Linux Device Drivers
层次结构
在了解驱动程序的具体内容之前,我们可以首先从 Nvidia GPU 所提供的一些 API 层级入手来理解整体的结构,下图展示了上层应用程序在使用 cudaMalloc 时的调用流程图,其中的重点就是 Runtime API, Driver API 和 驱动程序。
sequenceDiagram
participant App
participant RuntimeAPI
participant DriverAPI
participant KernelDriver
participant GPU
App->>RuntimeAPI: cudaMalloc(&d_A, size)
RuntimeAPI->>DriverAPI: cuMemAlloc(&d_A, size)
DriverAPI->>KernelDriver: ioctl(NV_IOCTL_MEM_ALLOC)
KernelDriver->>GPU: 配置GPU MMU页表
GPU-->>KernelDriver: 返回物理地址
KernelDriver-->>DriverAPI: 虚拟地址映射
DriverAPI-->>RuntimeAPI: 成功状态
RuntimeAPI-->>App: 返回d_AsequenceDiagram
participant App
participant RuntimeAPI
participant DriverAPI
participant KernelDriver
participant GPU
App->>RuntimeAPI: cudaMalloc(&d_A, size)
RuntimeAPI->>DriverAPI: cuMemAlloc(&d_A, size)
DriverAPI->>KernelDriver: ioctl(NV_IOCTL_MEM_ALLOC)
KernelDriver->>GPU: 配置GPU MMU页表
GPU-->>KernelDriver: 返回物理地址
KernelDriver-->>DriverAPI: 虚拟地址映射
DriverAPI-->>RuntimeAPI: 成功状态
RuntimeAPI-->>App: 返回d_A从这个调用顺序图中,我们就可以看出不同层次 API 大概的实现方式(以下代码并不代码真实实现,仅用于表述大致的实现逻辑),如下方代码所示,Runtime API 在实现时会调用 Driver API,Driver API 在实现时则会调用 ioctl,驱动程序则是完成了一些 ioctl 信号对应的具体逻辑
| |
从这里的伪代码我们可以发现一个问题,即 Runtime API 和 Driver API 的实现过程都存在明确可调用其他API,但是 driver 已经属于软件层中的最底层了,下层就直接同硬件对接了,它在实现时该如何处理才能做到同硬件的交互。
之所以产生这个疑问,是因为有一个错误理解,即“driver 已经属于软件层中的最底层了“。实际上在 driver 之下,还存在着内核代码这样一层软件,它才是直接对接硬件的最下层软件。所以 driver 在实现时也是存在可调用的 API 的,即 Linux 内核原生 API。
那么问题就变为了通过 Linux 原生 API 我们可以如何对接硬件。
在此之前,需要明确一件事情,即一个 PCIe 设备的必备条件:
根据PCIe规范(PCI Express Base Specification),所有合规的PCIe设备必须包含以下要素:
- PCI 配置空间(包括标准的64字节Header + 扩展空间)
- 至少一个BAR(用于映射设备寄存器或内存区域)
- PCIe Capability 结构(标识其为 PCIe 设备而非传统 PCI)
如果设备完全没有 BAR 空间,它甚至无法通过 PCIe 枚举阶段的配置,操作系统会直接将其视为不完整设备而忽略。
也就是说,如果硬件的功能比较简单,可能只利用 PCIe 规范的内容就可以完成了,
不过如果硬件的功能相对复杂,PCIe 规范的内容就不足以支撑我们的需求了,这时候就需要硬件在设计时增加额外的配置寄存器,驱动程序直接对这些寄存器进行操作从而配置更加复杂的硬件功能(不过本质都是寄存器),这两种方式的对比如下图所示。
| 方式 | PCIe BAR空间访问 | 直接硬件操作 |
|---|---|---|
| 标准化程度 | 遵循PCIe规范,通用性强 | 设备私有,厂商特定 |
| 内核API | pci_iomap/ioread32等 | 相同API,但操作非标准寄存器 |
| 安全性 | 受PCIe协议保护 | 需驱动自行验证参数 |
| 典型用途 | 设备发现、基础寄存器访问 | 性能优化、高级功能控制 |
了解了与硬件交互的两种模式后,还需要明确一下驱动程序应该使用哪些内核 API 才能达到访问这些寄存器的目的。
- PCIe设备基础配置
| API类别 | 函数/宏 | 作用 |
|---|---|---|
| 设备枚举 | pci_get_device() | 通过Vendor/Device ID查找设备 |
| pci_get_domain_bus_and_slot() | 通过域/总线/插槽号查找设备 | |
| 配置空间访问 | pci_read_config_byte/word/dword() | 读取PCIe配置空间(8/16/32位) |
| pci_write_config_byte/word/dword() | 写入PCIe配置空间 | |
| Bus Mastering | pci_set_master() | 启用设备的总线主控能力(允许发起DMA) |
- BAR空间管理
| API类别 | 函数/宏 | 作用 |
|---|---|---|
| 资源探测 | pci_resource_start() | 获取BAR的物理起始地址 |
| pci_resource_len() | 获取BAR的大小 | |
| pci_resource_flags() | 获取BAR的类型(MEM/IO, 预取等) | |
| 内存映射 | pci_iomap() | 映射BAR空间到内核虚拟地址(自动处理类型) |
| pci_iounmap() | 解除映射 | |
| 旧版映射 | ioremap() | 映射物理地址到内核虚拟地址(通用) |
| iounmap() | 解除映射 |
- MMIO寄存器操作
| API类别 | 函数/宏 | 作用 |
|---|---|---|
| 标准访问 | ioread8/16/32/64() | 从MMIO区域读取数据(8/16/32/64位) |
| iowrite8/16/32/64() | 向MMIO区域写入数据 | |
| 内存屏障 | mmiowb() | 写内存屏障(保证MMIO写入顺序) |
| readl_relaxed() / writel_relaxed() | 无屏障版本的读写(性能优化场景) |
- DMA控制
| API类别 | 函数/宏 | 作用 |
|---|---|---|
| 通用DMA | dma_alloc_coherent() | 分配一致性内存(CPU和设备均可访问) |
| dma_free_coherent() | 释放一致性内存 | |
| dma_map_single() | 映射主机内存供设备DMA使用 | |
| dma_unmap_single() | 解除映射 | |
| 流式DMA | dma_map_sg() | 映射分散-聚集(Scatter-Gather)列表 |
| dma_unmap_sg() | 解除映射 | |
| 地址转换 | virt_to_phys() | 虚拟地址转物理地址(仅限内核直接映射区) |
| dma_map_resource() | 映射设备内存(如显存)到主机地址空间 |
- 中断处理
| API类别 | 函数/宏 | 作用 |
|---|---|---|
| 中断注册 | request_irq() | 注册中断处理函数 |
| devm_request_irq() | 设备管理的中断注册(自动释放) | |
| request_threaded_irq() | 注册线程化中断处理函数 | |
| MSI/MSI-X | pci_alloc_irq_vectors() | 分配MSI/MSI-X中断向量 |
| pci_free_irq_vectors() | 释放中断向量 | |
| 中断控制 | disable_irq() / enable_irq() | 禁用/启用中断 |
除了 API 层面的关系比较容易混乱,我们也很容易混淆“内核代码API”,“库函数”以及”系统调用“这些概念。
比如说,我们常说read(), write()这些"系统调用"以统一形式的访问接口屏蔽了底层的硬件细节,包括read(2) — Linux manual page官方文档中也将read()归到了"System Calls Manual"中。它们的实现到底位于哪一层?为什么我们会称它们就是系统调用?
wikipedia对于"system call"给出的定义如下。
a system call (syscall) is the programmatic way in which a computer program requests a service from the operating system on which it is executed1
可见,系统调用实际上是一种请求操作系统服务的一种编程方式(这里补充一点,系统调用一个关键过程是实现了用户态和内核态的转换),而之所以将 read(), write() 这些函数称为系统调用,是因为它们需要同硬件交互确实是需要由操作系统提供支撑的(不过我理解直接称它们为系统调用还是不太准确,因为系统调用的定义明确给出它是一种“方式”而不是一些具体的函数,如果说这些函数实现或者包含了系统调用的过程可能更准确一些,不过为了描述上的统一,下文依然直接将其称之为系统调用)。
从定义来看其实也纠正了我们之前理解上的错误,此前我们一直认为系统调用应该是和“内核代码”处在同一个层次的概念,所以当我们在read(2) — Linux manual page文档中,发现 read(), write() 还属于“Standard C library”就会感觉到很迷惑(因为当我们对于“库”的理解就是一个高于内核代码更靠近用户的一个层次)。
截止到目前,对各个概念的理解依然是非常混乱的,我理解原因在于“系统调用”和"内核代码API", “库函数"并不是同一个视角下的概念。比如 read() 属于系统调用是从它的实现模式上来说,属于库函数是从它的实现层次上来说,而系统调用和库函数往往会在一个上下文下掺杂着来讨论,所以也就会觉得混乱了。所以为了更清晰地了解整个过程,下文我们只基于代码具体是如何实现的这个视角来梳理整个调用流程。
| |
各个层次之间更详细的交互关系如下图所示。
flowchart TD
%% ================= 用户空间 =================
subgraph UserSpace["用户空间 (Ring 3)"]
App["应用程序"]
Glibc["glibc库"]
Wrapper["系统调用包装器"]
SyscallNum["SYS_read 系统调用号"]
App -->|"调用库函数
例如 read()"| Glibc
App -.->|"常说的
“系统调用”"| Glibc
Glibc --> Wrapper
Wrapper -->|"参数检查
错误处理
缓冲管理"| SyscallNum
end
%% ================= 特权切换 =================
subgraph Transition["CPU 特权切换"]
direction LR
SyscallNum -->|"触发"| CPU["CPU 指令"]
CPU -->|"x86: syscall/sysenter
ARM: svc
RISC-V: ecall"| ModeSwitch["模式切换
(Ring 3 → Ring 0)"]
end
%% ================= 内核空间 =================
subgraph KernelSpace["内核空间 (Ring 0)"]
direction TB
Entry["系统调用入口"]
SysHandler["sys_read()"]
KernelAPI["ksys_read()"]
VFS["VFS 层:vfs_read"]
Driver["设备驱动程序"]
CopyData["copy_to_user()
复制数据到用户空间"]
ReturnToUser["返回用户空间"]
ModeSwitch --> Entry
Entry -->|"查表分发:sys_call_table"| SysHandler
SysHandler -->|"参数验证
权限检查"| KernelAPI
KernelAPI -->|"调用"| VFS
VFS -->|"文件系统驱动
页缓存管理"| Driver
Driver --> CopyData
CopyData --> ReturnToUser
ReturnToUser --> App
end
%% ================= 硬件层 =================
subgraph Hardware["硬件层"]
Disk["磁盘控制器"]
MMU["MMU:地址转换"]
end
Driver --> |"读取数据"| Disk
CPU -.-> MMU
%% ================= 术语映射 =================
Glibc -.->|"实际的
“系统调用过程”"| SysHandler
CPU -.->|"CPU 指令层面的
“系统调用”"| ModeSwitch
KernelAPI -.->|"内核内部视角的
“系统调用实现”"| VFS
%% ================= 样式定义 =================
classDef user fill:#E1F5FE,stroke:#039BE5,stroke-width:2px
classDef kernel fill:#FFEBEE,stroke:#F44336,stroke-width:2px
classDef hardware fill:#E8F5E9,stroke:#4CAF50,stroke-width:2px
classDef transition fill:#FFF3E0,stroke:#FFA000,stroke-width:2px
class App,Glibc,Wrapper,SyscallNum user
class CPU,ModeSwitch,Entry,SysHandler,KernelAPI,VFS,Driver,CopyData,ReturnToUser kernel
class Disk,MMU hardware
class CPU,ModeSwitch transitionflowchart TD
%% ================= 用户空间 =================
subgraph UserSpace["用户空间 (Ring 3)"]
App["应用程序"]
Glibc["glibc库"]
Wrapper["系统调用包装器"]
SyscallNum["SYS_read 系统调用号"]
App -->|"调用库函数例如 read()"| Glibc App -.->|"常说的
“系统调用”"| Glibc Glibc --> Wrapper Wrapper -->|"参数检查
错误处理
缓冲管理"| SyscallNum end %% ================= 特权切换 ================= subgraph Transition["CPU 特权切换"] direction LR SyscallNum -->|"触发"| CPU["CPU 指令"] CPU -->|"x86: syscall/sysenter
ARM: svc
RISC-V: ecall"| ModeSwitch["模式切换
(Ring 3 → Ring 0)"] end %% ================= 内核空间 ================= subgraph KernelSpace["内核空间 (Ring 0)"] direction TB Entry["系统调用入口"] SysHandler["sys_read()"] KernelAPI["ksys_read()"] VFS["VFS 层:vfs_read"] Driver["设备驱动程序"] CopyData["copy_to_user()
复制数据到用户空间"] ReturnToUser["返回用户空间"] ModeSwitch --> Entry Entry -->|"查表分发:sys_call_table"| SysHandler SysHandler -->|"参数验证
权限检查"| KernelAPI KernelAPI -->|"调用"| VFS VFS -->|"文件系统驱动
页缓存管理"| Driver Driver --> CopyData CopyData --> ReturnToUser ReturnToUser --> App end %% ================= 硬件层 ================= subgraph Hardware["硬件层"] Disk["磁盘控制器"] MMU["MMU:地址转换"] end Driver --> |"读取数据"| Disk CPU -.-> MMU %% ================= 术语映射 ================= Glibc -.->|"实际的
“系统调用过程”"| SysHandler CPU -.->|"CPU 指令层面的
“系统调用”"| ModeSwitch KernelAPI -.->|"内核内部视角的
“系统调用实现”"| VFS %% ================= 样式定义 ================= classDef user fill:#E1F5FE,stroke:#039BE5,stroke-width:2px classDef kernel fill:#FFEBEE,stroke:#F44336,stroke-width:2px classDef hardware fill:#E8F5E9,stroke:#4CAF50,stroke-width:2px classDef transition fill:#FFF3E0,stroke:#FFA000,stroke-width:2px class App,Glibc,Wrapper,SyscallNum user class CPU,ModeSwitch,Entry,SysHandler,KernelAPI,VFS,Driver,CopyData,ReturnToUser kernel class Disk,MMU hardware class CPU,ModeSwitch transition
IO 设备
IO 设备的基本形态就是一些寄存器(以及一些 protocol,说明在寄存器接收到某些值时要做出何种处理) + 控制器,从而能够与 CPU 交互数据,通过 mmap 的方式映射到内存空间中,CPU 可以对这些寄存器的值进行修改
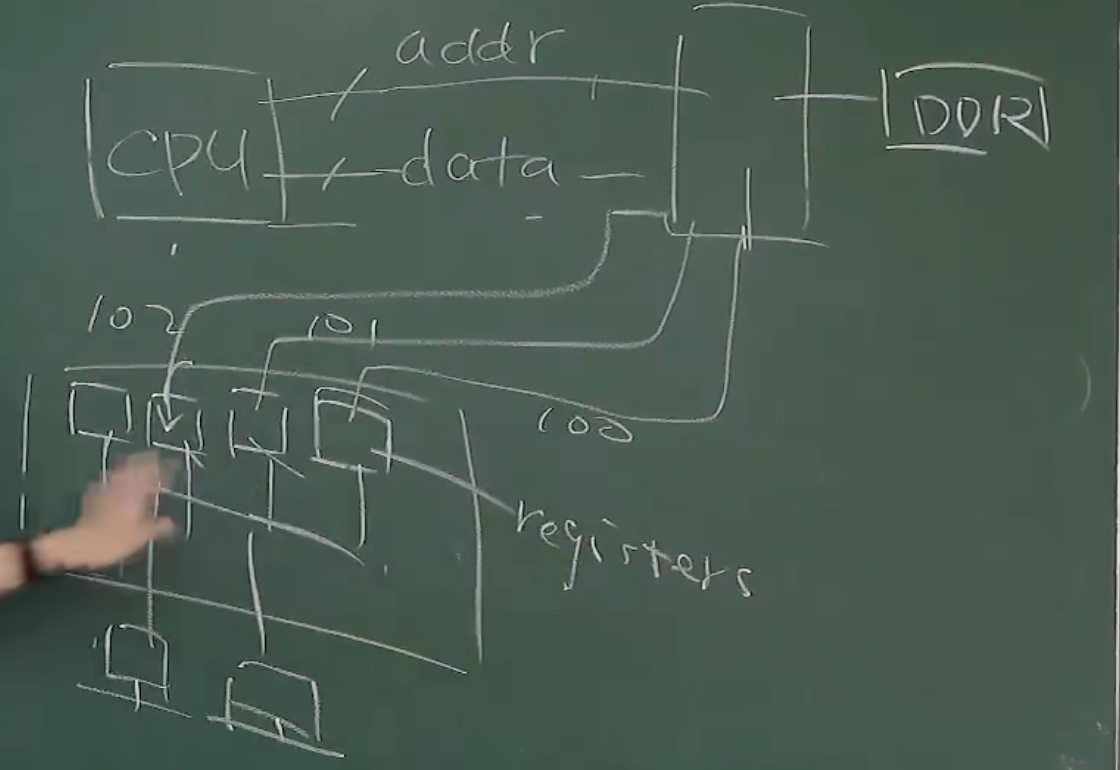
实际只直接连接了总线一个设备(总线也是一个设备,CPU 仅连接这一个设备,其他设备连接在总线上),其他设备被总线虚拟化,并且挂载在总线上,形成一个树状分层结构,分层是逐层虚拟化的结果
文件系统
Linux 系统中的 /proc 目录是一个虚拟文件系统。它提供了内核和系统进程的动态信息,实际上并不占用硬盘空间,而是直接从内存中生成,反映当前内核和进程的实时状态。
- 进程信息
每个正在运行的进程都有一个对应的目录,名称就是进程的 PID(进程号),如 /proc/1/。
这些进程目录下包含进程的详细信息:
- cmdline:进程的启动命令
- status:进程的状态信息,包括 PID、父进程 PID、内存使用情况等
- fd/:进程打开的文件描述符
- maps:进程的内存映射情况
- 系统信息文件
- /proc/cpuinfo:CPU 的信息,比如型号、核心数、频率等。
- /proc/meminfo:内存的使用情况,比如总内存、空闲内存等。
- /proc/uptime:系统已运行的时间。
- /proc/version:Linux 内核的版本信息。
- /proc/loadavg:系统的平均负载情况。
- 硬件设备相关信息
- /proc/interrupts:显示系统的中断请求(IRQ)使用情况。
- /proc/ioports:显示分配给硬件设备的 I/O 端口信息。
- /proc/partitions:列出系统中的分区信息。
- 内核参数
- /proc/sys/:内核参数配置的目录。可以通过这个目录读取或写入一些内核参数来调整系统行为。比如 /proc/sys/net/ipv4/ip_forward 控制 IP 转发功能。
驱动程序
驱动程序所做的就是对设备寄存器的一层封装,简单来理解,用户期望对设备进行的操作最终到硬件上都将转换为对于设备寄存器的访问,硬件电路是具有一些基础性的功能的,当期望使用这些功能时,只需要向一些寄存器中写入数据即可,较复杂的功能也不过是这些简单功能的叠加,所以驱动程序可以将一些复杂动作所对应的寄存器操作序列封装为接口,上层看到的只是这些接口,并不关心想要实现这些功能时到底需要向哪些寄存器写入哪些值。例如 Capric 卡上 DMA 读功能的实现:
- 填写 RD_DMA_ADR 寄存器, 注意此处填写的是 PCI 总线域的地址。
- 填写 RD_DMA_SIZE 寄存器, 以字节为单位。
- 填写 DCSR2 寄存器的 mrd_start 位, 启动 DMA 读。
- 等待 DMA 读完成中断产生后, 结束 DMA 读。
上述过程中,前两点的数据填充并不难理解,第三点通过向寄存器写入值开启 DMA 过程更给人启发。
理解驱动程序,从最上层考虑,以打印机为例,使用者执行了一个动作,这个动作触发了系统调用,系统调用又转换到驱动程序,驱动程序进行翻译工作,将这个动作信号翻译为设备所能理解的数据。
所以比较令人困惑的是,这种翻译到底是将什么翻译为了什么?
目前来理解,驱动程序在实现时,核心操作就是对于寄存器的读写,无论是数据寄存器还是配置寄存器。
驱动程序就是一段内核代码,所以并不一定有真实的物理设备,它只对应于一种翻译逻辑。
设备驱动程序的职责是把系统调用 “翻译” 成与设备能听懂的数据(在 jyy 所提供的实例中,设备实际是两个虚拟设备)我们可以通过实现 file_operations 中相应的操作,从而模拟一个设备。
因为 “everything is file”,所以设备本身也是 file,所以驱动程序代码完成的就是对于文件的读写操作,只不过需要写入的数据是需要设备所能够理解的。
Linux 中对于 /dev/null 的实现,这就能理解为什么向这个字符写入数据时,数据总是能够被吞噬掉
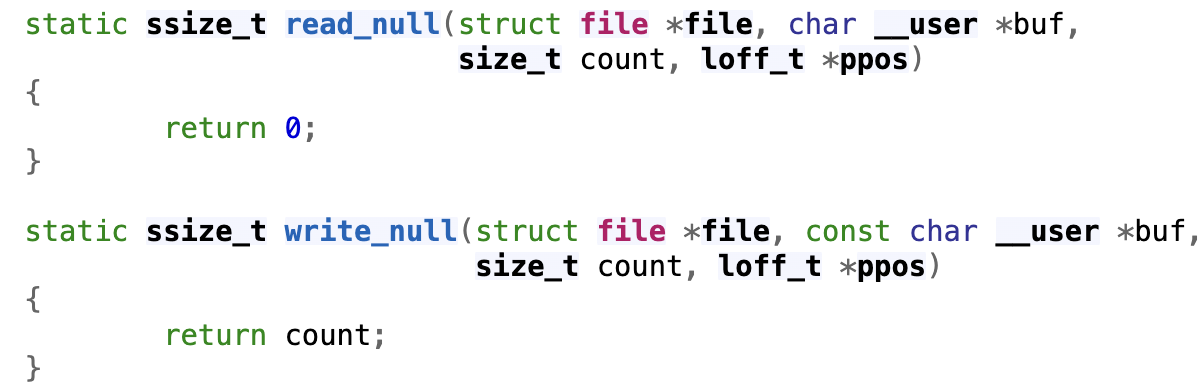
操作系统内核的标准系统调用可以处理简单的文件和设备操作,但是无法满足对于设备更加复杂的控制功能,ioctl 可以轻松扩展系统与设备的交互能力
通过 ioctl 机制,可以在用户态使用提前定义好的命令码与设备驱动程序通信,执行特定于设备的控制或配置功能,从而补充操作系统内核的标准系统调用不能满足的设备操作需求。
- 命令码的定义: 驱动程序开发者需要定义一组命令码,每个命令码对应一个特定的设备操作。这些命令码通常是通过宏定义的,使用了位操作来区分命令的类型和数据方向(输入或输出)。
| |
- 驱动程序的实现: 在设备驱动程序中,需要实现对这些命令码的处理逻辑。通常,驱动会通过 file_operations 结构体的 unlocked_ioctl 或 compat_ioctl 成员函数,来处理这些 ioctl 请求。
| |
- 用户态调用 ioctl: 用户态程序可以通过调用 ioctl(),并传入文件描述符、命令码及可选参数来与驱动程序通信。驱动会根据传入的命令码,执行相应的操作。
| |
驱动程序无论是直接编译到内核还是以模块的方式挂载到内核上,本质上驱动程序的执行都应该是属于内核态的,那么上层应用程序如果希望利用上驱动程序与设备进行交互,那就还是需要通过系统调用,借助操作系统来对设备进行操作。那么 sdk 完成的是否就是对于这个请求系统调用过程的封装?
从 jyy 老师的这个课程中理解到的驱动程序,它通过自定义实现 launcher_read 和 launcher_write,并且在 file_operations 中指定这两个函数,从而规定了设备在面对读操作和写操作时的应对方法,所以驱动程序确实就是将设备作为文件来看待,规定文件读写操作时的操作方法。
驱动 操作系统 层次关系
硬件抽象层(HAL),操作系统对具体的硬件进行抽象,向上层软件提供 API。在 PCI 的情况下,内核代码中的 PCI 子系统即相当于这一抽象层。
PCI 本身具有一定标准,PCI 子系统只需要遵循这个标准,就可以和设备进行一些例如识别设备在内的一些基础性的交互。
如何理解“驱动程序可以提供更高级别的抽象,让系统更好地利用设备的功能“这句话?
首先这确实是驱动程序的功能,但是该如何理解这种”抽象“。举一个简单的例子,向磁盘和网卡写入数据,两种设备的硬件组成(寄存器)一定是不同的,那么写操作也不相同,通过 PCI 子系统的 API 也是可以完成的,但是要复杂很多,驱动程序可以抽象出一个通用的 write() 接口 API,从而简化这种操作。
第三方库
并不类似于 C 语言能够使用很多第三方库,在编写驱动程序时,只能使用一些内核代码中提供的函数,例如 printk()
printk() 支持的消息等级:
| 消息类型 | 描述 |
|---|---|
| KERN_EMERG | 紧急消息, 常常是那些崩溃前的消息 |
| KERN_ALERT | 需要立刻动作的情形 |
| KERN_CRIT | 严重情况, 常常与严重的硬件或者软件失效有关 |
| KERN_ERR | 错误情况,常用于报告硬件故障 |
| KERN_WARNING | 警告 |
| KERN_NOTICE | 正常情况,存在一些安全相关的报告 |
| KERN_INFO | 信息 |
| KERN_DEBUG | 调试消息 |
kernel
dmesg 可以显示内核日志信息中(实际是指的是内核环形缓冲区)
开发模式
驱动程序的开发模式是事件驱动的编程,例如
模块初始化函数所做的类似于它自身在说:“我在这里,这是我能做的”
模块退出函数所做的类似于它自身在说:“我不再在那里了,不要要求我做任何事了”
模块开发并不能链接其他库,它所能使用的只能是内核代码中的内容(有唯一的一个例外是<stdarg.h> )
用户态和内核态有独立的内存地址空间
内核代码的执行是并发的,因此它的设计必须能够可重入(能够同时在多个上下文运行)
相关命令
insmod:挂载一个模块rmmod:去除一个模块lsmod: 获取当前加载的模块 等价于读取/proc/modules或/sys/module
描述性定义
MODULE_AUTHOR: 声明谁编写了模块MODULE_DESCRIPION: 模块具体描述MODULE_VERSION: 代码修订版本号MODULE_ALIAS: 模块别名MODULE_DEVICE_TABLE: 模块支持的设备列表
传递参数
| |
概念辨析
- 操作系统 API
- 库函数
- 系统调用
这部分可以补充一个“从文件读写了解这些概念”这样一个内容
目前了解到的内容:
内核代码中大概包含了两部分:
- 系统调用(System Calls): 名称均以
sys_开头, 用户空间应用与内核通信的唯一标准接口 - 内核函数(Kernel Functions): 内部调用接口,不能直接被用户空间应用访问
chatgpt 给出的流程,但是我觉得还是有些问题的,更常见的场景是用户空间的程序通过 glibc(GNU C Library)或者其他标准库中的包装函数,后面通过中断号找到对应的系统调用函数
- 用户空间应用通过标准库调用系统调用接口(如 open())。
- 系统调用通过特定的硬件指令(如 syscall 或 int 0x80)陷入内核空间。
- 内核根据系统调用号,定位到相应的 sys_* 函数(如 sys_open())。
- sys_* 函数调用一系列内核内部函数来完成任务,最后将结果返回给用户空间。
ioctl
允许用户态程序通过文件描述符向设备驱动程序发送控制命令并接收返回的结果。
典型的用法是传递控制命令和数据缓冲区。
设备节点作为应用程序和驱动程序(操作系统)沟通的桥梁,用来使双方传输数据
驱动程序如何维护 ioctl 所使用的标识和对应的操作之间的映射关系?
file_operations结构体的unlocked_ioctl成员指向具体的ioctl处理函数,例如pGbl_DriverObject->DispatchTable.unlocked_ioctl = Dispatch_IoControl;处理函数根据
cmd的值(所谓的 ioctl 使用的标识)执行不同的处理逻辑,例如
| |
检查系统中驱动情况
find /lib/modules/$(uname -r) -type f -name "*plx*"
同时结合 modinfo 命令
不过似乎上述位置能够找到的 module,是经过了 modprobe 处理了依赖关系后的,insmod 不会自动处理依赖关系或将模块安装到此路径下。
PCI PCIe
检查 PCIe 设备及查看驱动
| |
lsmod 查看已经加载到内核中的模块
PCI: 局部总线(连接外部设备),系统总线(CPU 连接 Cache 和 主存)的延伸。
PCI: 并行总线;PCIe:高速串行总线
处理器需要通过 HOST 主桥才能访问 PCI 设备, 而 PCI 设备需要通过 HOST 主桥才能访问主存储器
主板上的 PCIe 有接口和通道两种模式
- 接口:
PCIe 设备:显卡,固态,无线网卡,有线网卡,声卡,视频采集卡,PCIe 转接其他接口(高带宽需求的外部设备)
- 通道
m2 固态硬盘接口外形是 m2,但是实际数据传输依赖的是 PCIe
雷电 3 接口也是利用了 PCIe 通道来达到高带宽
带宽分配(按照长度分配):PCIe x1,x2,x4,x8,x16(x16 的带宽是 x8 的 2倍),可以将 x16 的设备插在较短的 PCIe 槽中运行,但是没办法发挥全部性能,也可以将较短的设备插在较长的槽中运行,但是会浪费带宽(满血,残血指的是设备长度长于插槽长度的情况)
| x1 | x2 | x4 | x8 | x16 | |
|---|---|---|---|---|---|
| PCI-e 1.0 | 250 MB/s | 500 MB/s | 1 GB/s | 2 GB/s | 4 GB/s |
| PCI-e 2.0 | 500 MB/s | 1 GB/s | 2 GB/s | 4 GB/s | 8 GB/s |
| PCI-e 3.0 | 1 GB/s | 2 GB/s | 4 GB/s | 8 GB/s | 16 GB/s |
| PCI-e 4.0 | 2 GB/s | 4 GB/s | 8 GB/s | 16 GB/s | 32 GB/s |
PCI 驱动程序加载流程
module_init(): 更高层次的,专门用于模块初始化。指定模块加载时的初始化函数,它的作用范围是整个模块,而不仅限于某种特定的硬件。pci_register_driver(): 专门用于向内核注册 PCI 驱动程序的,它只能在 PCI 驱动程序中使用,并且其作用是告诉内核该驱动能够处理哪些 PCI 设备。(USB 设备的注册函数是usb_register_driver())2
因为注册驱动程序的本质就是让操作系统内核了解到该用哪些函数来对应中断信号,因此这些特定于设备的驱动注册函数一定是操作系统标准库提供的(include/linux/pci.h, 内核中的 PCI 子系统 API)。
模块加载 -> 执行 module_init 宏中指定的初始化函数 → 在该函数中调用 pci_register_driver 将驱动程序注册到内核。
结构
Host 端 CPU 芯片或主板的北桥上有一个 Root Complex (RC) 芯片(可能已经集成到 CPU 上了), 负责与设备端的 PCIe 端点(Endpoints)通信。
Device 端有一个Endpoint (EP),通过 PCIe 与 Root Complex 通信,充当这个 EP 的可能就是 PLX 芯片了,不过类似 RC,可能已经集成到加速卡芯片内部了。
这就涉及到了 PLX 的作用:
- 位于 Host 端-PCIe 扩展桥接,用于扩展 PCIe 通道数量,以支持更多的外部设备。
- 位于 Device 端-板卡端的 DMA 控制,用于管理板卡与主机之间的数据传输,尤其是 DMA(Direct Memory Access) 操作。
南桥芯片组
PCIe 高频总线,主板做多层(多层 PCB)提供支持
PCIe 直接连接在 CPU 的PCIe 控制器上,从而做到超低延迟:

因为外围数量众多,不可能全部都直接同 CPU 进行交互,因此存在一个南桥芯片组,一些非极其重要的设备先和南桥交互,由南桥将数据或请求汇总好后再统一交由 CPU 处理(下图中红色表示和 CPU 直连的设备)
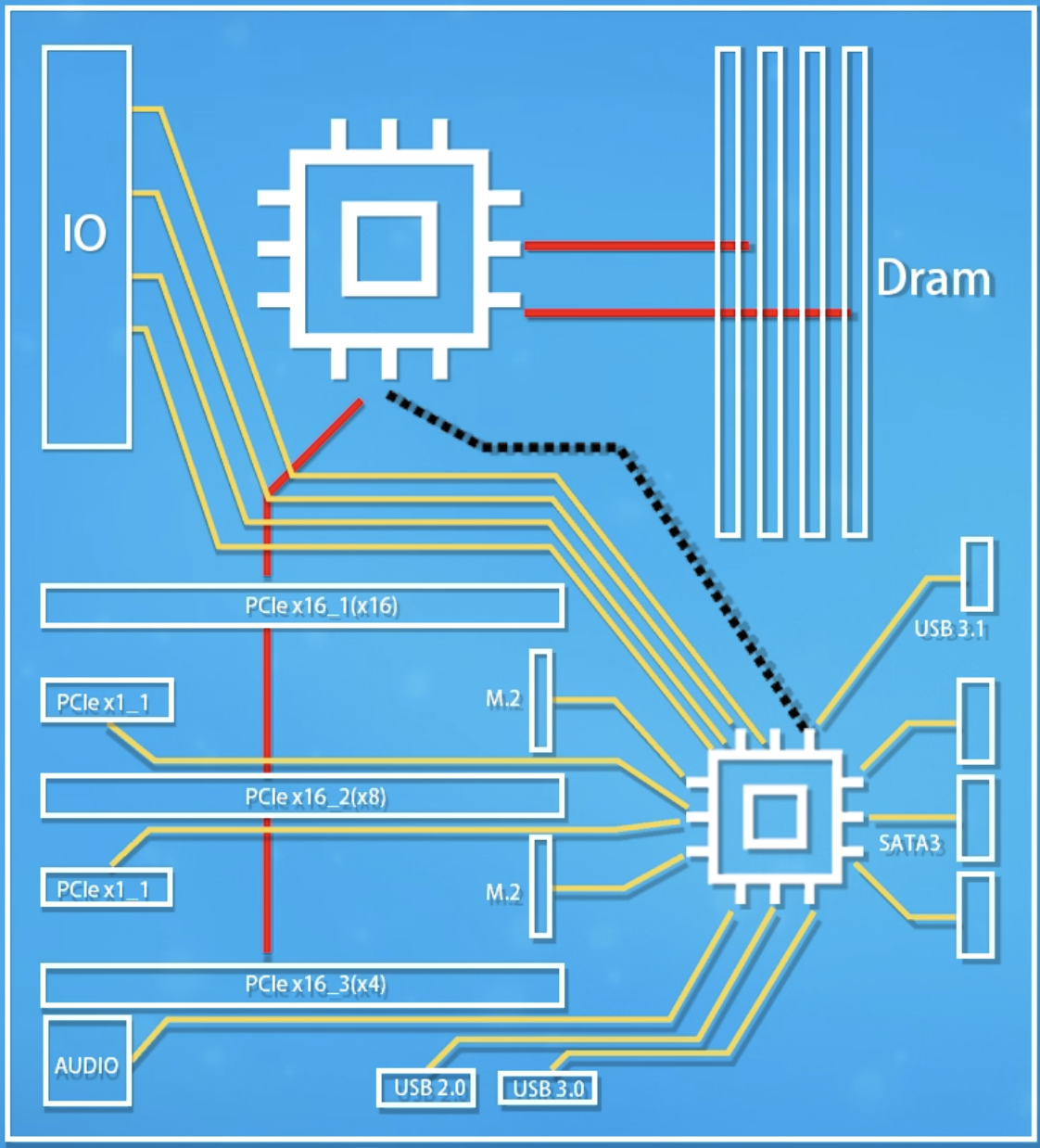
关于带宽的分配问题:
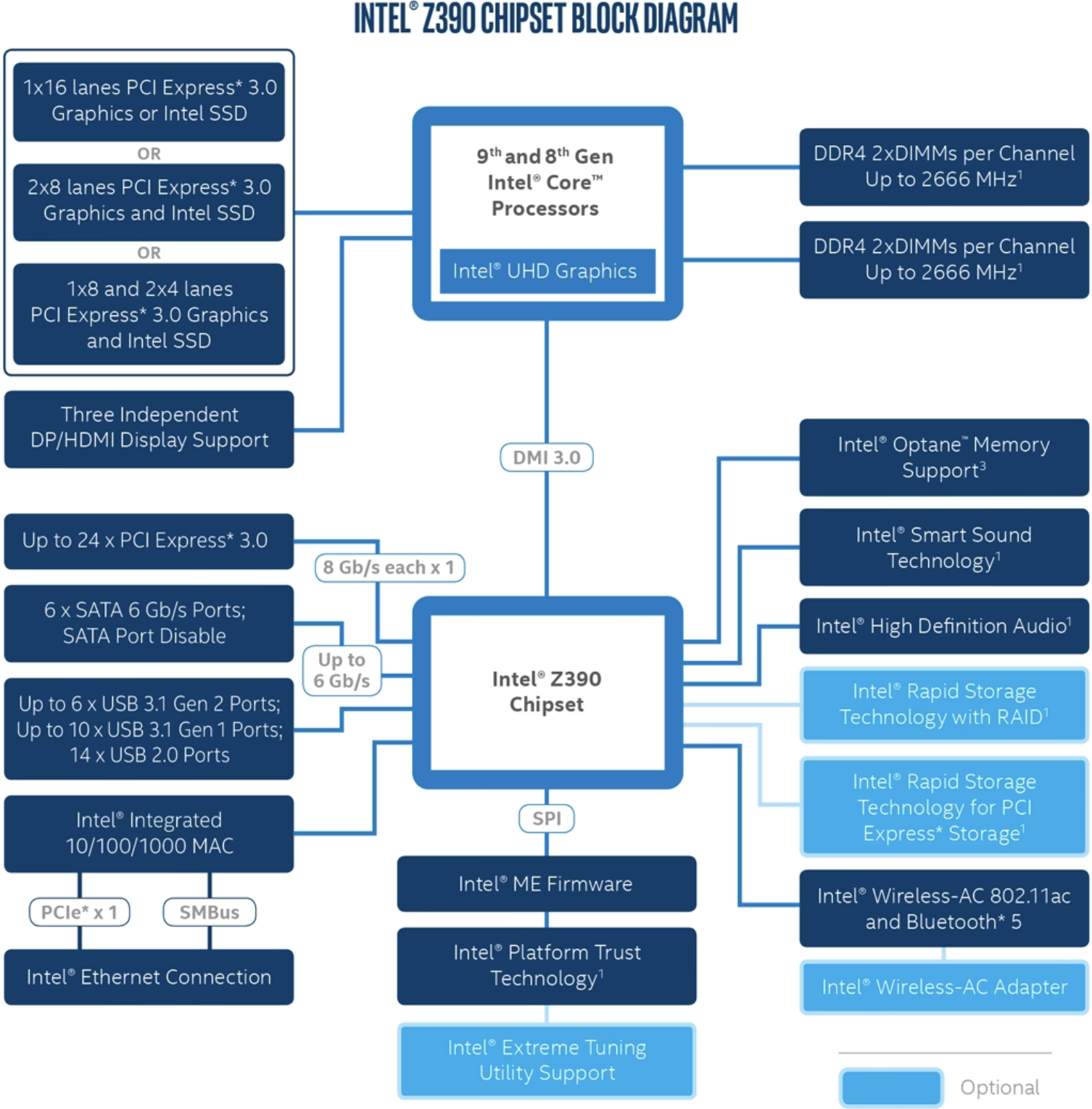
有这样一个问题:如果在上述 Intel Z390 平台主板上同时插入了显卡( PCIe x16 )和 m2 固态硬盘( PCIe x4 ),那么是否意味着两个设备是共享或者说抢占(注意左上角直连 PCIe 的几种选择之间是或的关系,即同时最大只有 x16 的带宽)和 CPU 直连的那 x16 的 PCIe 通道?
答案是不会,因为 m2 固态用的是和南桥连接的非直连 PCIe 总线上的
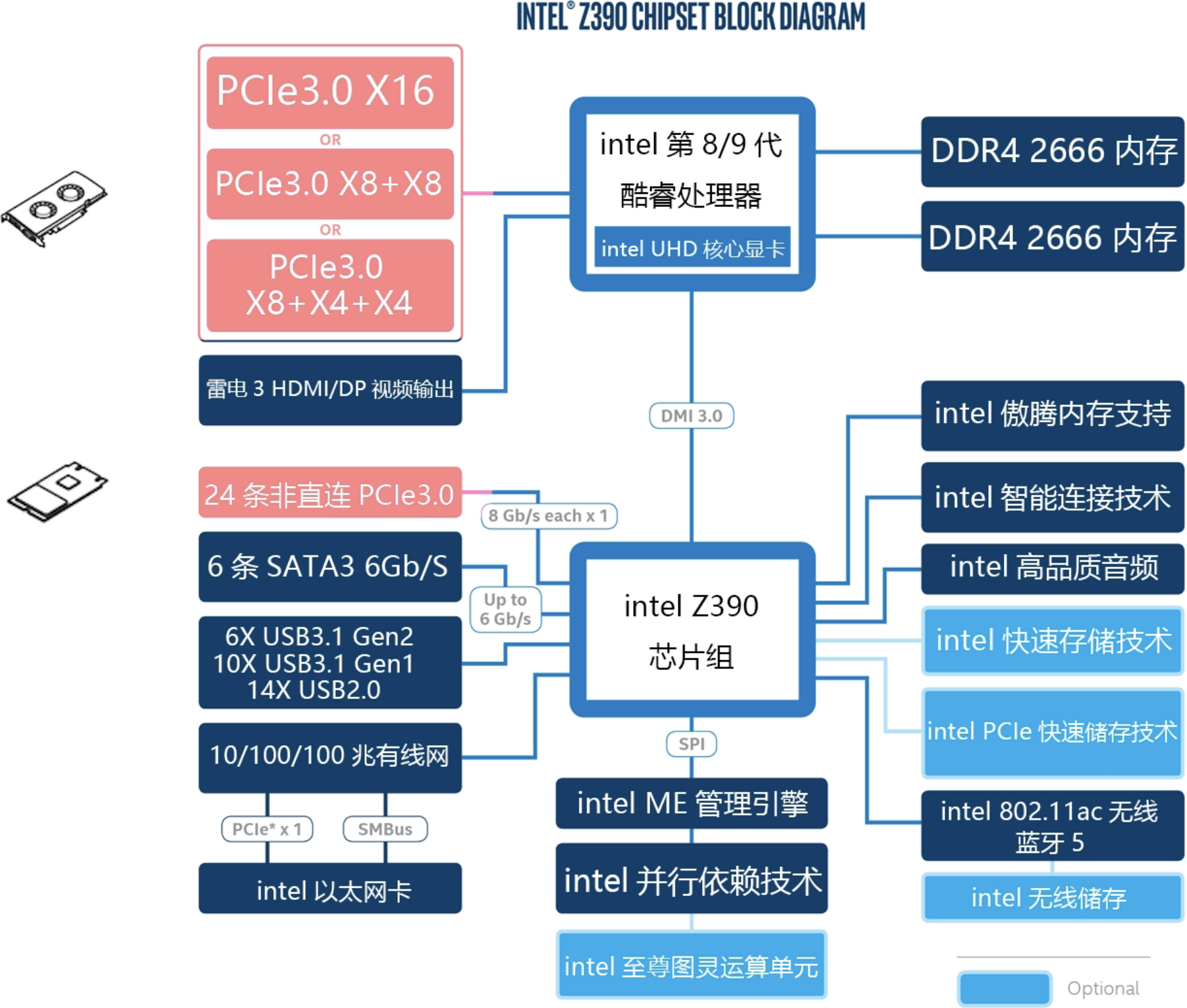
而在 AMD Ryzen 平台,提供了 20 条直连 PCIe 通道,其中 x16 可以分配给显卡,另外 x4 则可以分配给 m2,此时相当于二者共享这 20 条通道。
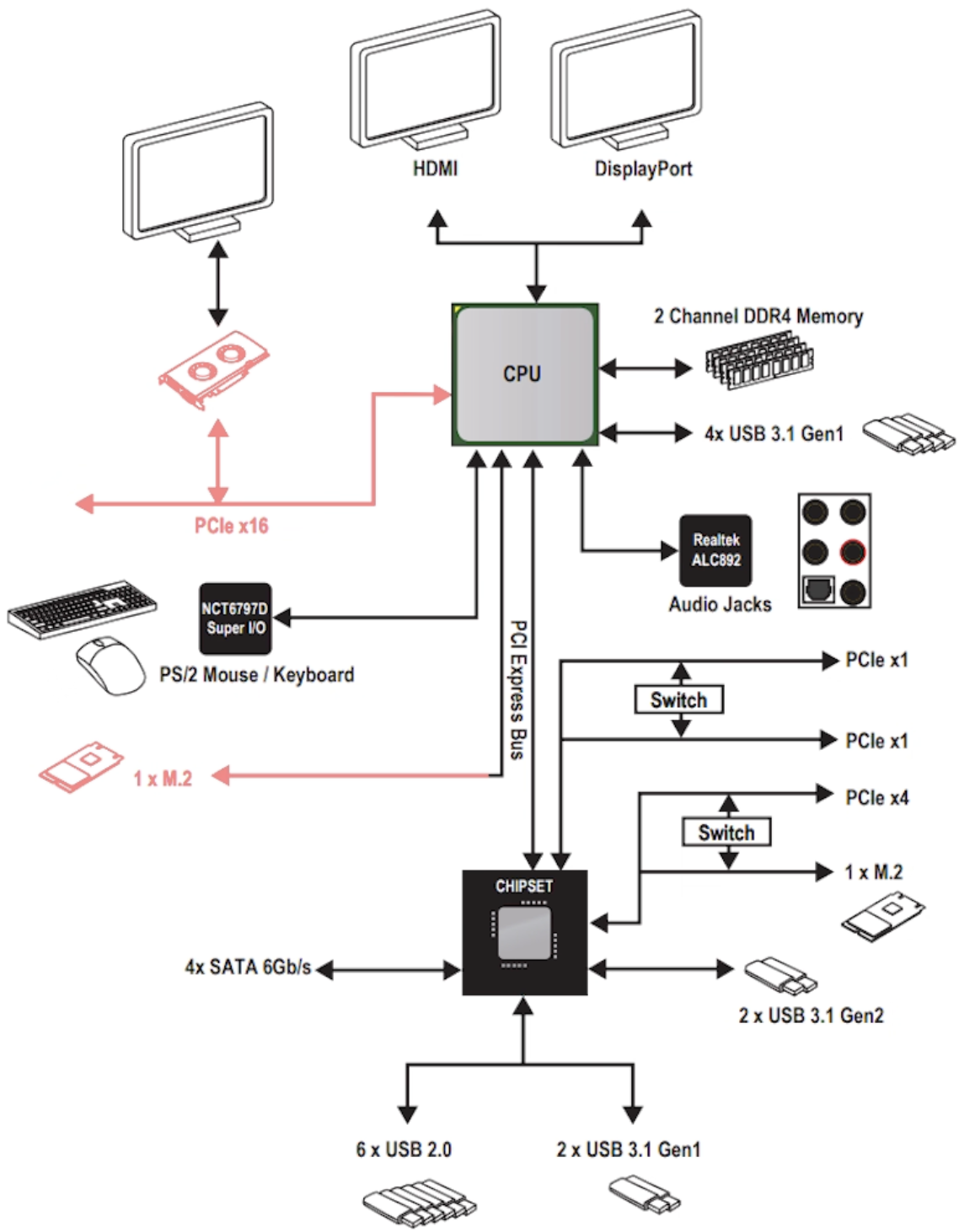
而南桥芯片组和 CPU 的连接是通过 PCIe 3.0x4,在 Intel 下,将其称之为 DMI 3.0,AMD 则直接标注了 PCIe。
PCI 设备
在为 PCI 设备安装驱动之前,在系统的 /sys/bus/pci/devices/ 路径下就能看到设备对应的文件夹,这是如何做到的?
本质原因在于硬件和软件均遵循了预先定义好的 PCI 标准,硬件方面,每个设备都有一个标准的 PCI 配置空间(一些寄存器),其中包含 Vendor ID 和 Device ID 等关键信息;软件方面,Linux 内核包含一个 PCI 子系统,那么 PCI 子系统可以通过总线读取这些寄存器中的值,从而即使在没有驱动程序的支持下也依然能够获取到设备的基础信息。
PCI 配置空间
PCI 规范决定了,在 PCI 设备的配置空间中,一个字(word)的长度固定为 16 位,无论操作系统是 32 位还是 64 位。
PLX Driver
Linux kernel 提供了对于 pci device 的支持的,内核代码中包含一些 PCI 设备结构体以及一些注册函数,例如
driver information struct:
| |
register function:
| |
The above content is used to mount the driver to the kernel, mount 操作完成的只是让内核能够看到挂载的驱动模块的一些基本信息,但是驱动模块具体负责做什么在上面的内容中并没有说明,所以接下来还需要对这些内容进行说明。
定义驱动程序的行为和资源管理方式
| |
从 file_operations 进一步理解 Linux “everything is a file” 的理念。
file_operations 为内核代码中提供的结构体,驱动程序所做的事情即为该结构体中所预留的函数指针指定一个驱动程序所实现的函数,例如:pGbl_DriverObject->DispatchTable.read = Dispatch_read;, 而 Dispatch_read 是驱动程序所实现的一个函数。当驱动挂载至内核后,我们对于设备的读请求就等价于对于读文件。
At the same time, we can also know that 设备驱动的源代码包含的除了一些驱动注册的代码之外,最主要的就是完成 file_operations 中所包含的函数,以此给上层提供文件模式的设备访问控制方法。
| |