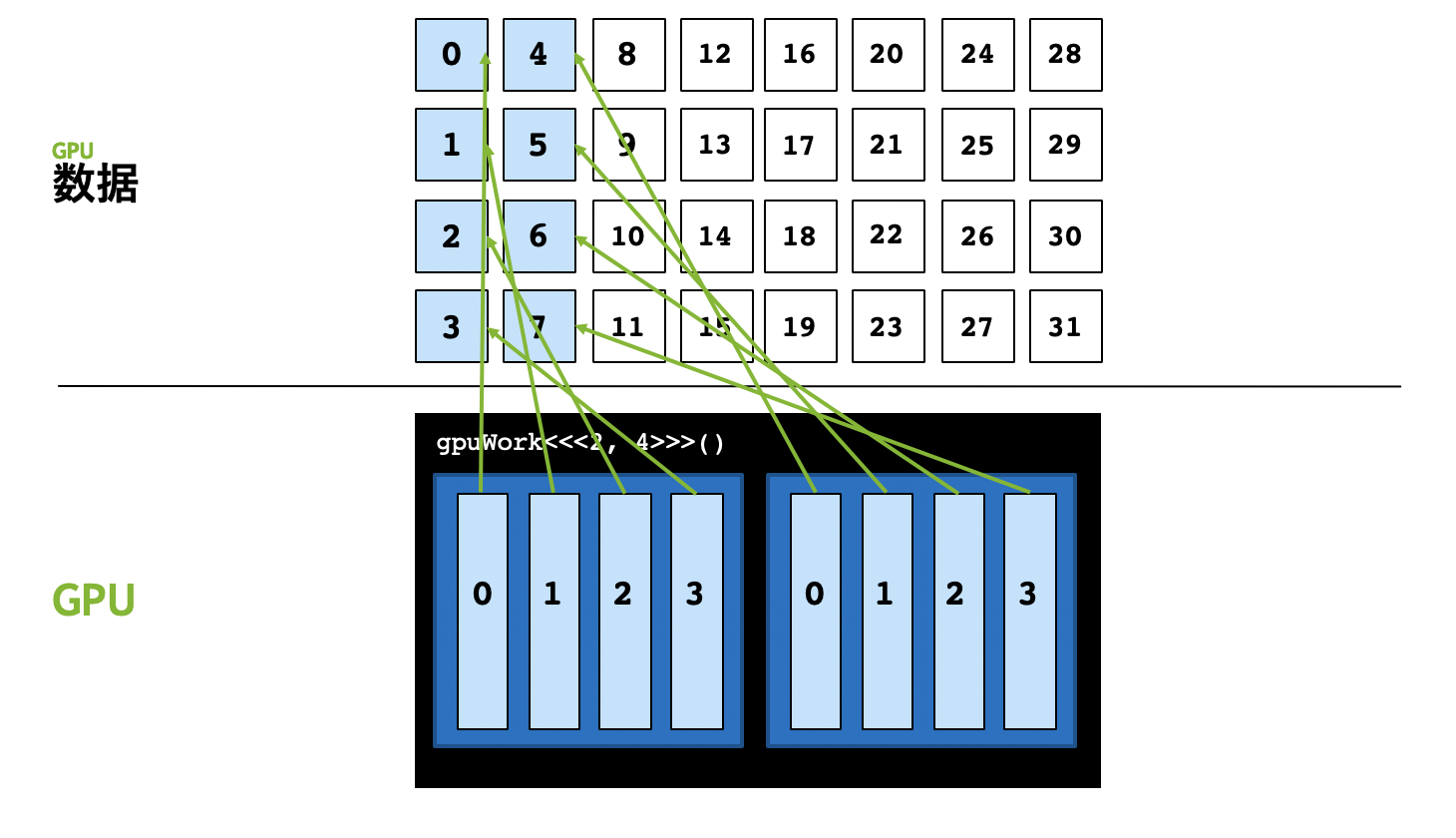
The parallelism is 32, but we just have 8 threads, we can’t allocate a separate thread for every threads.
Grid-stride loop provide a new approach to solve this problem. At first, we studt the content of this method and we will think the core principle of this method. The process of grid-stride loop looks like the following figure.
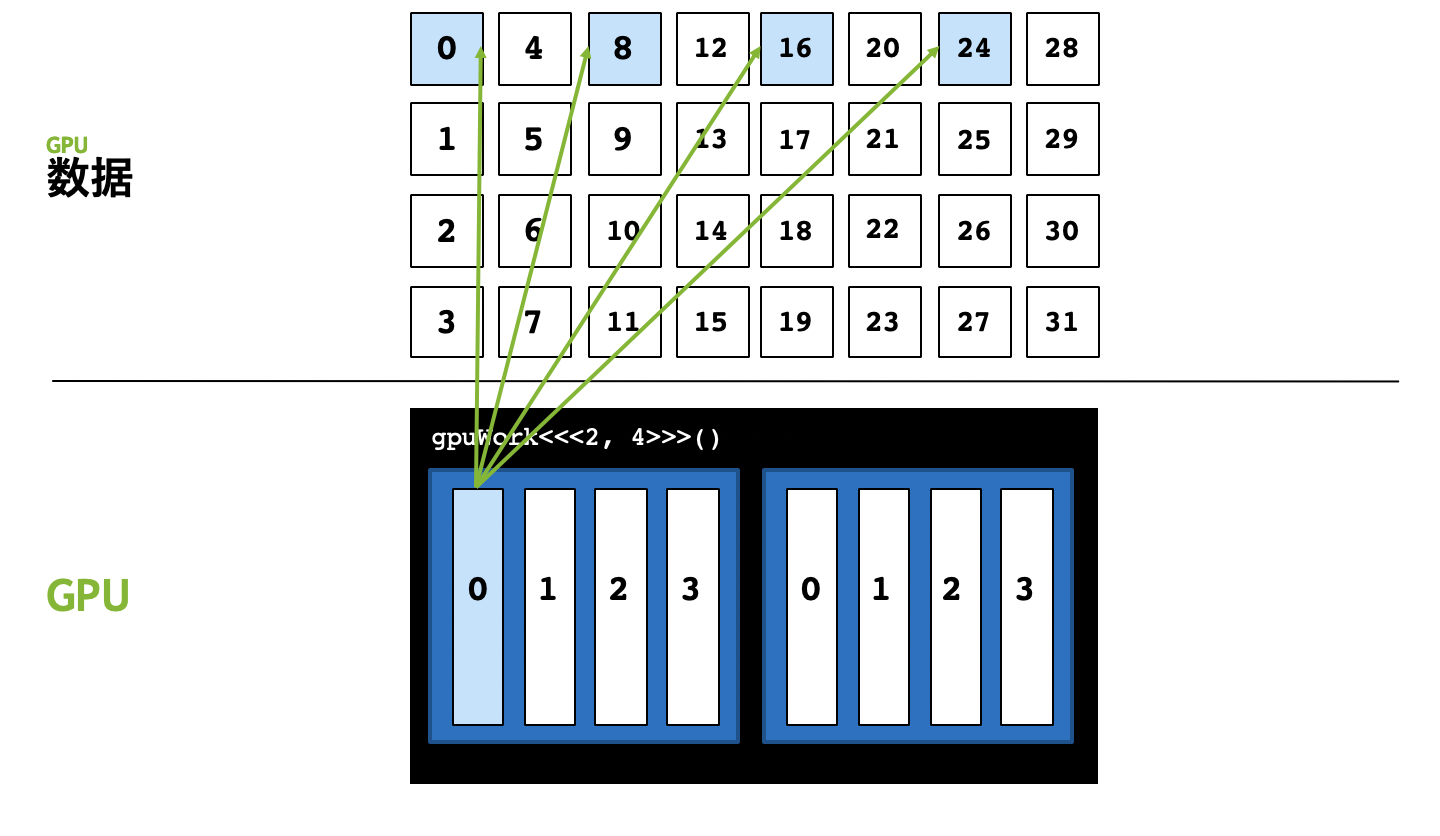
In short, the core approach to implement it is for (size_t i = threadIdx.x; i < n; i += <total number of threads>. When the number of threads is smaller than parallelism, we can’t use the traditional method to implement the parallel, simply speaking, the distribution of thread can’t satisfied the parallelism.
Grid-stride loop uses
Fixed location solve the data conflict
The most obvious answer is using mutex or atomic operation. But as we all know, whether it’s mutex or atomic, they both have some consuming.
We know that the data conflict comes from shared data, different thread maybe use the same data at the same time. So an approach to avoid happening this problem is that control different threads use different data.
According to the process of Grid-stride loop, we notice that different threads use the different datas which have different locations. We can specify a fixed location to store a thread’s data to avoid using the mutex or atomic.
A good example is array summation. As the following code shows.
| |
Synchronization
CPU programing needs synchronous mechanism, GPU programing also needs it.
Atomic
We can learn about the execution logic by refering to C++ atomic and details of function by refering to CUDA C++ Programming Guide.
同步机制汇总
| 层级 | 关键指令 | 解决的问题 |
|---|---|---|
| Warp-level | bar.warp.sync, redux.sync | Warp 内 32 线程的数据交换与对齐 |
| CTA-level | bar, barrier | 线程块内不同 Warp 间的同步 |
| Cluster-level | mbarrier, barrier.cluster | 跨线程块数据访问与异步搬运同步 |
| Memory-level | membar, atom, red | 内存一致性与写冲突 |
| Control-level | griddepcontrol, elect.sync | 任务调度控制与逻辑流选举 |
bar 和 barrier 用于 CTA 内的同步控制,后者发布的时间要晚一些。通过这一指令可以实现 producer-consumer model
| |
这一指令有几点局限性:
- 只能指定 “logical barrier resource as an immediate constant or register with value 0 through 15 11",也就是说实际只是指定了在某一个标识下进行 0 或者 1 的变化,并不能指定其他数值
- 我们简单理解为这一标识信息只能在 CTA 内共享,因此它的同步行为只能发生在 CTA 内部
- 等待指令是阻塞的,这意味着我们一旦执行了
bar.sync,所有 thread 就只能阻塞在这里不能执行任何其他操作了
mbarrier [^mbarrier] 则完善了这几点局限性
- “mbarrier is a barrier created in shared memory”,这也就意味着它除了可以通过一个 CTA 内部的 thread,也可以跨 CTA 实现同步
- 不再局限于 16 个标识,并且每个标识可以设置初始值
- 等待可以是非阻塞的
关于等待是阻塞还是非阻塞的,有如下理解
目前了解的同步方式有两种 cp.async.wait_[group | all] 和 cp.async.mbarrier。
不带 mbarrier (旧模式): 你点了一份外卖(异步搬运),你必须每隔五分钟走到门口看一眼(线程 wait)。虽然你可以等到肚子饿了(需要数据)才去看,但在你看的时候,你除了看门口,什么也干不了。
带 mbarrier (Hopper 模式): 你点了一份外卖,给门口装了一个智能感应灯(mbarrier)。你回屋子里打游戏(做其他计算),灯亮了(mbarrier arrive)会自动给你手机发个通知。你不需要亲自去门口守着,甚至你可以同时点好几份外卖,每个外卖对应一个灯,谁亮了你就吃谁,互不干扰。
这两个模式的区别似乎是理解了的,但是还想不太好在实际代码中是如何运用的,而且感觉本质上还是当作信号量在使用,等待的话依然还是需要阻塞等待的吧
执行不同操作后对于 mbarrier 的操作方式是不同的。生产者在拷贝完成后执行的是 cp.async.mbarrier.arrive.noinc.shared::cta.b64 [%0];,消费者在消费完数据后执行的是 mbarrier.arrive.shared::cta.b64 _, [%0];。虽然从信号量的角度来说,二者都是使信号量增加,但是因为 TMA 指令的发射并不意味着拷贝操作的完成,而只有在完成后才可以增加信号量,因此前者是需要由硬件触发的,后者则是由 thread 手动触发的。
Asynchronization (CUDA stream)
Serialize data transfer and GPU computation causes that PCIe idle and GPU idel appear interleavly.
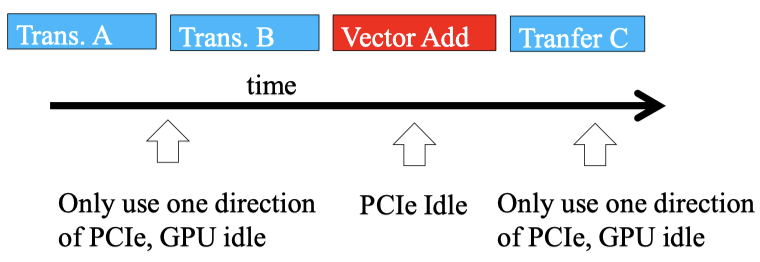
Most CUDA devices support device overlap. Because data transmission is more timeless than computation, so simultaneously execute a kernel while performing a copy between device and host memory can cover up the time consumation of data transmission.
CUDA supports parallel execution of kernels and cudaMemcpy with streams. A stream is a sequence of commands that execute in order.
The commands issued on a stream may execute when all the dependencies of the command are met. The dependencies could be previously launched commands on same stream or dependencies from other streams.
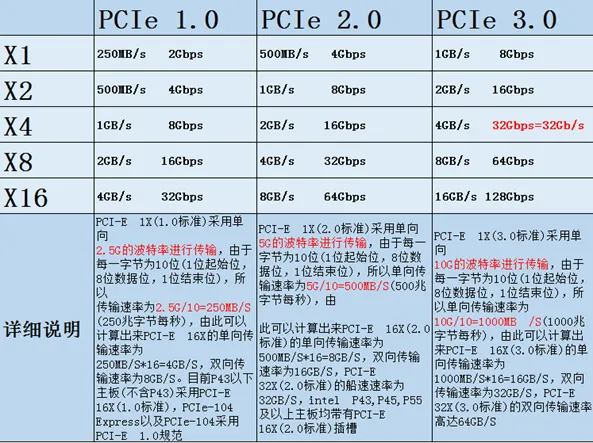
About the PCIe transmission rate is shown as the following picture:
流的分类:
- 根据发出方分类:
- Host端发出的流(主要讨论的是这种)
- Device端发出的流
- 根据有无内容分类:
- 默认流(default stream) / 空流(null stream)
- 明确指定的非空流
Execution order
同一个CUDA流中的操作是串行顺次执行的,不同stream中的operation随机执行,可能是并发交错执行的
Related API
__host__ cudaError_t cudaStreamCreate ( cudaStream_t* pStream )
Create an asynchronous stream.
__host__ __device__ cudaError_t cudaStreamDestroy ( cudaStream_t stream )
Destroys and cleans up an asynchronous stream.
__host__ cudaError_t cudaStreamQuery ( cudaStream_t stream )
Queries an asynchronous stream for completion status.
__host__ cudaError_t cudaStreamSynchronize ( cudaStream_t stream )
Waits for stream tasks to complete.
如何理解流
从主机和设备两个视角的动作来分析
使用cudaMemcpyAsync()时,Host memory必须是non-pageable memroy / pinned memory, 数据传输过程由GPU的DMA负责
如果是pageable memroy使用cudaMemcpyAsync(), 需要首先将pageable memory移动到pinned memory,这个过程中就会涉及到数据同步。
还有一个需要注意的事情就是PCIe,同一时刻H2D和D2H都只能进行1个操作。
C++ Encapsulation
As we all know, the style of many CUDA APIs is C-style, we need to learn about how to use it conjunction with C++.
How does the std::vector standard template library use the Device(GPU) memory ?
Many examples use the original pointer to point a Device memory. But if we want to use a std::vector or other standard template library that locates in Device memory, we can’t use the cudaMalloc() or cudaMallocManaged().
Taking the std::vector as an example, next, we will discuss the method of allocating Device memory for containers.
Whether it’s principle or usage methods is too complex to understand in a short time. So pause it for a period of time. When we must need to learn its principle we study it again. We can learn about it from 一篇文章搞懂STL中的空间配置器allocator. In short, std::allocator integrates the memory management and object management by using four member function.
GPU execution core
一个kernel函数在逻辑上以block为单位映射到SM中,物理上以warp为单位解析指令将指令分发到具体的运算单元(SP/core, SFU, DP)或访存单元(LD/ST)。 SM中活动的warp数量占物理warp数量的比率为occupancy(占用率)。
Device API
__host__ __device__ cudaError_t cudaGetDeviceCount ( int* count )
Returns the number of compute-capable devices.
__host__ cudaError_t cudaGetDeviceProperties ( cudaDeviceProp* prop, int device )
Returns information about the compute-device.
__host__ cudaError_t cudaSetDevice ( int device )
Set device to be used for GPU executions.
More information please see the official website.
Three are three ways to transfer data from one device to another:
cudaMemcpyPeerAsync()cudaMemcpy(): rely on the unified address system- Implicit peer memory access performed by the driver
CUDA Libraries
cuBLAS
cuSOLVER
cuFFT
Thrust
- Three main functionalities
- The host and device vector containers
- A collection of parallel primitives such as, sort, reduce and transformations
- Fancy iterators
CUDA Compilation
For detailed information, please refer to this article.
GPGPU-Sim
How to run
- Use the command
lddto make sure the application’s executable file is dynamically linked to CUDA runtime library - Copy the contents of configs/QuadroFX5800/ or configs/GTX480/ to your application’s working directory.
These files configure the microarchitecture models to resemble the respective GPGPU architectures.
- Run a CUDA application on the simulator
source setup_environment <build_type>
Source code organization structure
Gpgpu-sim的源码位于gpgpu-sim_distribution/src/gpgpu-sim。
目前,我们主要关注其中和配置相关的内容,我们通过修改gpgpu-simi的源码(增加一个配置项),重新编译并用其执行程序来简单理解gpgpu-sim对于配置项的设置方式。
- 修改
gpu-sim.cc:gpgpu_sim_config::reg_options(),在其中添加一个配置项
| |
- 修改
gpu-sim.h,在配置项对应结构体中添加对应字段
| |
- 重新编译gpgpu-sim项目
- 将编译后生成的
gpgpusim.config拷贝到待执行cuda程序路径下 - 修改待执行cuda程序路径下的
gpgpusim.config配置文件,添加配置项
| |
- 执行cuda程序,在输出信息中就可以看到新增的配置项
| |
Reference
附加内容:
- If want to use ptxplus (native ISA) change the following options in the configuration file
-gpgpu_ptx_use_cuobjdump 1 -gpgpu_ptx_convert_to_ptxplus 1
- If want to use GPUWatch change the following options in the configuration file
-power_simulation_enabled 1 (1=Enabled, 0=Not enabled) -gpuwattch_xml_file
.xml
Related Programming Models

就目前了解到的 OpenACC 和 OpenMP 是由编译器提出的一种叫做Offloading的机制实现的
- OpenCL
Open Computing Language
- OpenACC
Open Accelerators
OpenACC is a feature of the compiler, so we don’t need to install it if we want use it. More details please see the gnu official website.
- OpenMP
Open Multi-Processing
Reference to the memroy modle of OpenMP, we can get the following information: “The OpenMP API provides a relaxed-consistency, shared-memory model.”
threaded parallelism
虽然OpenMP只能用于单机,但是可以处理单机上的多卡
OpenMP is a feature of the compiler, so we don’t need to install it if we want use it. More details please see the gnu official website.
- MPI
Message Passing Interface
MPI可以理解为是一种独立于语言的信息传递标准, 本身和代码没有关系,可以看为是一种规定。 OpenMPI和MPICH等编程模型是对这种标准的具体实现。也就是说,OpenMPI和MPICH这类库是具体用代码实现了MPI标准。因此我们需要安装OpenMPI或者MPICH去实现我们所学的MPI的信息传递标准。
process parallelism
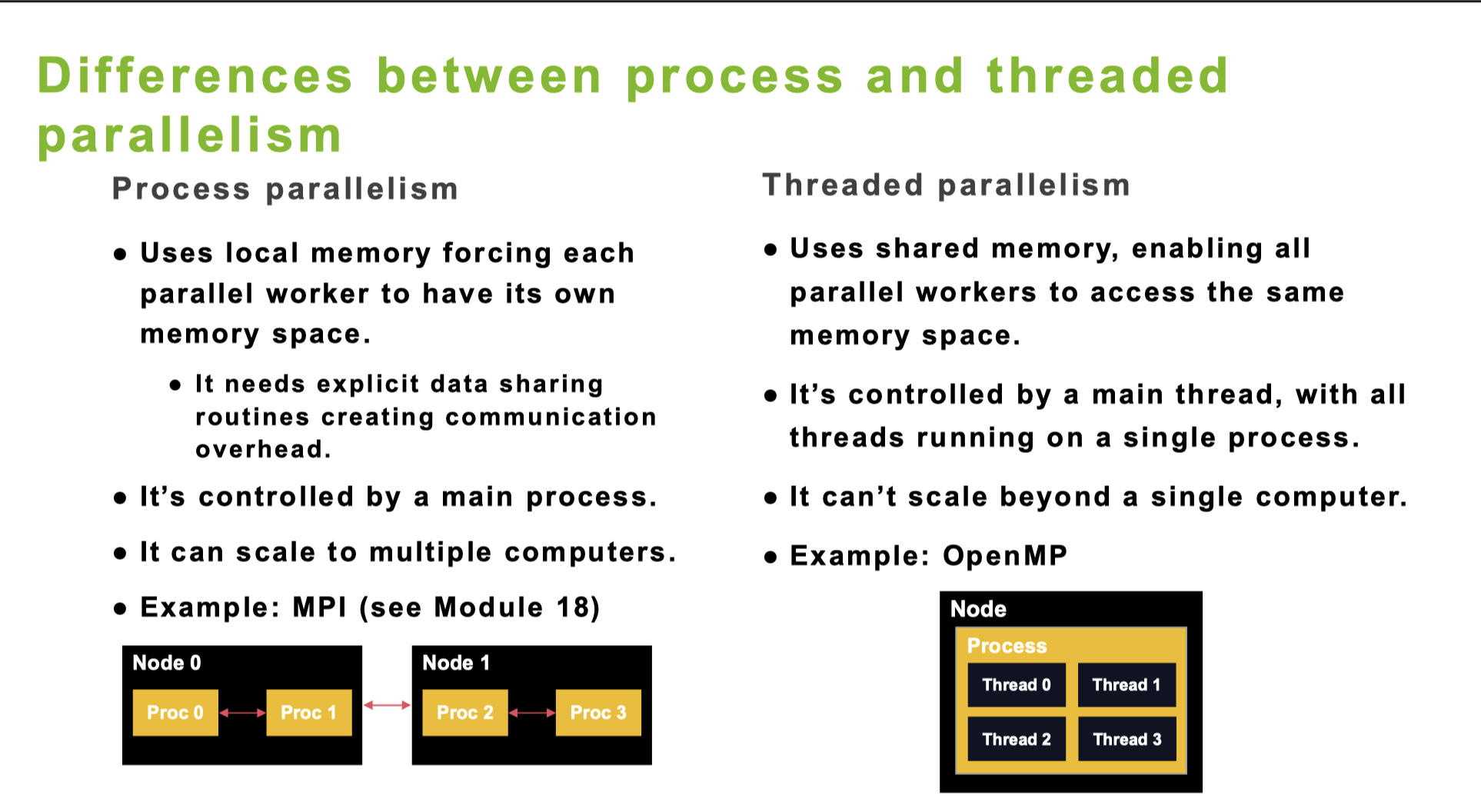
如何使用CUDA加速程序
目前理解到的CUDA加速程序的两个关键问题是:
- 任务并行化 寻找到任务中可以并行完成的部分,制定某种策略将任务合理分配到每个线程中。此过程期望解决的是计算瓶颈(cpu-bound)问题。
1.1 udacity的视频主要讲解的就是这部分 1.2 小彭课程第6讲也是这部分 主要就是讲解一些并行原语
- 访存优化 此过程期望解决的是内存瓶颈(memory-bound)问题。
2.1 gpu的存储模型(《大众高性能》) 2.2 小彭课程第7讲
公共概念
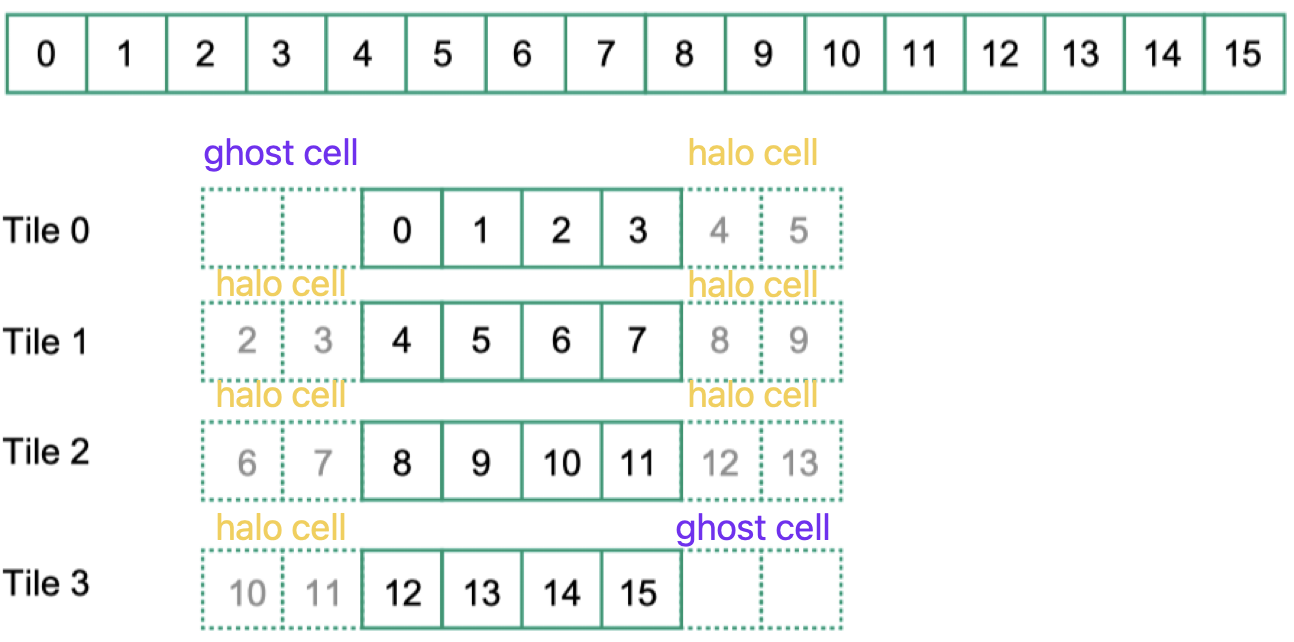
- 在使用 tile 的算法中,存在 ghost cell 和 halo cell / skirt cell,按照目前的理解,前者指的是实际不存在元素,后者指的是实际存在,但是不在当前 tile 范围内的元素。下面以 tiled 1D convolution 为例来说明它们的实际指向
对任务划分的理解
想要实现并行化,很重要的一点是考虑“如何合理地将任务划分到不同的thread上”
如何选择grid和block的规模,除了考虑以上合理的任务划分之外,还可以从性能的角度进行考量。 如果仅从下图内容来看,block规模的确定要更为重要,grid的规模只需要根据任务划分和block规模来确定即可

矩阵乘法
- SGEMM
Single-precision General Matrix Multiply 单精度通用矩阵乘法
- DGEMM
Double-precision General Matrix Multiply 双精度通用矩阵乘法
- CGEMM
Complex-single-precision General Matrix Multiply 复数单精度通用矩阵乘法
- ZGEMM
Complex-double-precision General Matrix Multiply 复数双精度矩阵乘法
目前感觉从具体的算子入门CUDA编程中的各种概念、并行算法、访存优化的手段是个非常好的方式,因为各种算法,访存优化一定都是基于实际的应用场景而出现的,都不是仅仅的概念本身
把thread都放置在同一个block中的缺点在于,SM无法对block进行调度,原本的两层调度:block调度和warp调度,现在就只剩下一个warp调度了
native implementation 的核心问题是:计算访存比过低,即使将global memory替换为shared memory,访存时间占比仍然远大于计算时间占比。所以才会考虑矩阵分块
Tiled Matrix Multiplication
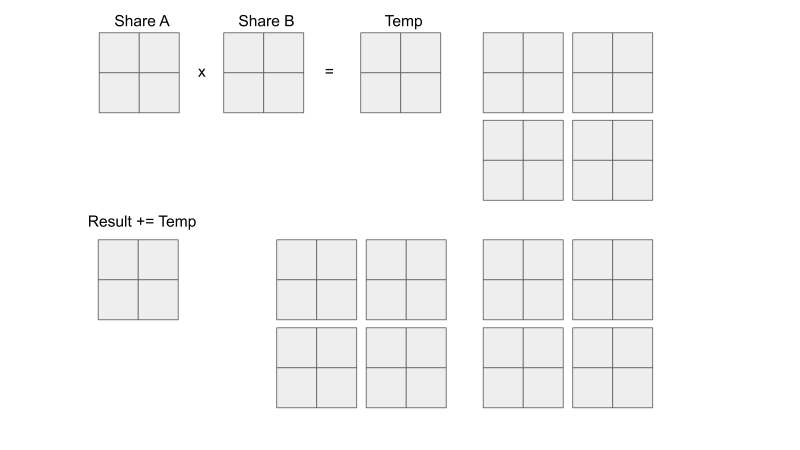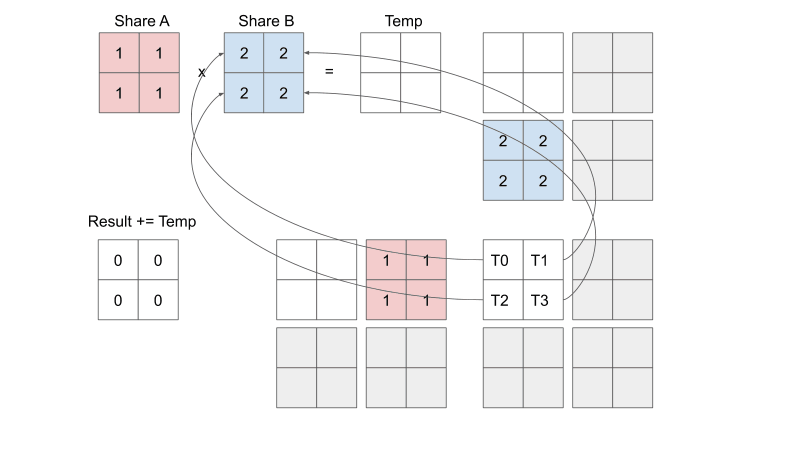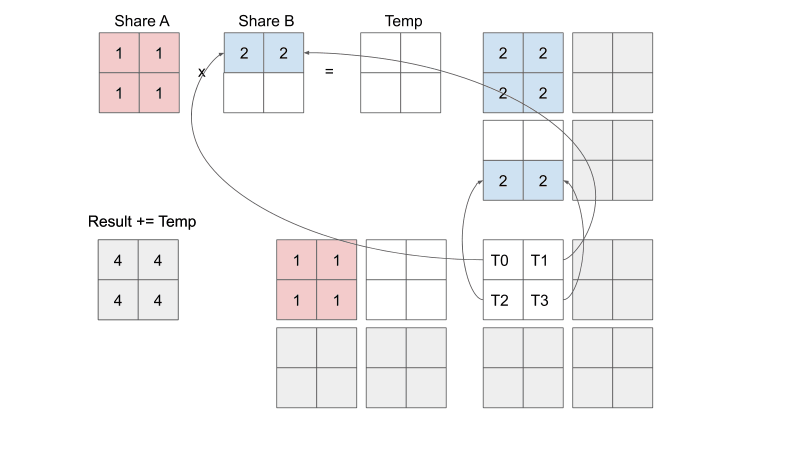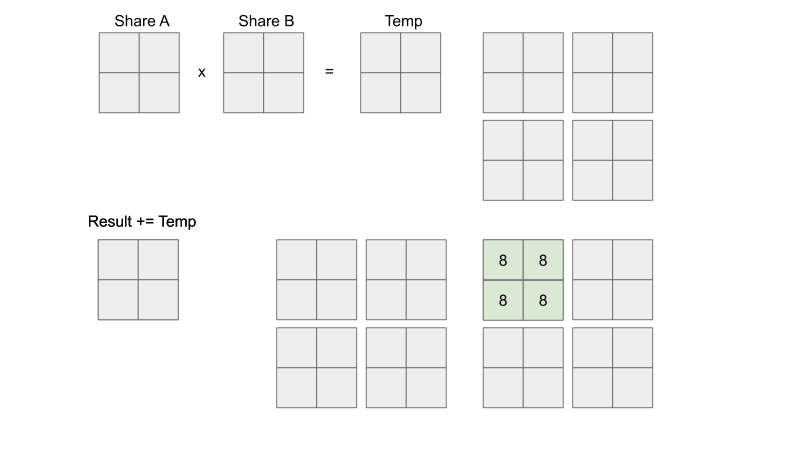
tiled matrix multiplication之所以减小了对内存带宽的要求,是因为一个thread读取的内容是可以被其他thread共享的。在分tile之前,一个thread从global memory读取的数据只会让它自己使用,但是分了tile之,一个thread从global memory加载的数据也可以被处于同一个tile中的其他thread所访问,增加了数据重用率。
More information please see the original passage Tiled Matrix Multiplication.
Reference
Reduction
Convolution
understand of convolution
在 很详细的讲解什么以及为什么是卷积 一文中,作者从物理意义的角度解释了信号处理中的卷积操作
卷积操作的核心目的在于计算某一时刻下全局的信号强度值。具体的过程包括 “卷” 和 “积” 两个过程,系统响应函数 g 可以看为信号衰减的变化函数曲线,把 g 翻转过来并且平移的过程刚好遵循了信号衰减的变化情况。积的原因在于某一时刻下全局的信号强度值不仅和某一时刻的信号相关,还和此前的还未衰减完成的信号强度相关,所以实际需要进行累加操作。
卷积这块有一个神奇的题目和神奇的公式:
问: kD convolution 过程中(不考虑ghost elements的运算),每个元素的平均访问次数
答: 平均访问次数=$\frac{output_{width}^k \times mask_{width}^k}{input_{width}^k}$
其中,在$stride=1$的情况下,满足$output_{width} = input_{width} - mask_{width} + 1$,即$input_{width} = output_{width} + mask_{width} - 1$
2D convolution上述公式的验证代码如下:
| |
Tiled 1D Convolution
边界处理:
- 判断法
- 扩展法
背景介绍
- 假定每个thread处理一个output element
- 每一个block要处理的部分称为一个input tile, 生成的部分称为一个output tile
Common calculation formula
下图包含了一些常见概念的对应关系。
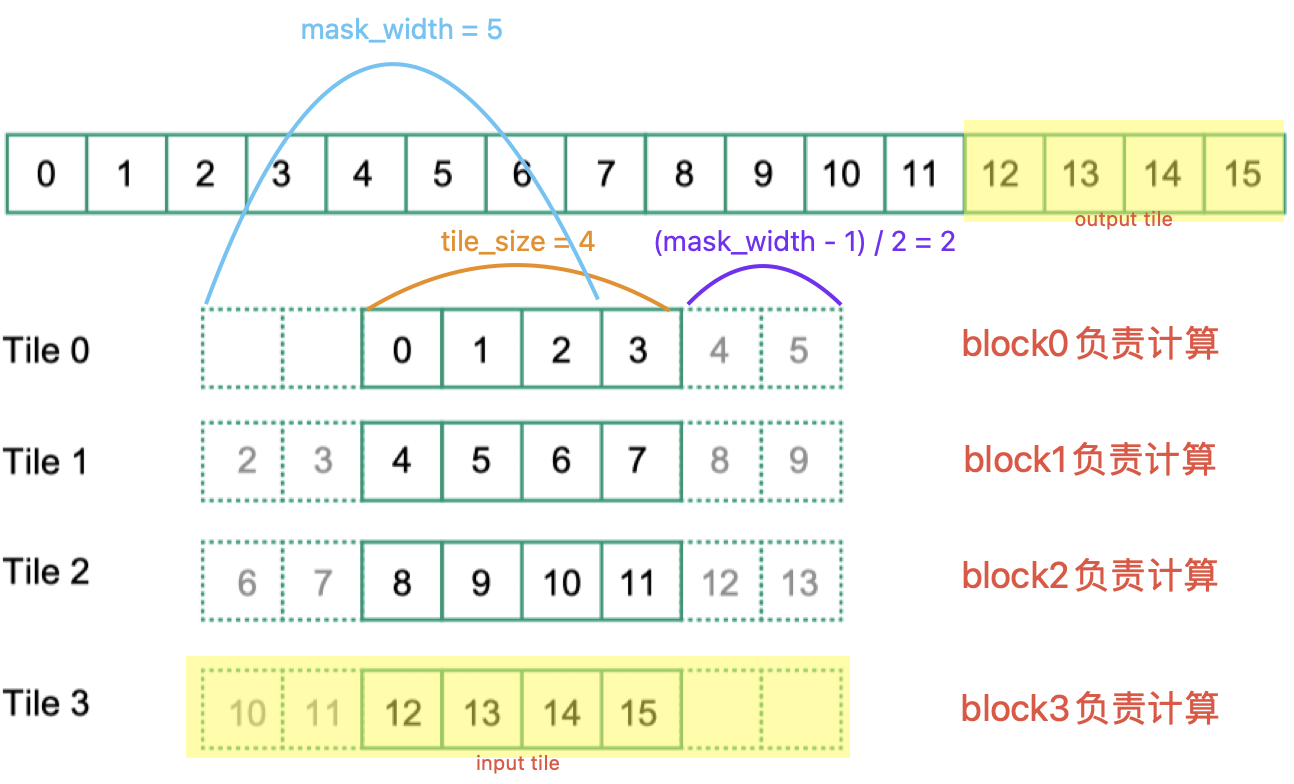
- $input \ tile \ width = output \ tile \ width + \frac{mask \ width - 1}{2} \times 2 = output \ tile \ width + (mask \ width - 1)$
需要额外关注的一点是,有一些题目会给定 output tile width 和 mask width,要求计算input tile width,这类题目一般认为 input tile 是包含 helo cells 的,也就是下图中黄色部分标注的内容,其对应的output tile是下图中上方的黄色部分标注的内容。
Two tiled strategy
- Strategy-1 (most intuitive): loading all input data elements into the shared memory, which is needed for calculating all output elements of a thread block
这种方式存在的问题是,存在重复的 global memory 的访问。按照现在的划分方式,每一个 tile 都对应着一个 block, 而不同 block 对应的 shared memory 是不同的,因此 tile1 中的 2 和 3 号元素,虽然在 加载 tile0 时已经被加载到shared memory中了,但是存储 tile0 的 shared memory 和存储 tile1 的 shared memory 是不同的存储空间,因此 2 和 3 号元素需要从 global memory 中访问 2 次。
如果只使用一个 block 来计算确实可以解决重复访问的问题,但是仅使用一个 block,无法充分利用大量的 SM(CUDA 中采用的 2 种 scheduling:block scheduling 和 warp scheduling,只使用一个 block 就无法充分进行 block scheduling 了)
Performance Evaluation 所谓的性能评估就是分别计算一下采用 tile 和不采用 tile 时 global memory 的访问次数。注意以下在分析时,均只分析一个 block 的访存情况
- basic 1D convolution
| |
为了绘图的方便,这里假设采用的 mask width 为 5,即左右两侧会各出现 2 个 ghost cell

假设 ghost cell 不需要读取 global memory。考虑一种计算方式:假设 ghost cell 需要读取 global memory,计算总的访存次数,然后减去 ghost cell 涉及到的访存次数。
- 总的访存次数
每一个 output element 对应的访存次数为 mask width 次。因此每一个 thread block 的访存次数为 $blockDim.x \times mask \ width$
- ghost cell 涉及到的访存次数
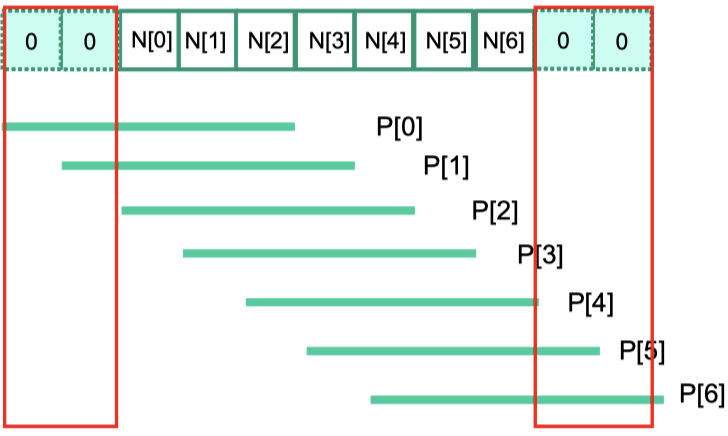
首先只考虑最左侧的 ghost cell 的访存情况,最左侧的 cell 只有一个 output element 的计算才会涉及,每往右侧走一个涉及到的访问次数就会加 1,最左侧的 ghost cells 的最右侧一个,涉及的次数是$\frac{mask \ width - 1}{2}$
因此再考虑上右侧,全部ghost cell 涉及的访存次数为 $(1 + 2 + \dots + \frac{mask \ width - 1}{2}) \times 2 = \sum_{i=1}^{\frac{mask \ width - 1}{2}}(i) \times 2$
- tiled 1D convolution
| |
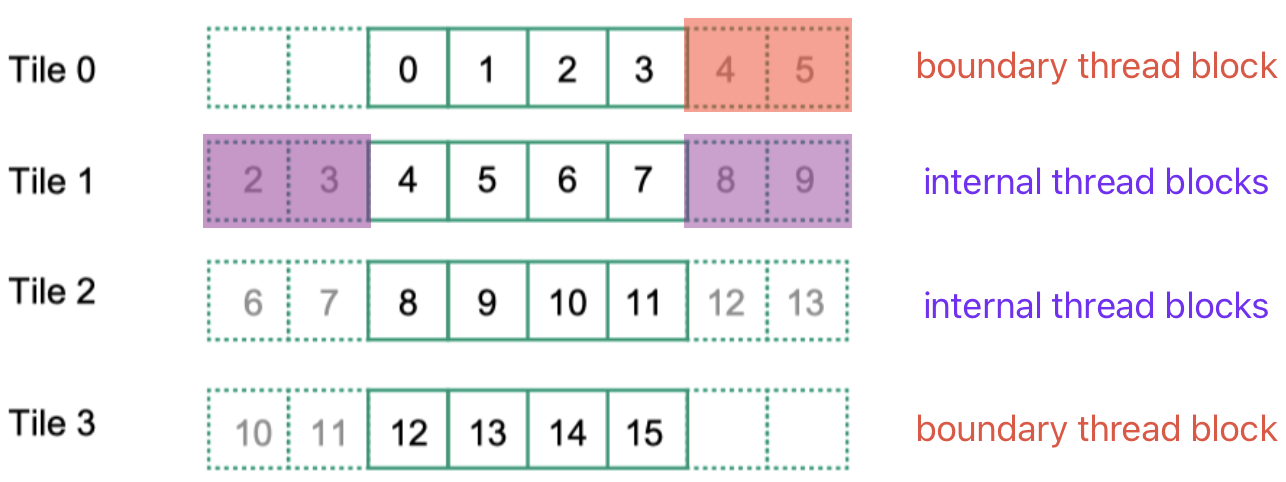
此时的代码分析起来有点困难,但是计算要简单很多,因为除了 ghost cells 不用访存,helo cells 访存2次,其余 cell 都只需要访存 1 次
- 对于 boundary thread block 来说,访存次数为 $blockDim.x + \frac{mask \ width - 1}{2}$
- 对于 internal thread block 来说,访存次数为 $blockDim.x + 2 \times \frac{mask \ width - 1}{2}$
2D Convolution
想要使用 shared memory 来降低 DRAM(global memory)的访问次数,加载到 shared memory 中的数据必须发生数据重用。我理解着只有一个block多对应一些数据,就会包含一些数据重用了。
3D Convolutoin
GPU Microarchitecture(SIMT Core)
The microarchitecture of the GPU pipeline is divided into a SIMT front-end and a SIMD back-end.
The GPU pipeline consists of three scheduling “loops”:
- instruction fetch loop: Fetch, I-Cache, Decode, and I-Buffer
- instruction issue loop: I-Buffer, Scoreboard, Issue, and SIMT Stack
- register access scheduling loop: Operand Collector, ALU, and Memory
注意蓝色和橙色部分存在I-Buffer的交叉
在讲述One/Two/Three-Loop Approximation之前,需要明确的是我们要分析的是SIMT Core的结构,要考虑的问题是如何统筹规划每一个warp所要执行的指令。这一点前提认知很重要,会直接影响到对后面一些结构的理解。
还有一个比较重要的事情,就是弄清楚这里说的one,two,three到底指的是什么,目前理解指的是3种scheduler,分别是SIMT stack, Scoreboard 和 Operand Collector.
One-Loop Approximation
SIMT stack
The SIMT stack is used to solve the thread divergence. It sends the target PC to the fetch unit and the active mask to the issue unit.
- The fetch unit is used to control which instruction is fetched next.
- The issue unit is used to control which lanes of the warp are active.
The mask is a bit vector with 1 for every thread that is active for the corresponding control flow branch. When that control flow branch is being executed, only the threads with 1 in the corresponding branch bit execute those instructions.
A simple method to address the control divergence is PDOM mechanism(post-dominator stack-based reconvergence mechanism). The post-dominator active mask has 1 for every thread that is active in each of the divergent paths that reconverge at that point.
When we hit a divergent point, we push on the stack:
- (1) the current active mask and the next PC at the reconverge point;
虽然这里说的是current active mask,但是current active mask和 reconverge point 的active mask实际是一样的
- (2) the active mask, PC, and reconverge PC for every branch.
如果有多个branch,入栈的先后顺序一般采取 the entry with the most active threads first and then the entry with fewer active threads。我的理解是thread越多越有可能引入新的branch,所以优先让较少thread先执行,避免使局面变得更加混乱。由于栈是FILO,所以the entry with fewer active threads后入栈.不过这只是一般做法,并非强制要求。
For example, look at the following picture, we hit a divergent point A
- (1) the current active mask / reconverge point active mask is 1111, and the reconverge point is G
- (2) the branch of this divergent point A contains B and F
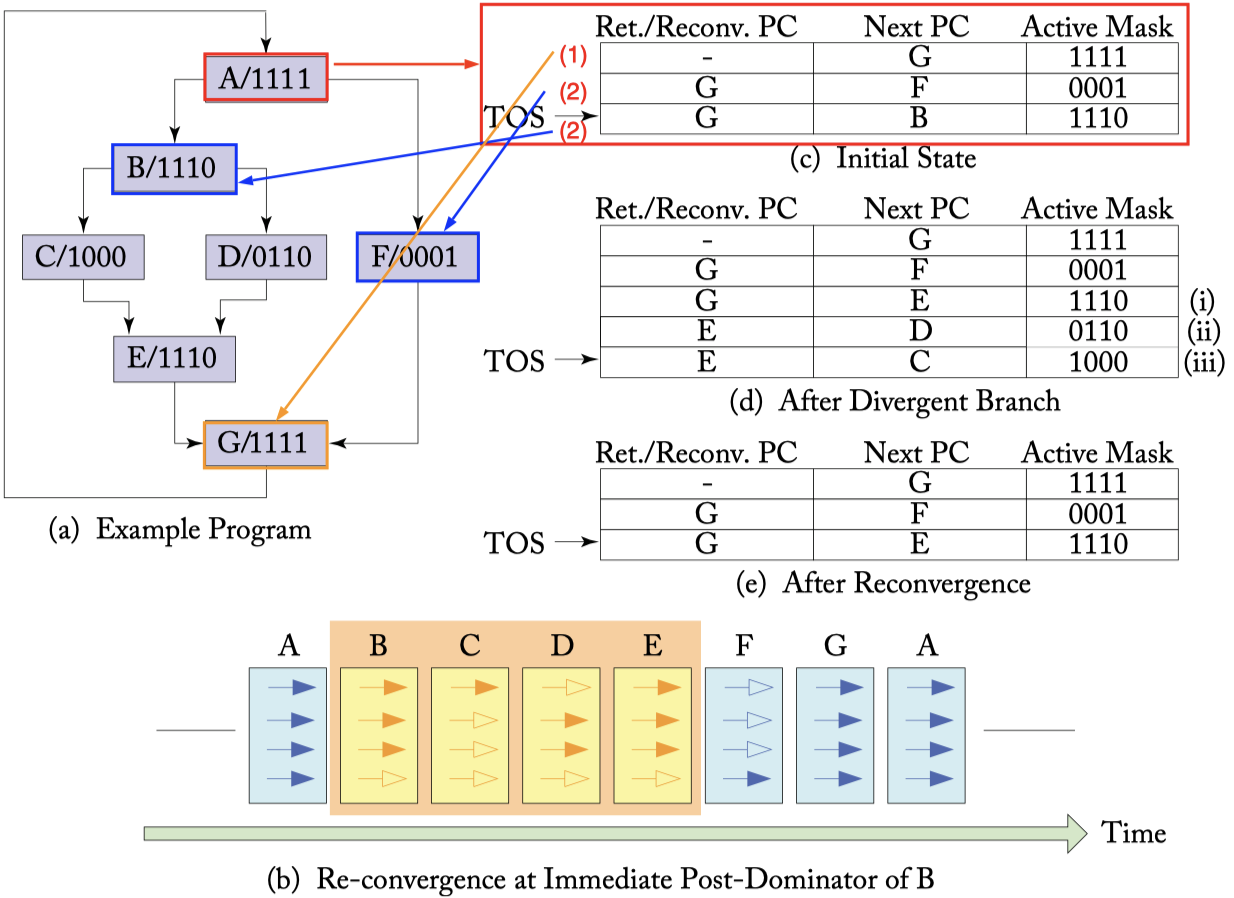
关于(2)中不同branch入栈的顺序,下图B分支点处采用的是一般的原则,A处则和一般原则相反
以上我们只讲述了SIMT stack是怎么使用的,现在思考一下它到底起到了什么作用,我们为何需要引入这样一种结构
观察上图中的(b)部分,不难发现程序的执行流从(a)那种复杂的形式,已经转变为了(b)中这种串行的方式。每个cycle执行一条指令即可,所以引入stack的目标就是 To achieve this serialization of divergent code paths one approach.
The SIMT stack helps efficiently handle two key issues that occur when all threads can execute independently:
- nested control flow
- skipping computation
a warp is eligible to issue an instruction if it has a valid and ready (according to the scoreboard) in the I-Buffer.
SIMT deadlock
What is the SIMT deadlock problem?
| |
上述代码中包含一个分支, 考虑在使用 SIMT-stack 时的场景
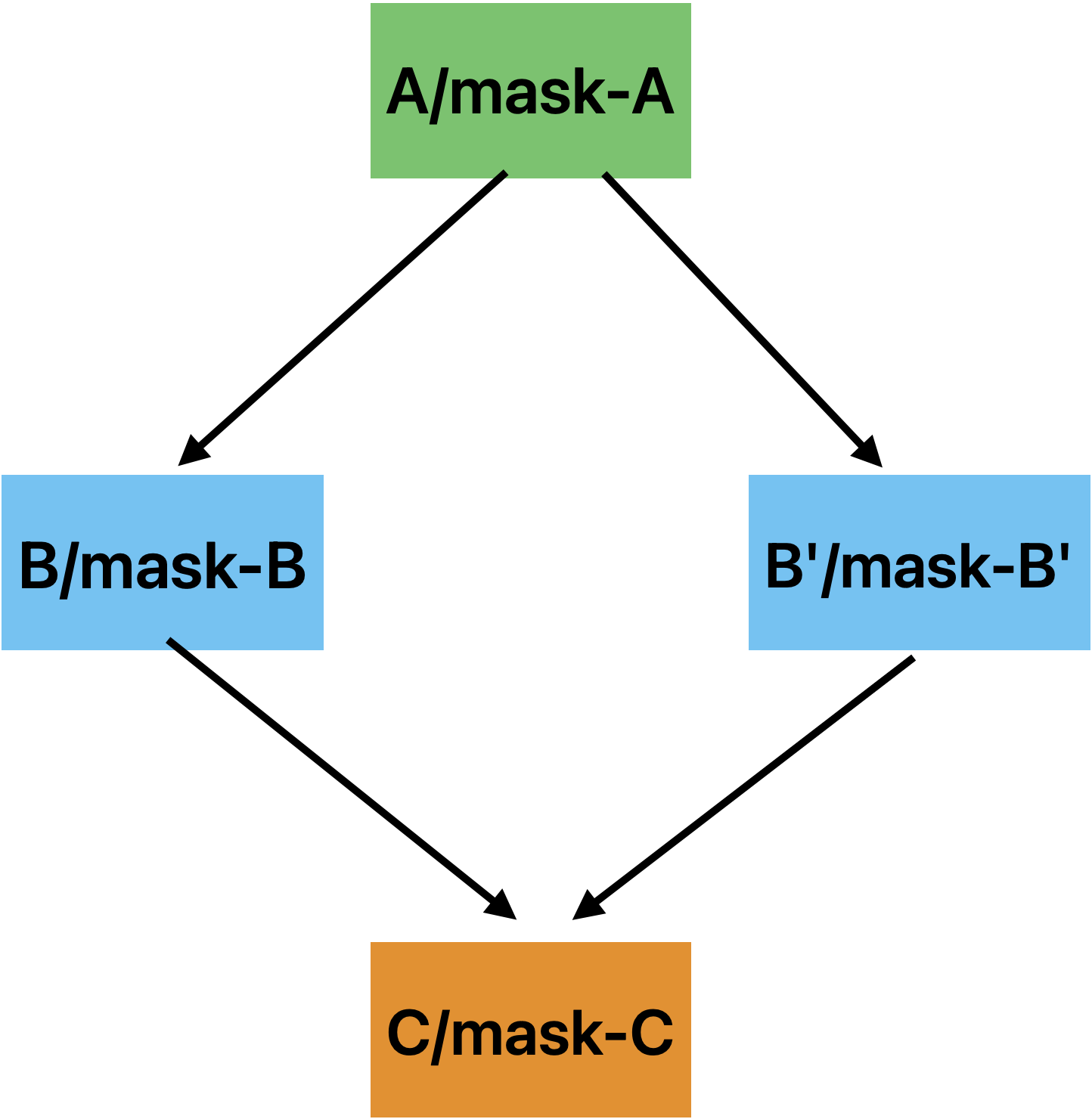
图中B表示条件命中,B’表示条件不命中
SIMT-stack内容如下
| Ret/Reconv PC | Next PC | Active Mask |
|---|---|---|
| - | C | mask-A / mask-C |
| C | B' | mask-B' |
| C | B | mask-B |
最下方一行是TOS(top of stack)
根据SIMT stack的内容,首先弹栈会让第一个命中的thread退出循环,它通过atomicCAS()将mutex修改为了1。然后SIMT stack会继续弹栈,这时候其他thread开始执行。但是问题在于现在还没有把C弹栈,所以mutex还没有被改回0,而现在正在执行的指令必须等到mutex等于0后才可以正常执行从而推出循环,而它们不执行完,SIMT stack就不会继续弹栈。这就造成了死锁。
A mechanism for avoiding SIMT deadlock stackless branch reconvergence mechanism
Assuming a warp contains 32 threads, the barrier participation mask is 32-bits wide.
If a bit is set, that means the corresponding thread in the warp participates in this convergence barrier
The barrier participation mask is used by the warp scheduler to stop threads at a specific convergence barrier
Two-Loop Approximation
The problem of One-Loop Approximation is that it assumes that the warp will not issue another instruction until the first instruction completes execution, so maybe it will cause a long execution latencies.
A method to address this problem is that issue a subsequent instruction from a warp while earlier instructions have not yet completed, but it will face a new problem, we don’t know whether the next instruction to issue for the warp has a dependency upon an earlier instruction that has not yet completed execution.
So a separate scheduler is introduced, it is used to decide which of several instructions in the instruction buffer should be issued next to the rest of the pipeline to avoid dependency problem.
总结一下,简单来说,所谓的two-loop approximation不过是面对one-loop approximation所遇到的问题,考虑额外添加一个调度器,在前一条指令还没有执行完毕时就能够发射其他指令以类似流水线的方式执行从而可以增加指令吞吐量,但是遇到一个依赖性的问题,可能还没有执行的指令和要发射的指令存在数据相关,所以就引入了计分板来尝试解决这个问题,然后又发现单纯使用计分板同样遇到了一些问题,然后就有一个大佬提出了一种解决方案。这整个过程就是一个发现问题,然后解决问题的循环。
Scoreboard
Scoreboards can be designed to support either in-order execution or out-of-order execution.
Scoreboarding keeps track of dependencies to make sure we do not allow an instruction to start executing if there is a dependency with a previous instruction that is still executing. As the following example shows:
| |
- After the first instruction issues, we mark r3 as unavailable.
- When the sub instruction arrives, it cannot issue since r3 is not ready (RAW).
- After the first instruction completes, sub now can read the new value of r3 and issue, marking r5 which is the destination register as unavailable.
- The third instruction cannot issue since it writes to r5 (WAW).
Please note that in the above example, we issue in order: the read has already read the register values when we issue the write after it. So there is no WAR.
The two problem and solve method of the above implementation of scoreboard is used in in-order execution
- The simple in-order scoreboard design needs too many storage space
Solution: change the implementation of scoreboard
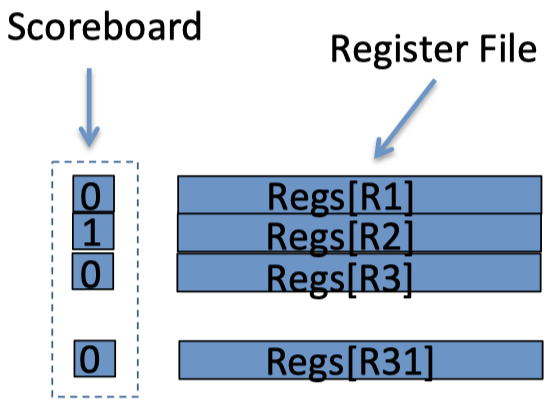
- The original way is hold a single bit per register per warp(每个warp都有一个完整的下图的结构), it looks like the following picture
- Now, the design contains a small number of entries per warp(每个warp一个bit vector), where each entry is the identifier of a register. It looks like the following picture
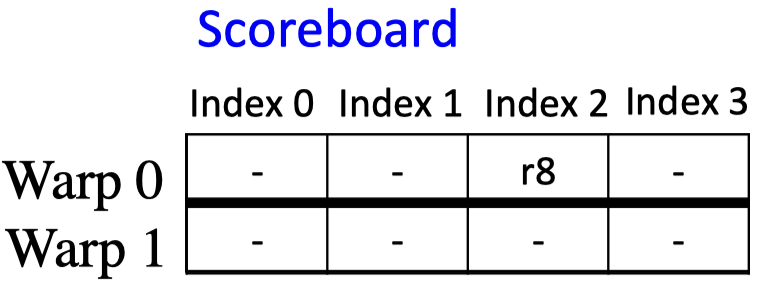
- If an instruction that encounters a dependency must repeatedly lookup its operands in the scoreboard until the prior instruction it depends upon writes its results to the register file. It consumes too many computation resources
首先可以确定的一点在计分板结构改变后,维护计分板内容的方式也发生了改变。根据书上说的,改变了修改计分板的时机。我现在对于解决这个问题大致的一个理解是,计分板和指令buffer是两个分离的结构,当一条指令执行结束后会修改计分板的内容,然后顺便把指令buffer中对应存在依赖的寄存器标记清空,这样在从指令buffer中取指令的时候拿到的就是新的状态,如果从指令buffer中读取到的指令不存在对于某个寄存器的依赖时就去执行这一指令,如果存在就换别的执行,不过这块的逻辑还没有看的太明白。
Three-Loop Approximation
Operand Collector
为了隐藏长时间的内存访问延迟,一种方法就是实现以周期为单位对warp进行切换,通过warp切换来掩盖延迟。
为了实现这一点,就需要使用较大的 registers file。而 registers file最朴素的实现方式就是 one port per operand per instruction issued per cycle, 但是这样我理解着是只能串行访问,吞吐量比较低。所以一种方式就是划分bank,不同bank可以做到并行访问,从而增大并行度。
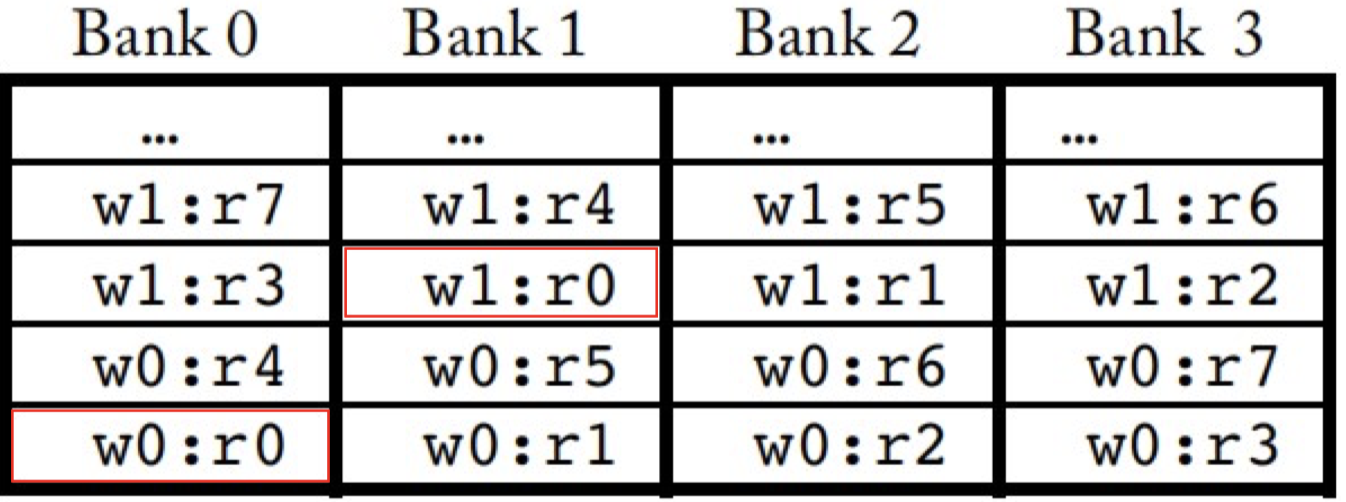
引入了 bank,同时也就引入了bank conflict, 下图的naive microarchitecture就具有这种问题,设计operand collector也正是为了解决这种问题, operand collector就是引入的第3个scheduler,完成指令在并行访问寄存器堆时的调度工作。
naive microarchitecture for providing increased register file bandwidth(by single-ported logical banks of registers)
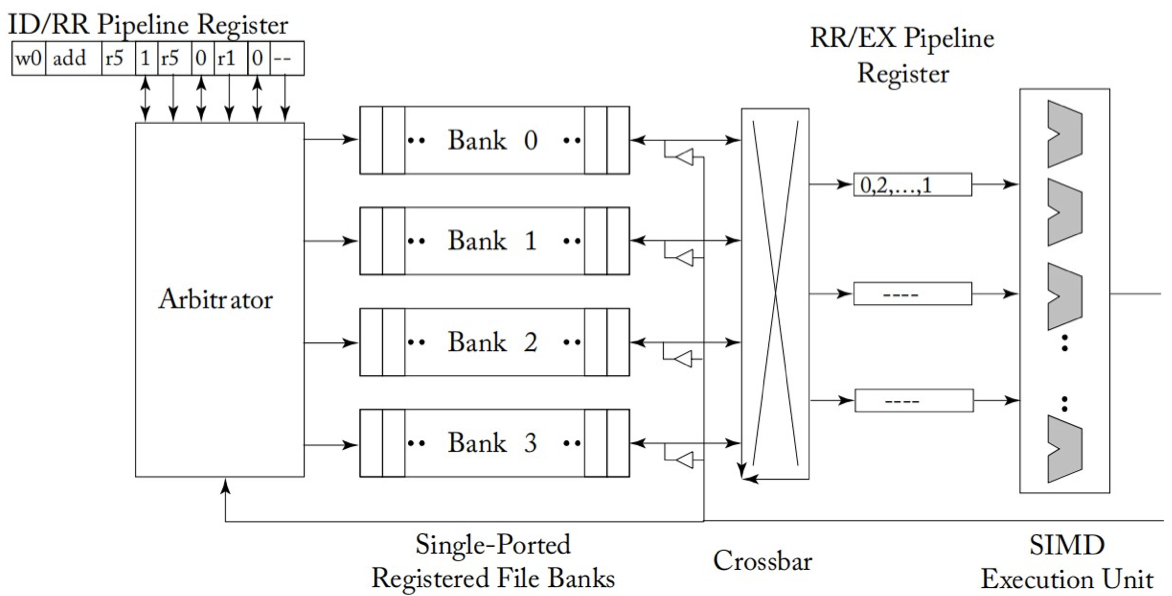
operand collector microarchitecture(the staging registers have been replaced with collector units)
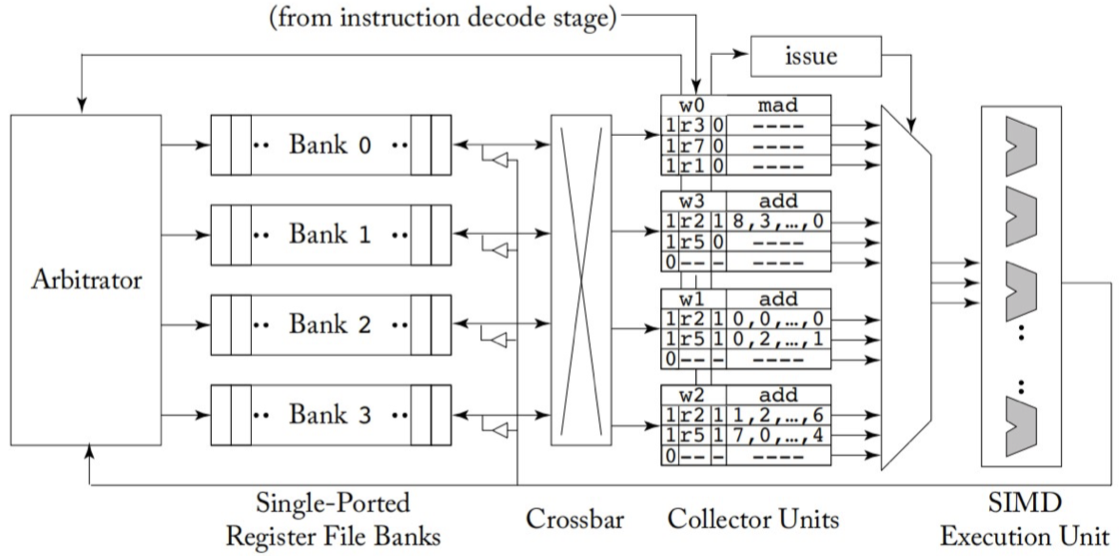
operand collector究竟是怎么调度的似乎书上并没有详细描述,只是给了一种新的从 register 到 bank 的映射方式(如下图所示),确保不同 warp 原来会被分到同一个 bank 的register 现在会被分到不同bank,但是同一个 warp 内不同 thread 之间的 bank conflict 并没有解决, 也就是它只对减少不同 warp 间的 bank conflict 起到了作用。
具有 WAR hazard, 3种可能的解决方法:
- release-on-commit warpboard: at most one instruction per warp to be executing
- release-on-read warpboard: only one instruction at a time per warp to be collecting operands
- instruction level parallelism
Instruction Replay
当一条指令在GPU流水线上发生结构冒险了怎么办?对于一般的CPU来说我们可以简单的暂停当前指令,直到结构冒险消除再继续执行。但是这种方法在高吞吐量的系统中并不适用,停滞的指令可能处于任务的关键路径上进而影响到任务的完成时间,并且大量的停滞需要额外的缓冲区来存储寄存器信息。同时停滞一个指令可能会停滞其他完全不必要停滞的指令,降低了系统的吞吐量。
在GPU中我们可以尝试使用instruction replay来解决这个问题。instruction replay最早是在CPU的推测执行中作为一种恢复机制出现的,当我们执行了错误的分支,正确的指令会被重新取回并执行,消除错误分支的影响。在GPU中我们一般会避免推测执行,因为这会浪费宝贵的能源以及吞吐量。GPU实现instruction replay是为了减少流水线阻塞以及芯片面积和对应的时间开销。
在GPU上实现instruction replay可以通过在instruction buffer中保存当前指令直到这条指令已经执行完成,然后再将其移出。
Memory system
First Level
The shared memory is implemented as a static random access memory (SRAM).
每一个lane都有一个对应的bank,bank上各有一个读port和一个写port
shared memory 和 global memory 的访问粒度似乎是不同的,shared memory可以以warp为单位进行访问,但是global memory每次就是访问一个cache block
While the data array is highly banked to enable flexible access to shared memory by individual warps, access to global memory is restricted to a single cache block per cycle.
The L1 cache block size is 128 bytes in Fermi and Kepler and is further divided into four 32byte sectors in Maxwell and Pascal.
要是按照这个的说法,每次读取global memory最小单位就是32B
The 32-byte sector size corresponds to the minimum size of data that can be read from a recent graphics DRAM chip in a single access.
一个128B的cache block,会分为32个bank,每个bank对应4B(32-bit entries) Each 128-byte cache block is composed of 32-bit entries at the same row in each of the 32 banks.
The data to be written either to shared memory or global memory is first placed write data buffer (WDB).
Memory Partition Unit
The memory access schedulers in memory partition unit contains frame buffer(FB) and raster operation(ROP) unit.
- L2 cache To match the DRAM atom size of 32 bytes in GDDR5, each cache line inside the slice has four 32-byte sectors.
L2 cache line的长度是128B,由4个32B组成
Warp
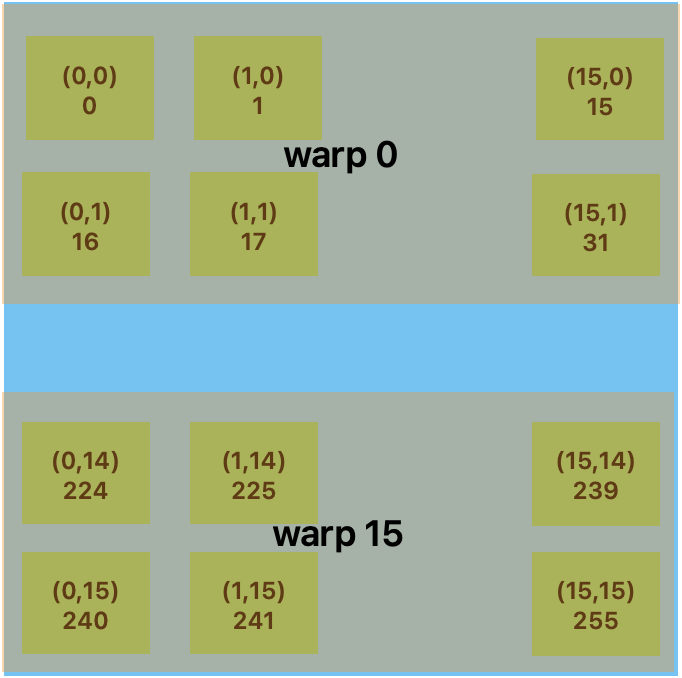
The multiprocessor creates, manages, schedules, and executes threads in groups of 32 parallel threads called warps.
一个SM可能执行多个block。虽然说不同block之间可以并行执行(不过要求在不同SM上才可以并行),但是映射到同一个SM的block,它上面的warp是不能并行执行的,只能相互等待。
How block’s threads get mapped to warps?
We can get answer from 4.1. SIMT Architecture.
The way a block is partitioned into warps is always the same; each warp contains threads of consecutive, increasing thread IDs with the first warp containing thread 0.
从这个答案中,不难引发另一个疑问,即
How thread ID can be calculated?
We can get answer from 2.2. Thread Hierarchy.
The index of a thread and its thread ID relate to each other in a straightforward way:
- For a one-dimensional block, they are the same;
- for a two-dimensional block of size $(D_x, D_y)$, the thread ID of a thread of index $(x, y)$ is $(x + y \times D_x)$;
- for a three-dimensional block of size $(D_x, D_y, D_z)$, the thread ID of a thread of index $(x, y, z)$ is $(x + y \times D_x + z \times D_x \times D_y)$.
(Editer replenishment): please note that the above comparison is between index of thread and thread ID, so dont’s be confused about the first situation. i.e. “for a one-dimensional block, they are the same”, it means for a one-dimensional block, the thread ID is equals to the index of this thread.
According to the question of “Does CUDA think of multi-dimensional gridDim, blockDim and threadIdx just as a linear sequence?”, we can see the type of thread organization as the row major ordered multi-dimensional arrays. But please note the difference between the index in CUDA and the index of traditional array or matrix.
For traditional array or matrix, we are used to use the (row_index, col_index) to indicate the position of an element in an array or a matrix. But in CUDA, the coordinates seem to become adverse, CUDA uses the (x = column_number, y = row_number) to express a grid or block.
In fact, these two expressions don’t create conflicts. The (row_index, col_index) is a perspective of actual storage mode. Now, if we place the array or the matrix into a coordinate system, we can also use the (x, y) to indicate an element of the array or matrix.
We can say that the (row_index, col_index) is a coordinate from storage structure perspective and the (x = column_number, y = row_number) is a coordinate from math coordinate system perspective.
Because the concept grid and block are just for programmer convenience, so they don’t imply the actual storage structure, so the CUDA use the math coordinate to indicate the position of an element in an array or a matrix. For the thread index $(x, y)$, the x is the column number, y is the row number, it is like the following picture of block index.
How to understand and calculate occupancy ?
Warp Scheduling Strategy
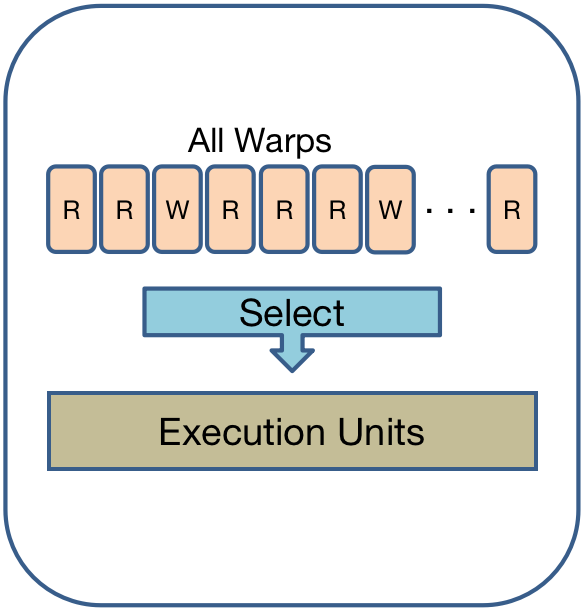
- Loose Round Robin (LRR)
处于Ready状态了就开始执行,否则跳过先发射下一个warp
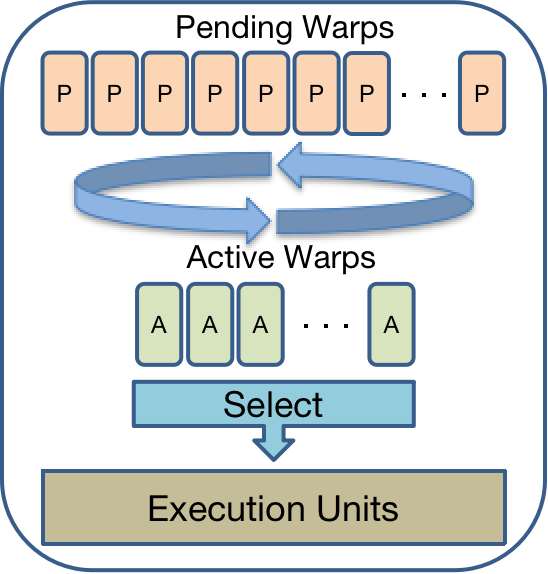
- Two-level (TL)
把warp分为两组,Pending warps 和 Active warps,warp在这两个组之间变换,当warp需要等待某些长延迟操作时,就切换到pending warp那一组,当条件就绪后,则转到active warp这一组,在active warp这一组采用LRR的调度策略
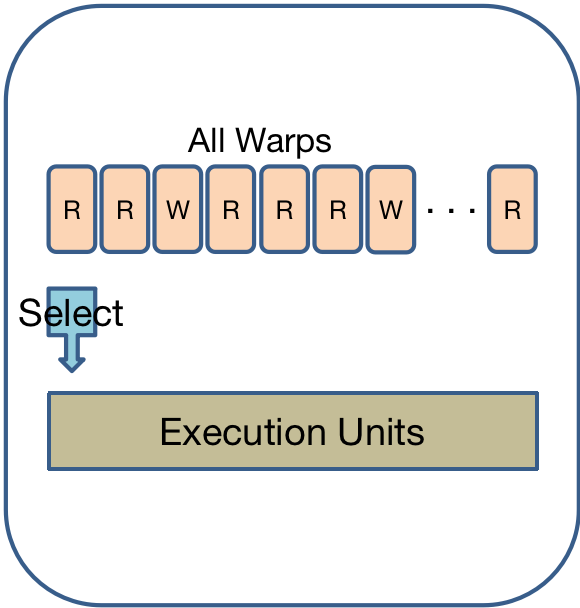
- Greedy-then-oldest (GTO)
考虑到局部性,会贪婪地执行一个warp,直到它进入stall状态才会切换其他warp执行
Common Error
cudaErrorNoKernelImageForDevice
According to this stackoverflow QA, we need to add the compilation option arch=compute_XX and code=sm_XX.
If we use command to compile code directly, we can add the option -gencode arch=compute_XX,code=sm_XX.
If we use CMake, we can add the following content:
| |
Hopper Architecture

| SM 数量 | 132 |
|---|---|
| L2 cache size | 50 MB |
| SRAM-per-SM | 256 KB (shared mem(至多 227 KB) + L1 cache) |
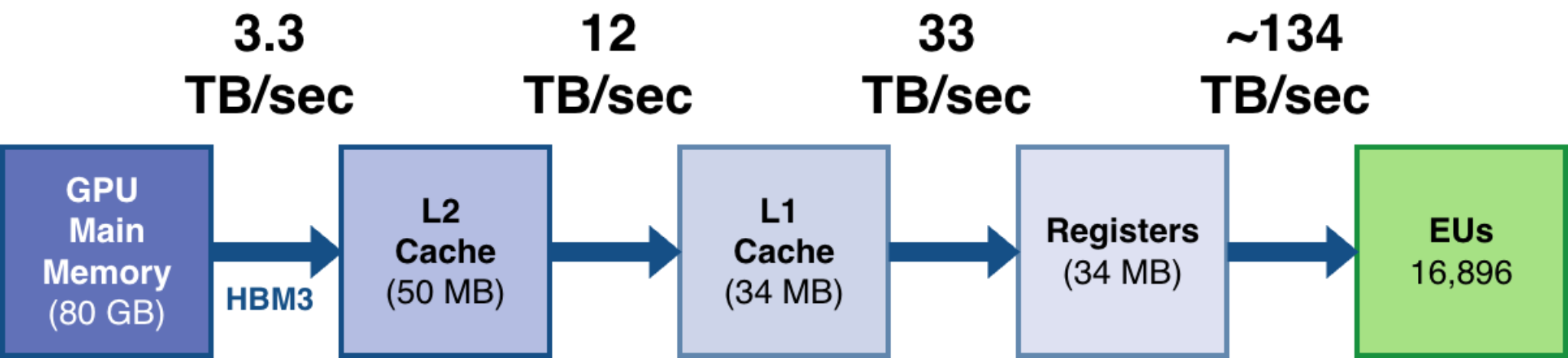
L1 Cache 和 Shared Memory 实际上是物理上共享同一块 SRAM 硬件资源的,图上的 L1 cache 是一个广义的统称,和表格中的不是一个含义
The H100 introduces two new features: the Tensor Memory Accelerator and warp group-level matrix multiply instructions.
新技术引入后,Hopper 架构下硬件特性驱动的软件实现范式实现了如下发展过程
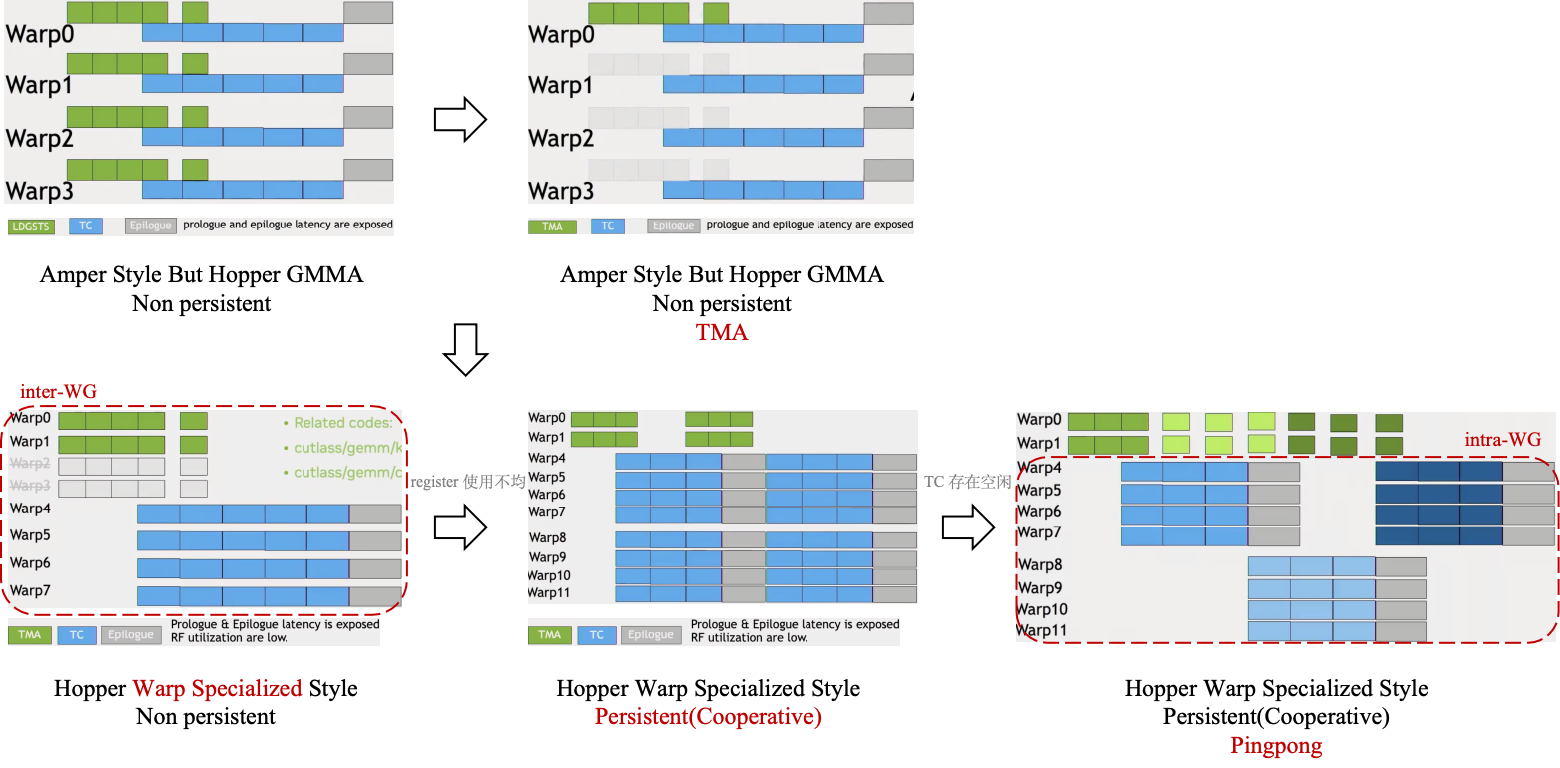
子图来源还有待查询
- Ampere Style: Warp 同时负责搬运数据(LDGSTS/绿块)和计算(TC/蓝块)
- TMA 优化: 引入了 TMA (Tensor Memory Accelerator)。硬件可以自主搬运张量数据,不再占用 Warp 的计算资源
- 从通用 Warp 到 Warp Specialized: Warp 被分为两组角色:一组专门负责数据搬运(Producer),一组专门负责计算(Consumer),即构成了生产者-消费者模型
- 持久化内核:传统方式下每个 CTA 完成后就销毁,重新调度新的 CTA,这会产生指令开销,持久化方式下,在 CTA 启动后它们会在一个 while 循环中不断抓取新的任务块,直到整个 Grid 计算完成,能够减少调度开销并保持 cache 热度
- 极致流水线化: 传统的并行效果应该是同一时刻相同部件在运行,比如图中如果浅蓝色部分是 mainloop 的 tensor core 计算,灰色是 epilogue 的 cuda core 计算,显然蓝色部分对于 cuda core 来说资源就是空闲的,灰色部分对于 tensor core 来说资源就是空闲的,因此 Pingpong 调度让不同计算部件之间存在重叠,以此来保证任意时刻下的任意计算部件都保持繁忙。一个更为详细地展示如下图所示,之所以称为 ping-pong,是因为两个消费者的任务在不停地轮转,只看一个计算部件,就类似球一样在两个消费者之间来回跳动
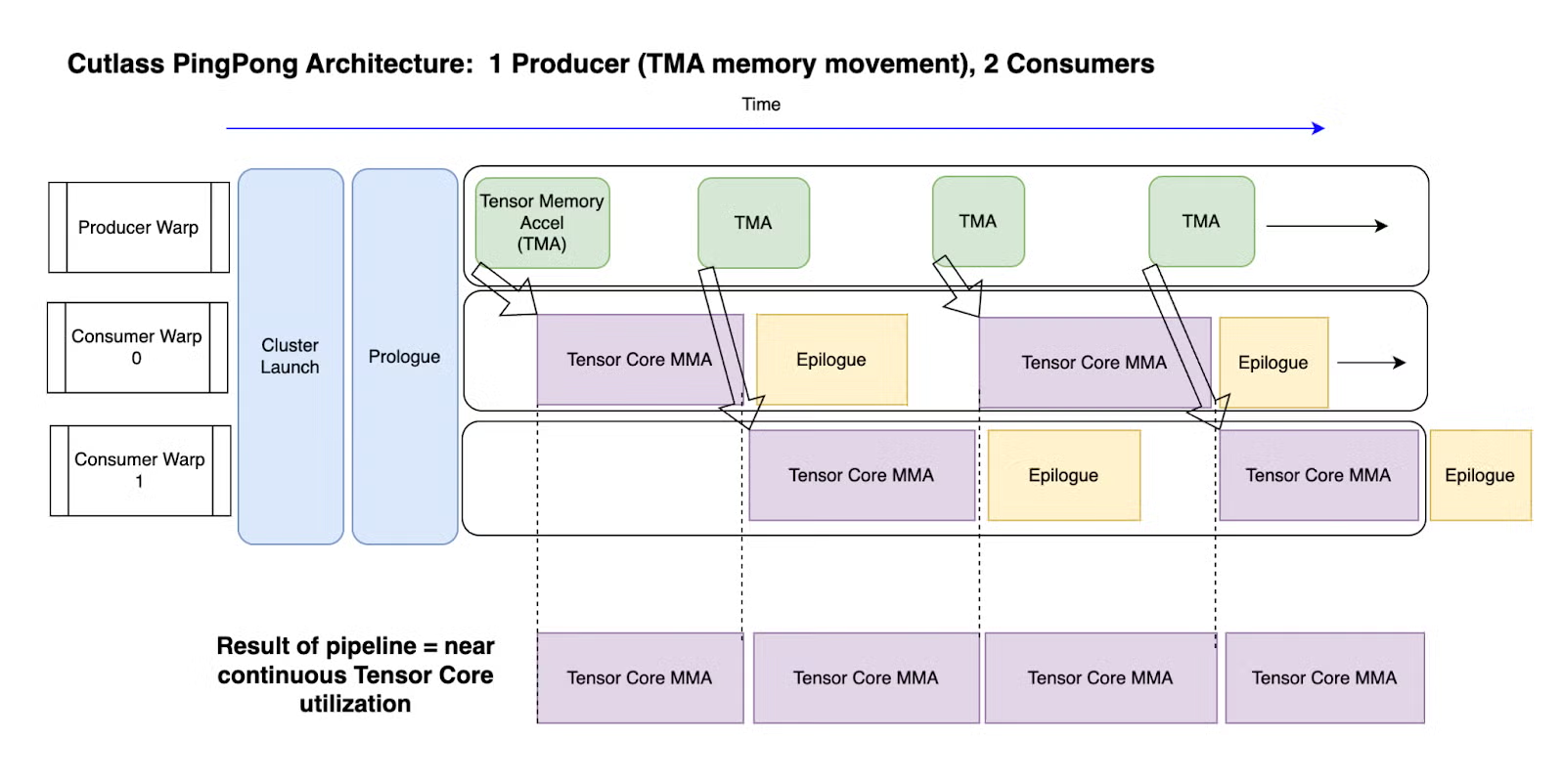
Tensor Memory Accelerator (TMA)
| 特性 | LSU (cp.async) | TMA Engine(cp.async.bulk.tensor) |
|---|---|---|
| 工作方式 | 线程(Thread)控制 | 硬件引擎自动控制 |
| 灵活性 | 极高。可以处理随机的、不规则的地址(如 Gather)。 | 较低。必须按照预定义的 Tensor 布局搬运。 |
| 计算开销 | 线程需要计算每个元素的地址。 | 线程只发坐标,硬件自动算地址。 |
| 同步机制 | cp.async.wait 或是简单的 barrier。 | 与强大的 mbarrier 硬件深度绑定。 |
group-level matrix multiply (wgmma)
The introduction of new instructions serves two primary purposes (or yields two key effects):
- Larger matrix tiles to be computed in a single coarse-grained operation, improving data reuse.
- Asynchronous makes it is possible to overlap some operations.
How to implement the wgmma instruction?
As described in Kernel hardware mapping, 一个 SM 上可以同时调度不同 block 中的 warp,那么只需要约束同属于一个 block 的 4 个 warp 同时在 SM 上执行,即可协作完成 wgmma 计算.
寄存器约束
The number of blocks and warps that can reside and be processed together on the multiprocessor for a given kernel depends on the amount of registers and shared memory used by the kernel and the amount of registers and shared memory available on the multiprocessor.
所以其实寄存器限制是对 kernel 而言的,取决于 kernel 到底需要多少寄存器
shared memory is block private memory, register is thread private memory
细分约束?对 block 或者 warp 有何约束
Performance Evaluation
正确理解“性能”一词
首先我们看两种计算:
$\frac{\text{理论计算量}}{\text{执行时间}}$
$\frac{\text{实际计算量}}{\text{执行时间}}$
在性能分析过程中,这二者我们都会用到,但是通过它们分析的内容并不相同。
解决问题的速度
- $\text{理论吞吐量} = \frac{\text{理论计算量}}{\text{执行时间}}$
理论计算量是指不看硬件计数器,直接看算法:
- 根据矩阵乘法的维度 $M, N, K$,计算总计算量为 $2 \times M \times N \times K$
- 记录 Kernel 的运行时间 $T$
- FLOPS $ = \frac{2 \times M \times N \times K}{T}$
这反映的是解决问题的速度。但是为什么要用理论计算量呢?
复杂点来说是为了公平对齐,简单点来说虽然“吞吐量”和“时间”看似是两个不同的性能指标,但是我们一说解决问题的速度,本质上说的就是在固定任务下哪种方法花费的时间更少,这并不会关心中间过程是否引入了什么额外的操作,就算是引入了其他操作,但只要能更快解决完就行,说白了它看重的只是解决这个问题本身到底花费的时间,所以“这个问题本身”就决定了要使用理论计算量而非实际计算量。
所以说白了这种计算方式从意义上来说就是单纯比较的时间。不过我理解在不方便通过硬件计数器获取真实的浮点计算次数的情况下,也可以用这个数据大致评估目前的数据量是否接近硬件的实际处理能力。
Roofline
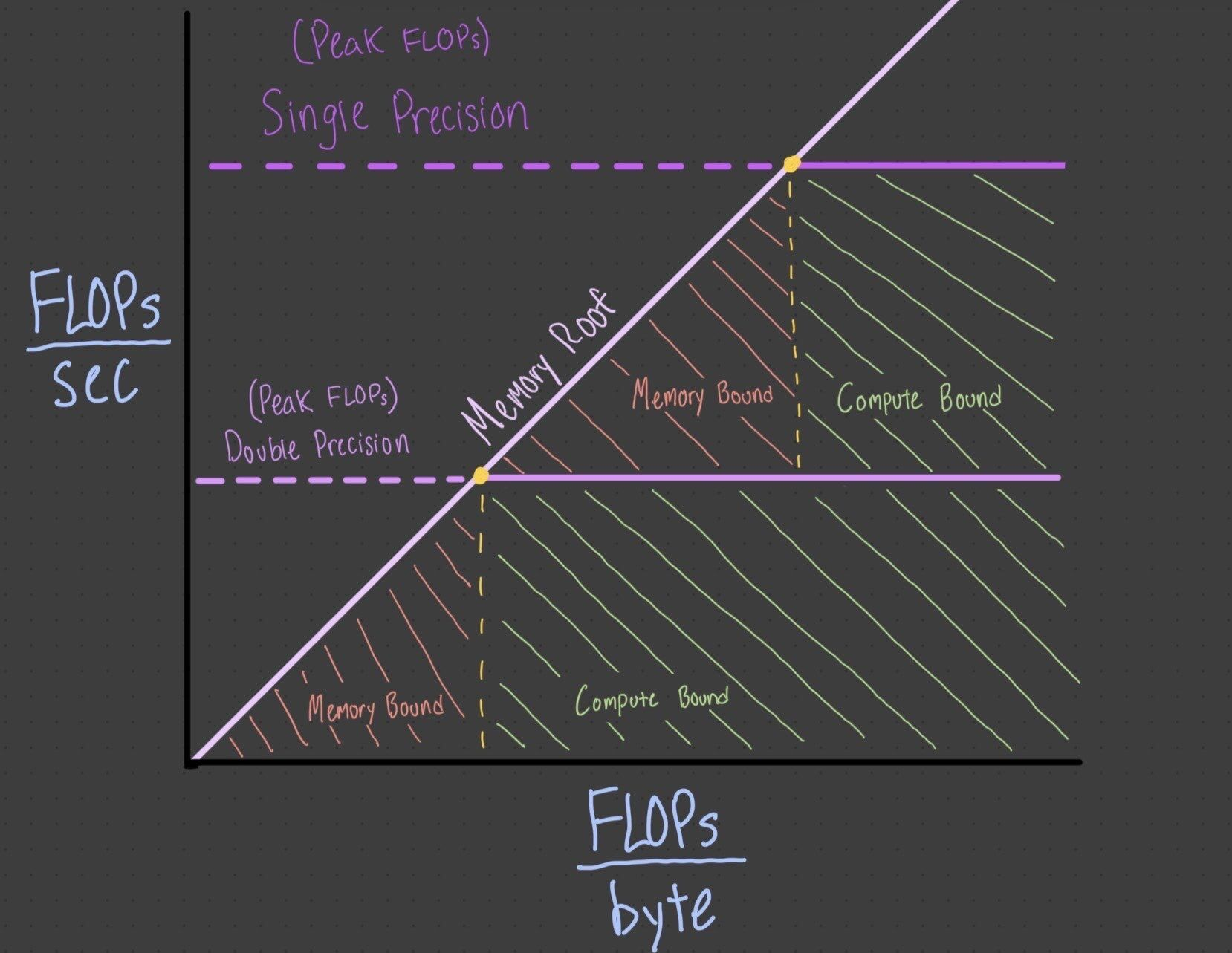
硬件利用率
- $\text{实际吞吐量} = \frac{\text{实际计算量}}{\text{执行时间}}$
实际计算量是指看硬件计数器。
在 Roofline 中程序实际达到的那个点对应的数据就是这个值,用此计算结果同硬件的峰值性能对比,我们就可以了解到目前程序对硬件的利用程度如何,从而指导我们是否还存在优化空间。
误区
如果硬件利用率低,那么解决问题的速度一定慢
举一个例子,
A 方法(原始版): 理论计算量 100,实际执行 120(因为有冗余计算),耗时 10s。
B 方法(优化版): 理论计算量 100,实际执行 80(去掉了无效计算),耗时 8s。
根据上述数据,我们可以得到如下计算:
$$\begin{cases} A \text{理论吞吐量} = \frac{100}{10} = 10 \ B \text{理论吞吐量} = \frac{100}{8} = 12.5 \ A \text{实际吞吐量} = \frac{120}{10} = 12 \ B \text{实际吞吐量} = \frac{80}{8} = 10 \end{cases}$$
注:因为硬件峰值对于 A 和 B 是一致的,这里就直接根据实际计算量和时间的比值来代表利用率了。
从硬件利用率的角度来看,A 的利用率更高,但是由吞吐量可知对于端到端来说,A 其实是不如 B 能更快完成这个计算任务的。这乍一看比较奇怪,但是仔细考虑一下会发现 A 为什么硬件利用率高反而算的还更慢呢?正是因为 A 的很多算力消耗都是无效的,没有对完成整个任务产生贡献。
实际上最强的状态反而应该是用更低的算力利用率,跑出了更高的吞吐量,即用小钱办大事。
算力利用率低只是代表我们还有优化空间,不代表算得就更慢。
所以我们到底应该怎么运用这两个数据呢?我们评估方案效果以及最后实际放到论文中的是理论吞吐量,利用率则用于在性能优化过程中结合 Roofline 帮助我们决策下一步的优化方案。
不过不太符合我们理解的是, 在 FlashMLA 以及其他的相关工作中,从上下文的语义来理解,应该想说明的是目前的算子对于硬件峰值性能的利用情况,那应该使用上述提到的实际吞吐量,而非用于评估算得快不快的理论吞吐量,目前还没有搞清楚这个原因。
It achieves up to 640 TFlops in forward computation on H800 SXM5 with CUDA 12.8, and achieves up to 1450 TFlops on B200, CUDA 12.9. 15
Nsight Systems
python 下添加 nvtx 标记有两种方式,但是目前实测只有第一种能够在 nsight system 中显示
| |
| |
在 cu 下添加 nvtx 标记的方式如下
| |
在以下自定义场景中,对比 cuda event 和 nvtx 标定的范围的执行时间
| |
发现三者的时间不太相同
| 测量指标 | 典型数值 | 代表意义 | 适用场景 |
|---|---|---|---|
| GPU 时间线 (Nsight) | 8.778 ms | 纯硬件执行时间。不包含任何驱动开销。 | 算法优化。当改动 Kernel 代码,想看计算效率是否提升时,看这个。 |
| CUDA Event | 9.2376 ms | 应用侧感知的 GPU 耗时。包含硬件执行和极小的调度误差。 | 程序内自测。在代码运行时需要动态调整策略(如负载均衡)时使用。 |
| CPU 时间线 (Nsight) | 9.275 ms | 端到端总耗时。包含了驱动提交延迟和同步开销。 | 瓶颈分析。如果这个值远大于 GPU 时间,说明 CPU 提交太慢或同步太频繁。 |
Nsight Compute
nsight compute 关键在于确定要采集的指标, Section 是具体的分析模块,而 Set 是为了方便使用而预定义的 Section 组合。
一个容易忽视的点在于
Full = full report 16
Full != All metrics
| |
| |
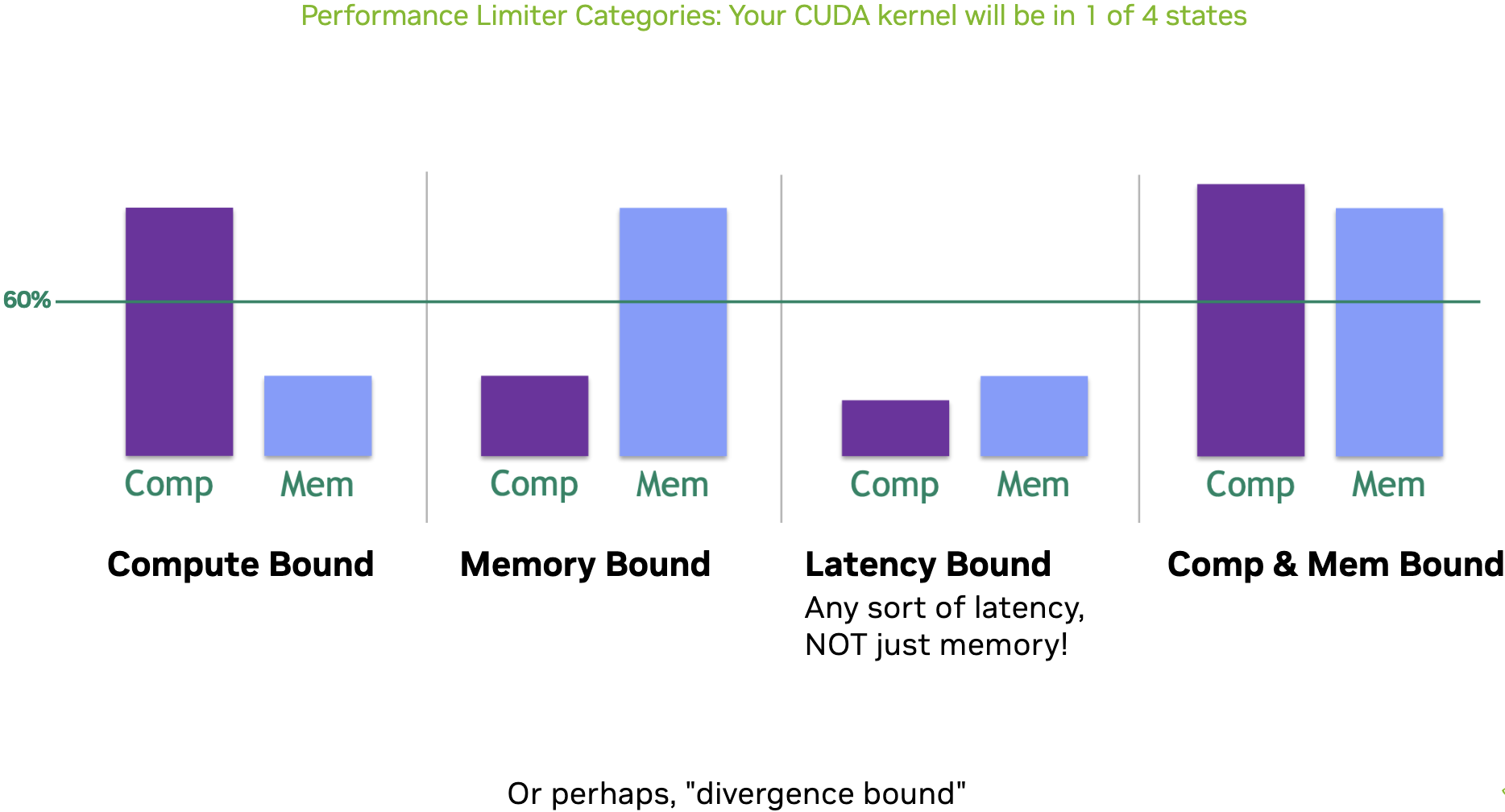
bound 情况分析
对于GEMM相关的Kernel进行性能分析时,我们建议先从Roofline模型出发,明确当前Kernel是Memory Bound还是Compute Bound,然后有针对性的检查Memory Workload Analysis和Compute Workload Analysis,遵循Top-Down性能分析的流程,而不要直接被不准确的性能指标所迷惑。
而 Roofline 也分为多种情况,称为 Hierarchical Roofline
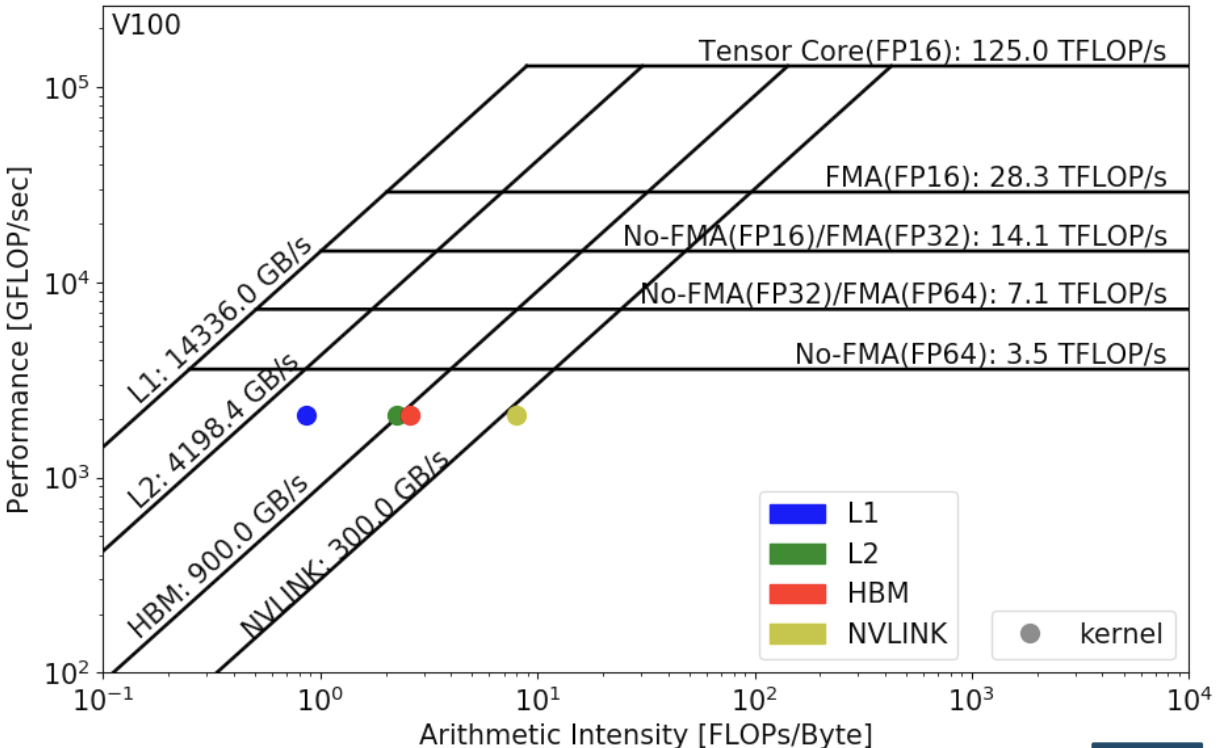
确定在 Roofline 中的位置需要三个数据:
- Runtime
- FLOPs(注意小写 s 是指浮点计算次数)
- Bytes(on each cache level, e.g. L1, L2, DRAM)
$Arithmetic\ Intensity \ = \ \frac{FLOPs}{Bytes}$ 确定 x 轴上的位置,$Performance \ = \ \frac{FLOPs}{Runtime}$ 确定 y 轴 上的位置,两条线的交点即为目前程序所处的位置。
需要牢记的一点是在利用 Roofline 分析性能表现之前,一定要确定 Roofline 是正确的,因为在实际的性能评测过程中,我们发现 Nsight Compute 统计的 Roofline 结果很可能是不准确的。原因主要在于
以下表所示的 H100 性能数据 19 为例
| H100 SXM5(TFLOPS) | ||
|---|---|---|
| CUDA Core | FP16 | 133.8 |
| FP32 | 66.9 | |
| FP64 | 33.5 | |
| Tensor Core | FP8 | 1978.9 |
| INT8 | 1978.9 | |
| FP16 | 989.4 | |
| BF16 | 989.4 | |
| TF32 | 494.7 | |
| FP64 | 66.9 |
这个过程中也发现一些第三方给出的数据与白皮书还不一致,例如 techpowerup 给出的 H100 FP16 的性能 为 267.6 TFLOPS,这个和白皮书任何一个数据都对不上。
在我们考虑如何通过 nsight compute 获取到目前程序的精准的 FLOPs 时,Confusion about the (d/f/h)(mul/add/fma) count in the nsight compute 提出的问题值得我们参考,问题和官方技术人员回答如下:
- How to estimate the FLOPS of kernels robustly?
Because the instructions can get very complicated (like single mma instructions doing full matrix multiplication) there isn’t a straightforward way to calculate accurate flops just using these metric counters.
Nsight Compute does not have a single FLOPs counter that rolls-up all data types.
只统计指令执行次数,但是一条指令对应的 FLOPs 不一定为 1,计算总的浮点执行次数还需要考虑权重
从这点来说需要进一步考虑 nsight compute 是如何计算得到的 Roofline
- Are the metrics matched with the data type of implementation, if not, how can we estimate flops?
there can still be fmul instructions in an fp16 kernel. They may not be operating on the actual data in the matrices.
如果存在一些与我们实际执行数据类型不同的指标有值,这是正常现象
从这点来说,目前怀疑 nsight compute 对于 tensor core 的支持有限,统计信息并不完整。我们在 Question about Roofline of TensorCore GEMM 中找到了同样的问题。
很可能是 ncu 的版本较低,如我们猜测的统计有问题,但是不能单独升级 ncu 的版本而不升级驱动(2025.1 - 2025/01/23 这个版本下首次完善了 Roofline 的支持,在 Nsight Compute Release History 中我们可以找到这个版本对于驱动的最低需求为 570.124.06)。
能否根据某些利用率指标,结合理论峰值性能,确定 FLOPs,与理论估算的结果进行比较判断可信度
Instruction Analyse
在编译时添加 -lineinfo 选项,即可在 nsight compute 中查看到源码,PTX 和 SASS 的对应关系
CUDA Related Documents
Reference
- [1] CUDA C++ Programming Guide
- [2] Does NVCC include header files automatically?
- [3] 网格跨步
- [4] CUDA Runtime API Documentation (Please note the version of coda)
- [5] CUDA编程方法论-知乎专栏
- [6] CUDA Crash Course - Youtube
- [7] GPGPU架构优秀PPT(Teaching部分)
- [8] Accelerated Computing - Programming GPUs
- [9] CUDA编程入门及优化 | 知乎
- [10] Tensor Core技术解析(上)
- [11] Tensor Core技术解析(下)
- [12] NVIDIA Developer Tools 汇总
- [13] 《General-Purpose Graphics Processor Architecture》中文翻译
Chen Y A, Yu J X. Bitmap-Based Sparse Matrix-Vector Multiplication with Tensor Cores[C]//Proceedings of the 53rd International Conference on Parallel Processing. 2024: 1135-1144. ↩︎
unified virtual addressing (UVA) vs. unified memory: perceived difference ↩︎
9.7.13.1. Parallel Synchronization and Communication Instructions: bar, barrier ↩︎
CUDA Techniques to Maximize Compute and Instruction Throughput ↩︎