MPI
mpicc, mpic++, mpicxx mpiexec, mpirun mpichversion
mpicc 仅可编译 .c 文件,编译 .cpp文件会报错 mpic++ 编译 .cpp 文件
MPI标准的不同实现:MPICH、MVAPICH、MVAPICH2、Open MPI
MPI编译器mpicc只是对于普通c/c++编译器的封装,在普通编译器的基础上添加了MPI相关文件的路径便于进行头文件引入和链接
mpiexec is a direct link to mpiexec.hydra
mpirun is a wrapper script that determines your batch system and simplifies the launch for the user, but eventually also calls mpiexec.hydra
通信子 <=> 进程集合
MPI_Init 会初始化一个通信子communicator MPI_COMM_WORLD
MPI Introduce
All parallel in MPI is explicit.
MPI implementation version:
- MVAPICH
- MPICH
- Inter MPI
- Open MPI
- Microsoft MPI
MPI Install
| |
If we execute the command man mpicc or man mpicxx, we can get two command line arguments -compile_info and -link_info, which are used to show the steps for compiling a program(what options and include paths are used) and show the steps for linking a program(what options and libraries are used).
If we use the mpicc -compile_info or mpicc -link_info, we can get the following compile options:
| |
For a detailed explanation of the above options, please refer to the C C++ Compile Link.
Acording to the result of the option mpicc -compile_info or the mpicc -link_info, we can learn about that the mpicc and mpicxx is just a wrapper of gcc and g++, them add extra options for gcc and g++.
And -prefix= option and make install make the mpicc and mpicxx carry the compile option according to the content of the -prefix=, which is equal to the gcc or g++ which carry these optinos manually.
According to the rpath | wikipedia, we can use the readelf -d <binary_name> | grep 'R.*PATH' to verify the role of the compile option -Wl.
| |
| |
The GNU Linker (GNU ld) implements a feature which it calls “new-dtags”, which can be used to insert an rpath that has lower precedence than the LD_LIBRARY_PATH environment variable.1
Hello World
| |
MPI Environment Management
int MPI_Init(int *argc, char ***argv)
When we call this function, system will generate a communicator called MPI_COMM_WORLD
Naming Style
If all the letters are the capital letters, it always be a constant, such as MPI_AINT. It is like the MPI_INT.
If the letters contains the capital letters and lowercase letters, it always be a type, such as MPI_Aint.
Datatype
contiguous
用于连续的数据
vector
数据块的大小 和 两个数据块之间的距离 均为常数
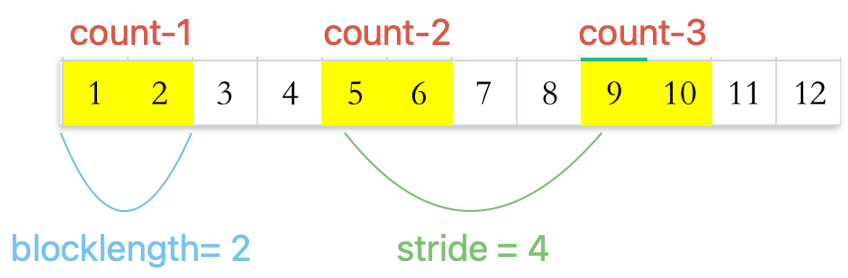
Please note that vector is not only used for one dimension scene,it can also used for two dimension matrix.
One or two dimension is just a concept of programming language. For MPI, no matter what types of matrix, it all sees as the one dimension in memory, e.g. it only cares about the structure of memory.
So, if we want to describe a submatrix, we can also use the MPI_Type_vector(), just edit the input matrix structure.
In my opinion, upper bound and lower bound are just memory addresses,
index
与 vector 类似,但数据块大小和两个数据块之间的距离均不是常数,用于补充 vector 的应用场景
MPI 发送和接收数据并不是要求派生数据类型必须相同,而是要保证发送和接收数据之间能够匹配上,发送时使用派生数据类型,接收时是可以使用原生数据类型的,参考MPI_Type_indexed。
struct
最灵活的一种,灵活性来源于可配置项的增加。In fact, the most important configuration items are block_lengths[], displacements[] and block_types[].
- vector: these three configuration items are immobilized.
- index: can specify the
block_lengthanddisplacementrespectivly. - struct: can specify these three configuration items respectivly.
Please note that, the number of block_length corresponds to the block_types.
Although the name of this type is struct, we not only treat it as a true C struct, but also mix of any other data types.
MPI Execution Mode
If we create some arrays in main function and execute the MPI program with many processes. These arrays in different processes are private datas.
Communication
MPI use the Point-to-Point(P2P, 点对点通信), 显式采用双边通信,需要进程双方的参与,在 MPI 2.0 中提出了单边通信的概念。
P2P 的两种具体实现协议:(所谓实现协议,是指这部分内容并不属于 MPI Standard)
- Eager
- Rendezvous
阻塞式
MPI 提供了一些数据结构,对应C/C++中的基础数据结构,用于在更高层次指定消息结构
Receiver 如果收不到消息会一直阻塞等待。
Sender 是否会阻塞取决于 MPI 的具体实现,某些实现下,在没有对应的 Receiver 时,Sender 会阻塞;在某些实现下,Sender会将数据存储到 send buffer 中,然后直接返回,并不会阻塞。这一点区别会影响到对于 MPI deadlock 情况的分析。
| |
Please note that, the count field in MPI_Send means the number of data which will be send, but it means the max capacity of receive buffer.
我们称 MPI_Send 和 MPI_Recv 是阻塞式的,这一说法来源于MPI Document,然后它们的 actual performance is maybe different from what we understand.
Before we talk about some situations which can explain this statement, we need to discriminate some concepts:
MPI is a standard, it contains many rules to tell us what should MPI do and how it do.
MPICH and OpenMPI are implementation of MPI
In MPI standard, MPI_Send is a blocking function.
But in MPICH MPI_Send doc, we can see the following statement:
This routine may block until the message is received by the destination process.
How can we understand this “may” ?
Answer: In MPICH, when the MPI_Send can’t find the enough send buffer, it will block. or else, it will return.
There is an example 2 to elaborate this viewpoint
If we follow the rule of MPI standard, MPI_Send will block entil MPI_Recv is executed. But the following example doesn’t follow this rules
| |
The output of program is:
process 0: 1
process 1: 0
According to the rule of MPI standard, this program can’t execute, but it get the right result now.
There is a precondition of this program can get the right result is that MPI_Send can return normally before the corresponding MPI_Recv function completes execution.
So, we can use the following program to verify this guess.
| |
This program will get the following result:
MPI_Send returns
process 2 receives the msg: 2
process 1 receives the msg: 1
And we can also use the following extreme example
| |
This program can also execute rightly, and will get the following result
MPI_Send returns
Now, let’s review which problem do we face, we have a guess that “MPI_Send can return normally before the corresponding MPI_Recv function completes execution”. Now we use these two examples to verify this guess. So we can also explain the fist problem that the program doesn’t follow the MPI standard but it can also finish execution.
In fact, in MPICH, there is explain of execution principle of MPI_Send
The message sent by each MPI process has to be copied out before the send operation completes and the receive operation starts.
In a word, what we want to say is that the detail expression of some functions is decided by the implementation of MPI standard, but when we use these funcitons, we still should follow the rule of MPI standard to prevent some strange results.
非阻塞式
Because non-blocking function will return immediately after calling. So the data in buffer is maybe not received by receiver process. So, MPI provides the MPI_Request, MPI_Wait() and MPI_Test() to address this problem.
Deadlock
消息查询
Dynamic Receiving
利用MPI_Recv的最后一个 MPI_Status 参数来获取接受到的消息的信息,以便应对动态长度的传输数据
The data structure of MPI_Status:
| |
An example of using status, but MPI_Recv的问题在于只能提前开辟尽可能大的store buffer,在接受完消息后再通过status得知消息长度
| |
替代方案是首先使用 MPI_Probe 获取消息长度,然后根据消息长度开辟存储空间,再使用 MPI_Recv 接收消息,避免空间浪费(不过这只是逻辑说法,实际连接起这些概念的都是status,MPI_Probe也是将即将接收到的消息状态存储到status数据结构中)
| |
Communicator
Hign Dimension Communicator
这里其实就涉及到我们对于通信子的理解了,如果从计算机网络的角度来说,通信子可以理解为一个广播域(从通信子的使用方式来看,确实也比较符合这种理解方式)
所谓高维通信子,不过是把进程按照一种新的方式进行分组
在 MPI 中,我们需要 MPI_Comm_split 实现对现有进程重新分组,我们需要考虑重新分组需要指定哪些内容:
- process 将位于哪个组别
- process 在新的组别中的编号(这里的编号指的就是在 1 维下的编号了)
以上两项内容分别由函数参数中的 color 和 key 实现
color 相同的被分到同一个组中,也就是同一个通信子中,key 的相对大小关系将决定了 process 在新的通信子内的 rank 排序方式(这里按照目前我的理解,只需要关注 rank 的相对大小,实际编号仍然是从 0 开始,遵循 rank 所指示的相对大小关系)
实际上我们所说的几维通信子,这里的维度只是人为附加的一种认知信息,所谓认知信息是我们通过分组,为每个进程都添加了额外的分组信息,我们可以通过这些分组信息抽象出高维结构,或者说通过这些分组更好地映射到某些计算任务上,但是这并不代表实际真的存在这样一个高维结构,不过是人为附加的信息罢了。
需要注意的是,我们一般在划分完高维通讯子后会去获取一下进程在自己的 行通讯子 和 列通讯子中的 rank。
| |
这里要格外小心,上述代码中的 row 和 col 并不等价于逻辑布局中的行号和列号,以 3 x 2 的布局为例,代码中的 row 和 col 对应到逻辑布局上如下图所示
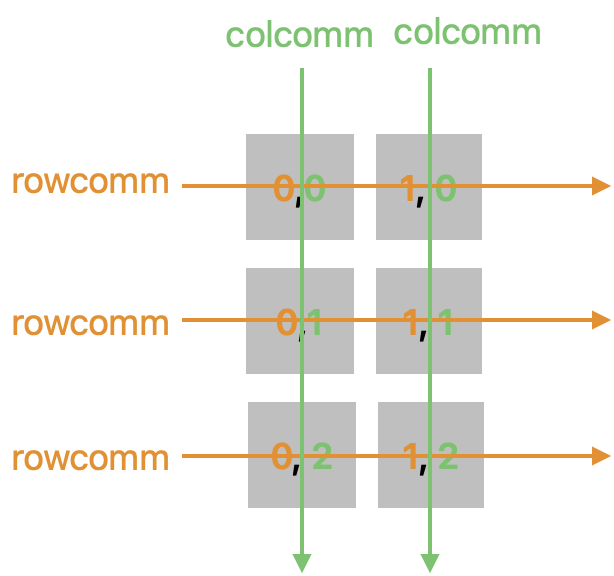
在上图中,我们用第一个数值表示 process 所在行通讯子中的 rank 值,第二个数值表示 process 所在列通讯子中的 rank 值
Broadcast
收发双发都调用 MPI_Bcast 函数,参数也是相同的。(这一点很重要,因为在实际编程时我们很容易就理解成只需要让发生 broadcast 的通讯子内部的 root node 调用即可,但是实际上需要这一通讯子内部的所有 process 都调用此函数)
那么很神奇的就是函数如何判断函数调用者是发送方还是接收方,我觉得这应该是在函数实现中会对调用 process 的 rank 进行判断,无论是发送方还是接收方调用函数,函数参数中的 root 表示的都是发送方,那么函数在实现时只需要判断 root 值是否等于调用者的 rank 即可。
Gather
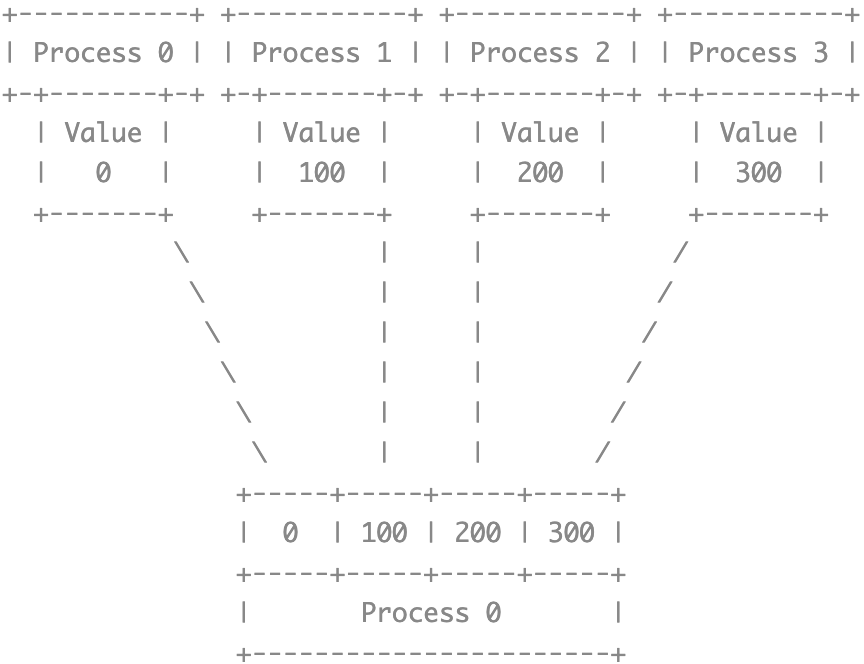
MPI_Gather() 一个函数既负责发送,也负责接收,通过参数中的 root 指定 gather 操作的信息接受者
There are some important things which are described in official document3.
The root receives the messages and stores them in rank order
Note that the recvcount argument at the root indicates the number of items it receives from each MPI process, not the total number of items it receives.
According to the second item above, MPI_Gather() can only solve the situation that all the processes send the same of data to the root process.
Thinking about why this function parameter recvcount is defined in this way. In fact, the effect of MPI_Gather is similar with each non root node calls the MPI_Send to send they own data to root node, so this viewpoint can explain the two phenomenons:
- why each process need to call the
MPI_Gather - why the meaing of recvcount parameter is the number of items that is received by root node from each process instead of all processes
If we want to gather data more flexibly, we can use MPI_Gatherv.
Scatter
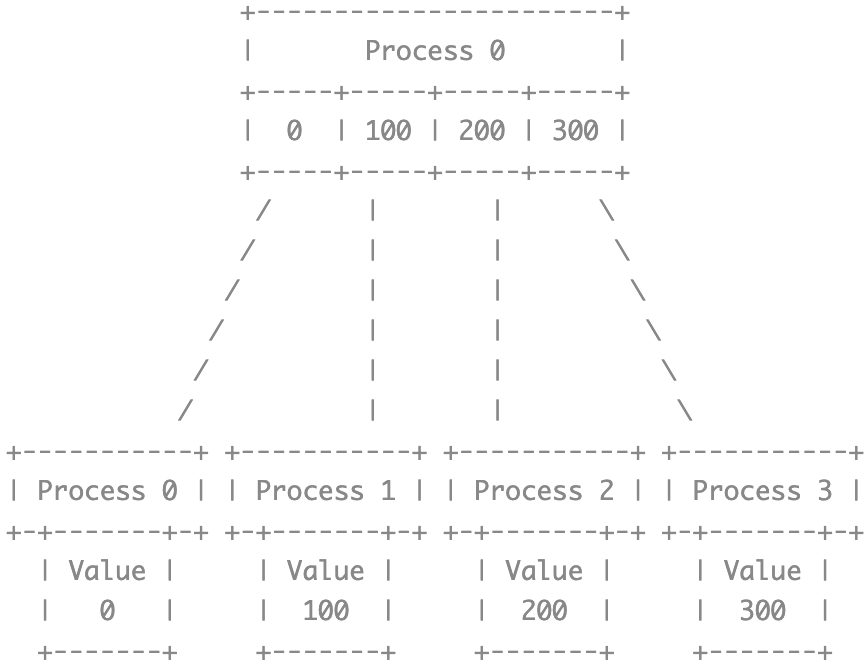
其实 MPI_Scatter 是 MPI_Gather 的逆过程,但是 scatter 的实际应用过程更容易出现错误。为了便于叙述,我们假定负责进行 gather 和 scatter 的进程均为 0 号进程。在 Gather 过程中,process 0 会汇集其他 process 所传递的数据进行合并,那么 MPI_Gather 将作为一个统一的入口点,在此函数参数中我们无法单独指定每块数据的长度,因此很自然就理解了 MPI_Gather只能处理不同 process 下长度相等的数据块。但是MPI_Scatter` 实际的分发过程是在各个接收 process 中完成的,我们很容易就会理解为让每个 process 接收自定义长度的数据。但是显然这对于 gather 来说,并非严格的逆过程,实际上,scatter 必须在每个 process 中都处理相同长度的数据,即不同 process 中处理的数据长度相等。
scatter 的 sendcount 指的是发送给一个 process 的数据量,而不是参与 scatter 的全部数据量,那么很容易产生一个疑问,即此时 sendcount 和 recvcount 又有什么区别,既然都是发送给 receiver process 的数据量,为什么不合并为一个 count,还要分为两个参量。产生这个疑问我们可能忽略了 sendtype 和 recvtype 的存在,发送 1 个 4B 的 int,接收 4 个 1B 的 char 是一个合理的需求,此时 sendcount 和 recvcount 并不相等。
There is an example that can explain this design. Firstly, we need explain some pre-infomations,
the binary expression of char $A$ is $1000001$, we use the binary expression $1000001010000010100000101000001$ (decimal number $1094795585$) to express the $AAAA$.
So, if we use four 1 byte char to receive this decimal number, we will get four $A$.
Now, we use MPI to verify this judgement.
| |
The result of the above code is:
process 0: A A A A
不过在这里例子中,我们仅使用到了一个 process,当参与过程的进程不止一个时,这里仍然会让人感到困惑,这是因为我们总是将 MPI_Gather 和 MPI_Scatter 的执行模式看为主从式,即在 gather 中,root 节点负责接收,其他节点负责发送,或者在 scatter 中,root 节点负责发送,其他节点负责接收。然而实际上并非如此,以 root 节点为例,它自己既是发送方又是接收方,to be honest, I don’t understand the design idea of scatter, expecially when I need to fill the parameter sendcount of MPI_Scatter, but we can follow a simple rule that $sendcount * sizeof(sendtype) == recvcount * sizeof(recvtype)$。
Maybe we can understand sendcount and sendtype in this way: when this progress includes multiple processes, we can think that root node need to send the message to other nodes one by one with rank order. So the sendcount and sendtype mean what needs to be sent from root node to an another node.
Now, we use an example to illustrate the usage of MPI_Scatter for multiple processes:
Following the above implementation method, we change the data from AAAA to AABB to verify the effect of scatter.
01000001 01000001 01000010 01000010 (1094795842)
A A B B
| |
The result of the above code is:
process 0: B B
process 1: A A
What we need to notice is that both MPI_Gatherv and MPI_Scatterv use the number of element for displacement, they do not use the byte displacement like some creating data type function, such as MPI_Type_create struct.
AlltoAll
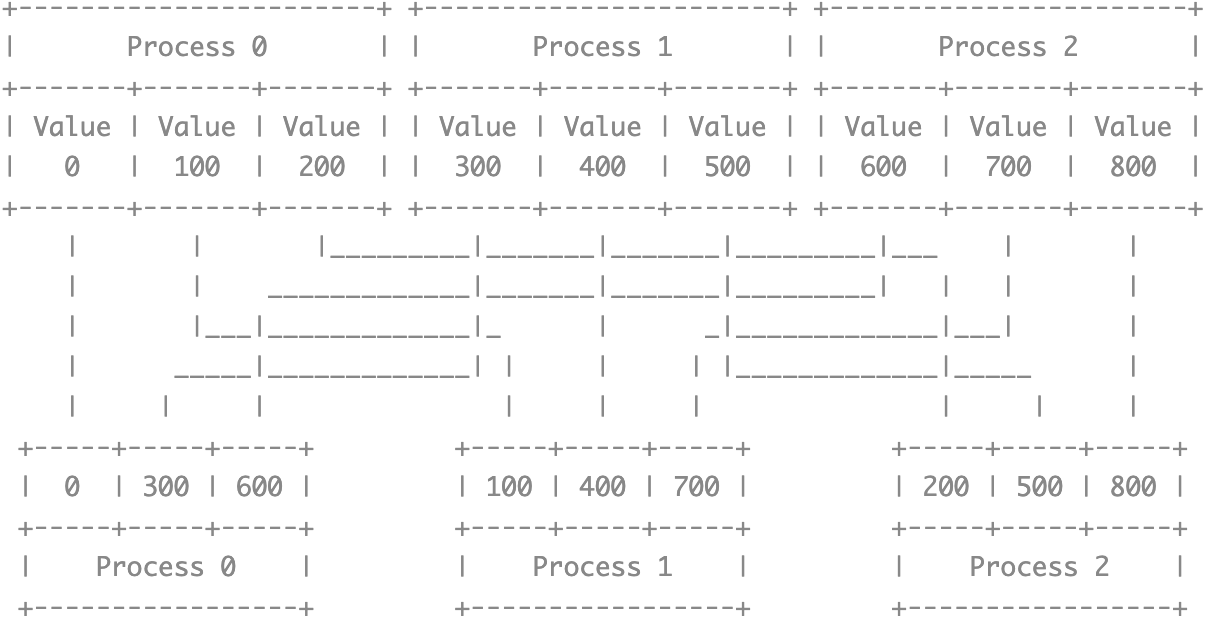
The principle of MPI_Alltoall is execute multiple times MPI_Send and MPI_Recv, so the parameter sendcount and recvcount in MPI_Alltoall means the message number from sender to receiver instead of total message volume.
Parallel Calculation Mode
Reduce
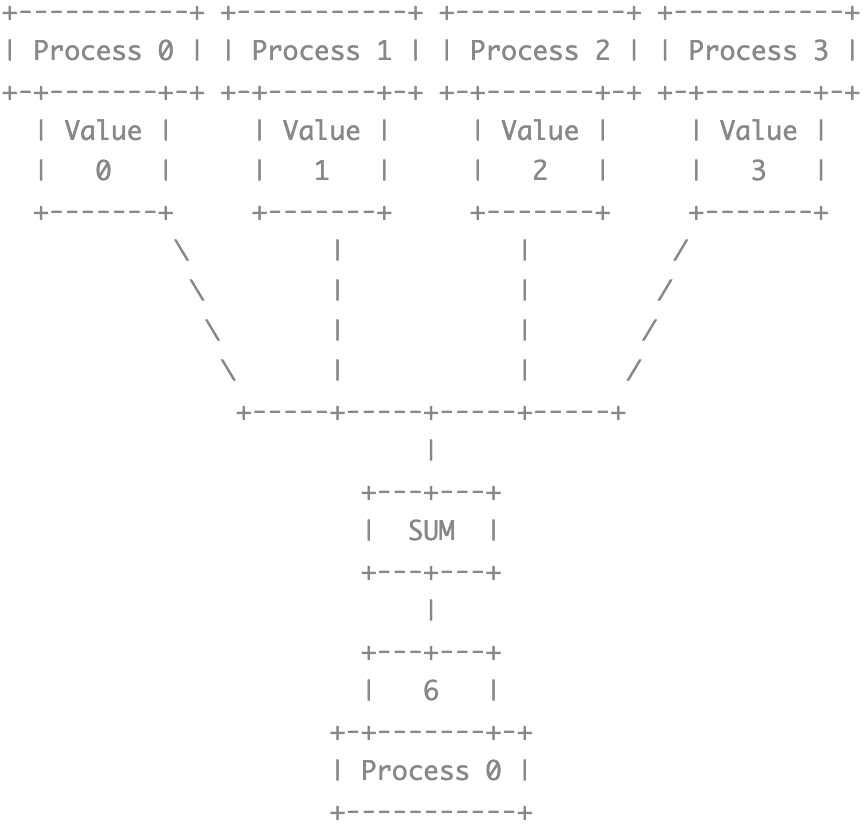
对多个元素进行 reduce 时,不同元素 reduce 的结果是分离的,有几个元素进行 reduce 结果就有几个
值得注意的是,传递给 MPI_Reduce 和 MPI_Allreduce 的 recvbuf 的初始值并不重要,假设进行的 reduce 是求和操作,那么直观感觉上最终的结果应该会累加到 recvbuf 中,但是实际测试结果并非如此,recvbuf 只是承担了存储最终结果的角色,求和并没有在其原始数值上进行
| |
在上述程序中,我们并没有对 sum 赋初值 0,但程序依然得到了正确结果 3
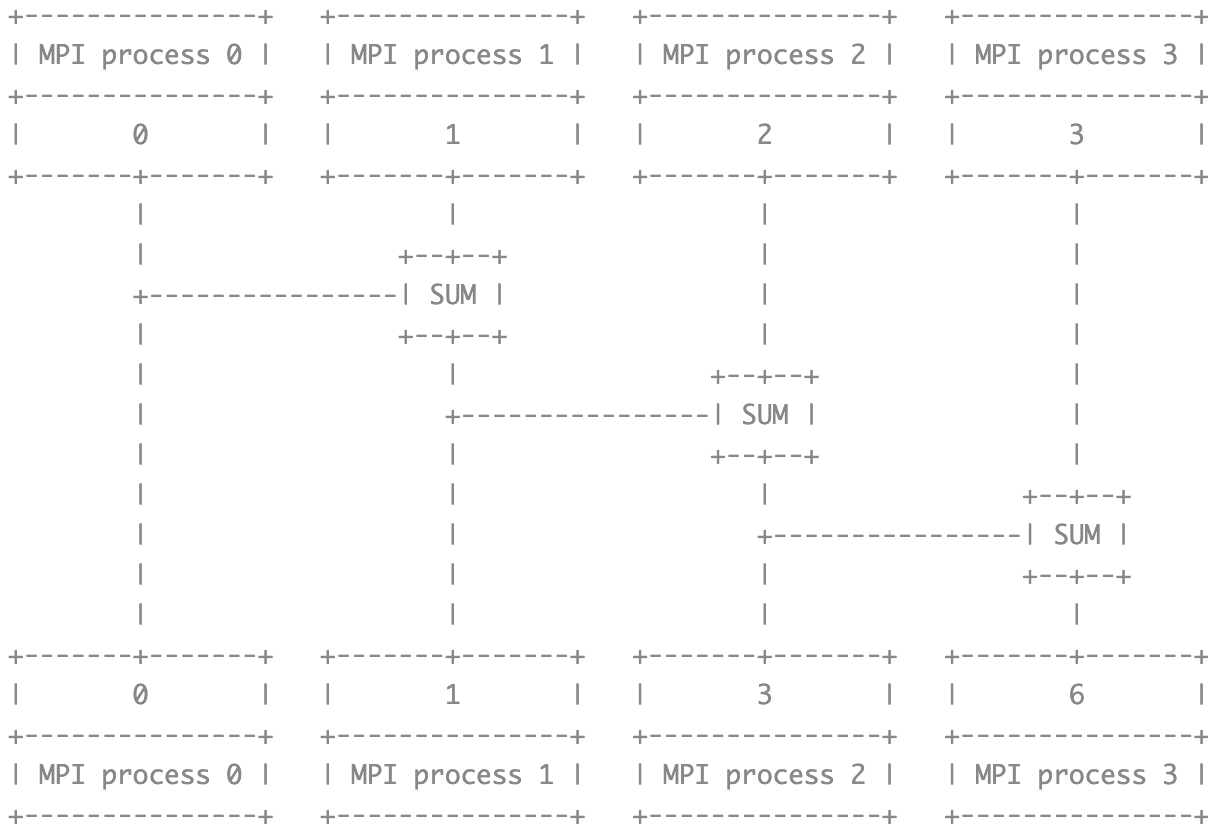
MPI_Allreduce 可以理解为两步操作:broadcast + reduce
- Every process broadcasts they onw data to other processes.
- Every process reduce all data and save the result to they own local result buffer.
Compare with MPI_Reduce,there is only a change in MPI_Allreduce program that MPI_Allreduce don’t need the root parameter, because every process is the root node.
| |
This program will get the following result:
process 0: 3
process 1: 3
process 2: 3
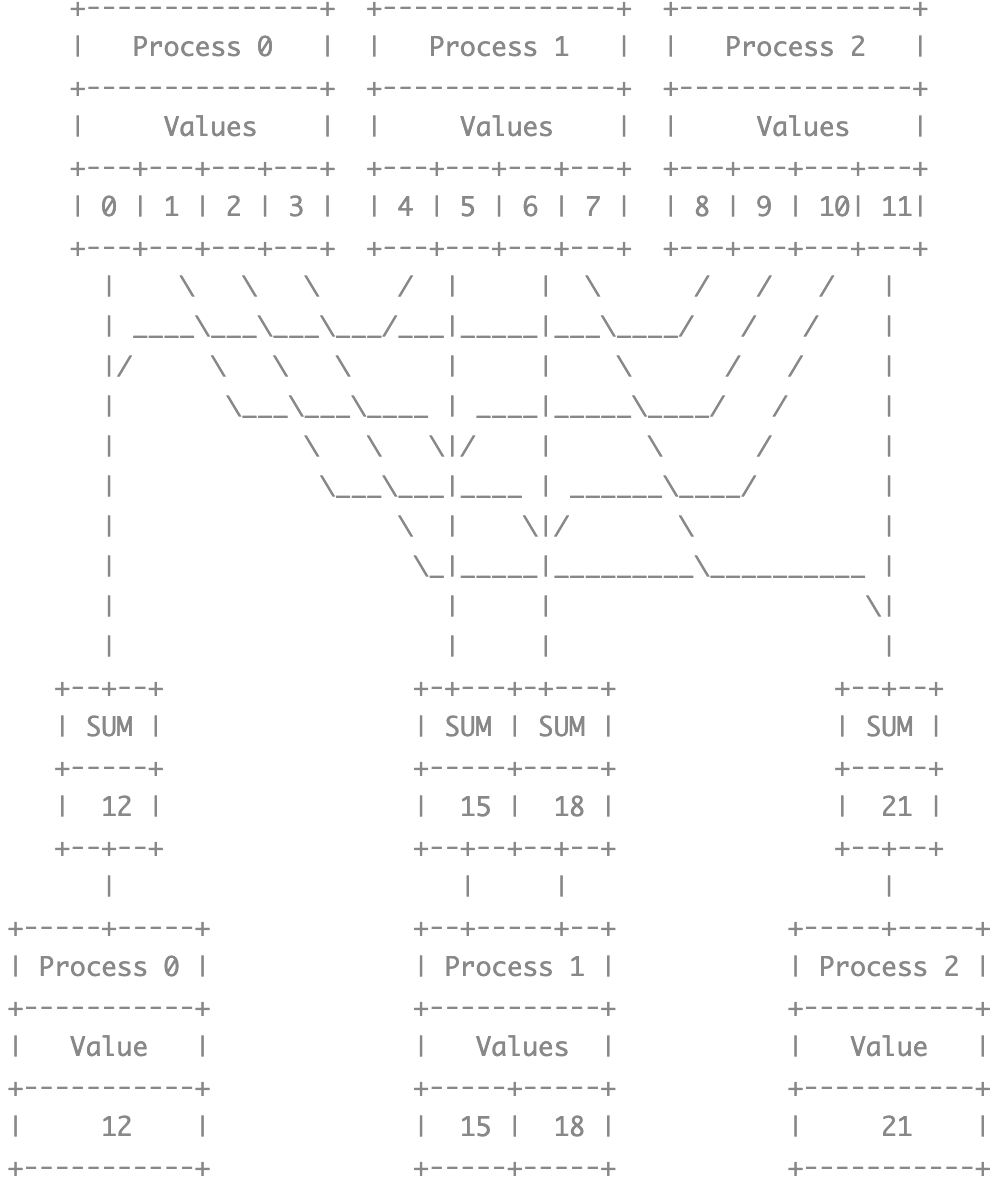
Scan
When judge the multiple channels input data,MPI_Scan 与 MPI_Reduce 的实现方式相同,都是对每个输入通道单独进行 scan 操作,如以下代码所示
| |
The program will get the following result:
process 0: 1 2
process 1: 3 5
process 2: 6 9
Reduce_scatter
The “reduce” is similar with MPI_Reduce, but the “scatter” is similar with MPI_Scatterv that it can specify the number of elements for every process.
user define operation
首先从调用形式上来说,由于 user define operatoin 是直接作用于现有的 MPI_Reduce 和 MPI_Scan 等计算函数的,所以函数接口的形式是可以确定的,不能确定的是 user define operation 的具体代码实现,而这个实现一定是对照实际需求的,如果想要在实际需求和代码实现之间建立起联系,我们必须要考虑的是 MPI_Reduce 以及 MPI_Scan 是以何种方式来调用这个 user define operation 的,只有在了解了执行模型后,我们才能编写出对照实际需求的代码实现。
在此前分析 MPI_Reduce 和 MPI_Scan 时,我们说法这两个函数在处理多通道数据时,处理逻辑是逐个通道来处理的,这里从定义 operation 时给定的 len parameter 可以看出,实际运算在处理时确实是逐个通道来处理的。
为了便于阐述,这里以 MPI_Reduce 使用 user define operation 为例
这里需要区分清几个概念:
- process 调用
MPI_Reduce时的 sendBuffer 和 recvBuffer - operation 所面对的 inputBuffer 和 outputBuffer
inputBuffer 对应非 root node 的 sendBuf,outputBuffer 对应 root node 的 sendBuf。(这里面没有涉及到的是非 root node 和 root node 的recvBuf,对于前者,并不需要提供这个参数,对于后者,只是负责存储最终的结果,中间数据是通过 root node 的 sendBuf 来负责存储的)
对于 MPI_Reduce 和 MPI_Scan 对于 operation 执行模式的了解有助于帮助我们解决之前所遇到的两个疑问:
MPI_Reduce并不关心非 root node 的 recvBuf parameter- root node 在没有初始化 recvBuf 时,最终依然能够得到正确结果(我们可以理解为中间的运算数据都是 root node 的 sendBuf 在存储,最后直接将运算结果存储到 root node 的 recvBuf 中,不过最终结果存储这个过程无法从现有测试中得到验证,只是我们对于实现机制的一种猜测)
只看上面的内容,依然会对整个过程比较模糊,我们结合下面的图来理解

如果有 3 个 process 参与整个过程,那么只有非 root node 会调用 operation,即上图中 call 的两部分,他们会通过蓝色框标识的参数直接与 root node 的数值进行交互,从而获得最终结果,中间运算数据都存储在 root node 的数值中,最终存储到 root node 的 recvBuf 中。
CUDA-Aware MPI
An Introduction to CUDA-Aware MPI
Network
RDMA(Remote Direct Memory Access,远程内存直接访问)技术
让数据能够在不同服务器内存间直接传输, 而不经过 CPU 和操作系统(简单理解就是网卡需要承担 CPU 的部分计算任务)
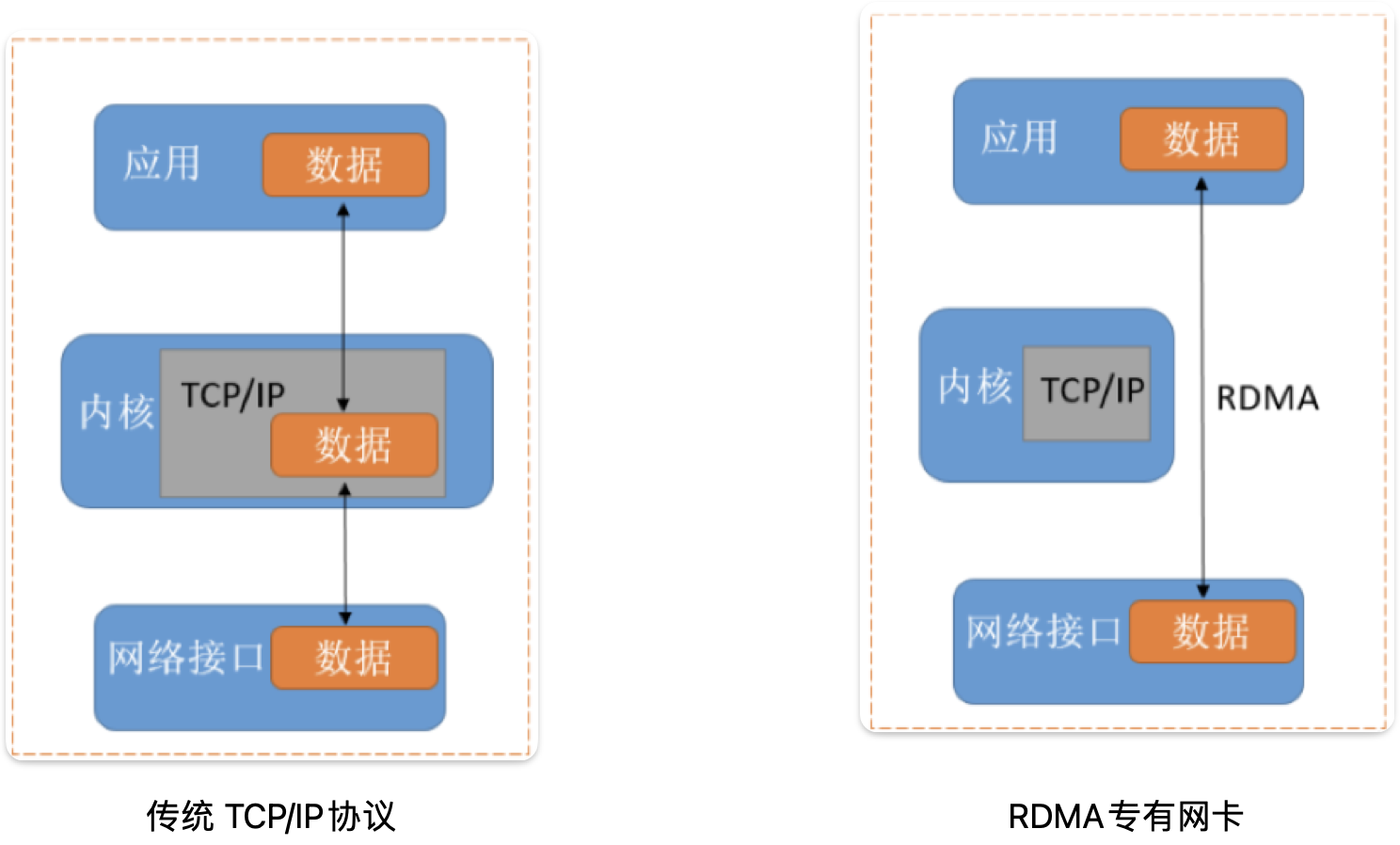
MPI 和 RDMA 之间有何种联系 ?
因为 MPI 需要发生多节点之间的通信,而这个数据传输过程如果发生在传统的 TCP/IP 网络中,必然要经过 己方CPU -> 己方网卡NIC -> 对方NIC -> 对方CPU 这样一个过程,这无疑会给 CPU 带来一定计算开销,然而在网络通信中所涉及的计算无非就是一些路由信息的计算,这些工作完全可以交由 NIC 来处理,所以可以通过增强 NIC 的计算能力,让 CPU 从这一通信过程中摘离,即实现 RDMA。
目前 3 种 RDMA 网络:
- Infiniband
- RoCE
- iWARP (传输层之上)
Reference
- [1] MPI Tutorial
- [2] MPICH API Document
- [3] 一切靠自己的 MPI 框架