SIMD Extension
说明
SIMD Extension 的各种函数中参数的顺序以及各种函数的实现机制都是遵循着机器在实际存储时采用的小端序,注意在和数组混用时可能会产生一定思维上的混乱。
Categories
Hot to check the SIME extension support of cpu ?
| |
- For x86 instruction set
- MMX
- SSE (Streaming SIMD extensions)
- AVX (Advanced Vector Extensions)
- AVX2
- AVX512
etc
- For ARM instruction set
- NEON
- AVX
Usage of SIMD intrinsic
header file
If you don’t know which header file to include, please find the function you want to call in Intel Intrinsics Guide,when you launch the detail of function, you will find the header file you need to include.
| |
But there is a saying that
These days you should normally just include
<immintrin.h>. It includes everything. 1
After actual testing(use SSE2 but include the <immintrin.h>), this statement has no problem.
compile option
| |
You can search more compile options in gnu Option Summary | x86 Options.
Data load and store
The quantity of load and store function is limited. Taking functions for handling float date types as an example, there are only 4 most commonly used functions for loading and storing:
__m256d _mm256_load_pd (double const * mem_addr)__m256d _mm256_loadu_pd (double const * mem_addr)void _mm256_store_pd (double * mem_addr, __m256d a)void _mm256_storeu_pd (double * mem_addr, __m256d a)
What we need to pay attention to is that what are the judgement strategy differences between aligned data and non aligned data when these functions executing.
About the knowledge of data align, you can reference this article, we will not talk it repeatly here.
Before we give the right answer of this question, we can see some code snippets
This is a plain version of $ x = a \times x $ implementation.
| |
We can use SIMD extension to optimize the above code.
- If we use the first line
sse_sapxyfunction call, we will get “Segmentation fault (core dumped)”. - If we use the second line code, we will get the right result.
- If we use the third line code, we will get the wrong result but we will not get the “Segmentation fault (core dumped)”.
| |
Now, let’s see the right implementation of SIMD extension optimize version code
| |
Why we get the above result, the reason is that b and b + 4 is satisfied with the data aligned requirement of _mm_load_ps and _mm_store_ps, but b + 1 isn’t satisfied with it, so we should use right load and store function for one data.
simd extension 提供给用户的就是这么一条指令,但是在底层执行时,如果是确定地址对齐的数据,在load时只需要进行一次内存访问,就可以将所有数据加载到 vector register 中了。
但是如果地址不对齐的数据,这部分数据是可能跨越memory page 的,那么底层在执行时,对于这部分数据的访问就可能需要多次内存访问,最终需要将多次内存访问读取到的数据都合并到一个 vector register 中,合并数据是需要额外的操作逻辑的,所以这里又提供了一个新的函数单独做非对齐数据的加载。
实际上,从一个库的实现角度来说,这里有两种实现思路,一种是封装层次更高的,即只给上层用户提供一个简单的load函数,由函数实现本身来区分数据是否对齐,另一种就是目前的由用户来显式指定,之所以采用后者,我觉得可能是因为这些函数本身就是比较底层的概念了,没必要实现太高层次的封装,级别更高层次的封装往往都是框架来做的。
At last, we can see a further optimized version, when judge the aligned data, this code uses the pointer directly, save the data copy time from memory to vector register.
| |
Data process
Vector Addition
| |
Horizontal Addition
The effect of this function is confusing, because it store the two array’s adjacent data sum crossly. I can not image the usage in realistic scenes.
| |
The result of the above code is
2 6 4 8
Compare
__m256d _mm256_cmp_pd (__m256d a, __m256d b, const int imm8)
According to the third parameter to compare the data from first and second vector, and output the result to a __m256d vector.
The third parameter value and its corresponding meaning are shown in the table below.
| imm8[4:0] | 操作符 | 含义 |
|---|---|---|
| 0 | _CMP_EQ_OQ | 比较两个操作数是否相等(Ordered, Quiet) |
| 1 | _CMP_LT_OS | 比较第一个操作数是否小于第二个操作数(Ordered, Signaling) |
| 2 | _CMP_LE_OS | 比较第一个操作数是否小于等于第二个操作数(Ordered, Signaling) |
| 3 | _CMP_UNORD_Q | 比较两个操作数是否未排序(Unordered, Quiet) |
| 4 | _CMP_NEQ_UQ | 比较两个操作数是否不相等(Unordered, Quiet) |
| 5 | _CMP_NLT_US | 比较第一个操作数是否不小于第二个操作数(Unordered, Signaling) |
| 6 | _CMP_NLE_US | 比较第一个操作数是否不小于等于第二个操作数(Unordered, Signaling) |
| 7 | _CMP_ORD_Q | 比较两个操作数是否有序(Ordered, Quiet) |
| 8 | _CMP_EQ_UQ | 比较两个操作数是否相等(Unordered, Quiet) |
| 9 | _CMP_NGE_US | 比较第一个操作数是否不大于等于第二个操作数(Unordered, Signaling) |
| 10 | _CMP_NGT_US | 比较第一个操作数是否不大于第二个操作数(Unordered, Signaling) |
| 11 | _CMP_FALSE_OQ | 始终返回假(Ordered, Quiet) |
| 12 | _CMP_NEQ_OQ | 比较两个操作数是否不相等(Ordered, Quiet) |
| 13 | _CMP_GE_OS | 比较第一个操作数是否大于等于第二个操作数(Ordered, Signaling) |
| 14 | _CMP_GT_OS | 比较第一个操作数是否大于第二个操作数(Ordered, Signaling) |
| 15 | _CMP_TRUE_UQ | 始终返回真(Unordered, Quiet) |
| 16 | _CMP_EQ_OS | 比较两个操作数是否相等(Ordered, Signaling) |
| 17 | _CMP_LT_OQ | 比较第一个操作数是否小于第二个操作数(Ordered, Quiet) |
| 18 | _CMP_LE_OQ | 比较第一个操作数是否小于等于第二个操作数(Ordered, Quiet) |
| 19 | _CMP_UNORD_S | 比较两个操作数是否未排序(Unordered, Signaling) |
| 20 | _CMP_NEQ_US | 比较两个操作数是否不相等(Unordered, Signaling) |
| 21 | _CMP_NLT_UQ | 比较第一个操作数是否不小于第二个操作数(Unordered, Quiet) |
| 22 | _CMP_NLE_UQ | 比较第一个操作数是否不小于等于第二个操作数(Unordered, Quiet) |
| 23 | _CMP_ORD_S | 比较两个操作数是否有序(Ordered, Signaling) |
| 24 | _CMP_EQ_US | 比较两个操作数是否相等(Unordered, Signaling) |
| 25 | _CMP_NGE_UQ | 比较第一个操作数是否不大于等于第二个操作数(Unordered, Quiet) |
| 26 | _CMP_NGT_UQ | 比较第一个操作数是否不大于第二个操作数(Unordered, Quiet) |
| 27 | _CMP_FALSE_OS | 始终返回假(Ordered, Signaling) |
| 28 | _CMP_NEQ_OS | 比较两个操作数是否不相等(Ordered, Signaling) |
| 29 | _CMP_GE_OQ | 比较第一个操作数是否大于等于第二个操作数(Ordered, Quiet) |
| 30 | _CMP_GT_OQ | 比较第一个操作数是否大于第二个操作数(Ordered, Quiet) |
| 31 | _CMP_TRUE_US | 始终返回真(Unordered, Signaling) |
set
__m256d _mm256_set_pd (double e3, double e2, double e1, double e0)
This funciont doesn’t have any special effect, it just set value for a vector register. What we need to pay attention to is that the order of the parameters of this function.
The order of this function follows the real store order of machine, i.e. little-endian(小端序,低有效字节存储在低位,最右侧的位置就是低有效字节以及低位,所以所这种布局遵循了机器的小端序)
insert
insert a __m128d vector data into __m256d vector data.
| |
The result of the above program is that
dst0: 5 6 3 4
dst1: 1 2 5 6
Permute
__m256d _mm256_permute4x64_pd (__m256d a, const int imm8)
According to the imm8 to select the data in a and put it into a __m256d vector register.
What we should pay attention to is that imm8 is a hexadecimal data, for example, if we want to express 11111111, we should use the 0xFF.
| |
0xE4 is 11100100, i.e. it corresponding to the order of array a. So the result is
1 2 3 4
blend
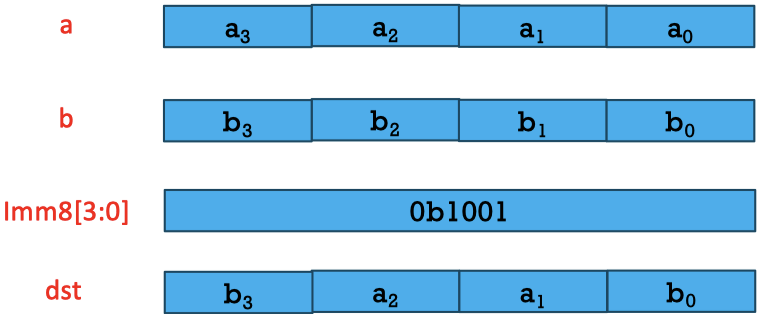
Traverse the imm from the LSB to HSB, if the bit value is 1, select b data and put it into the result vector resigter, other wise select a data.
| |
1010 is mapping to the baba, so when we output the dst data from low byte to high byte, we will get the “a b a b”, i.e. the result of this program is “1 6 3 8”.
broadcast
| |
The result is
1 2 1 2